Key takeaways:
- Browser automation doesn't scale linearly. At 1,000+ sessions, browsers behave less like workers and more like long-lived systems that require active lifecycle and resource management.
- Self-hosting browsers shifts engineering effort toward operations. Pool management, recycling, monitoring, and recovery quickly become ongoing platform work rather than a one-time setup.
- Managed browser infrastructure removes scale as a constraint. Teams keep the same Playwright or Puppeteer code while offloading concurrency, stability, and debugging concerns to platforms like Browserless.
Introduction
Alternative data has become a standard input for modern investment research, not an edge case. Hedge funds, asset managers, and fintech teams increasingly look beyond traditional reports to capture earlier, more granular signals about how businesses are actually performing. Public web data plays a major role in that shift, offering timely insight into pricing, demand, hiring trends, and operational activity as they change. In this article, we frame web scraping as a legitimate, compliance-aware way to build financial-grade alternative data pipelines that support serious research and decision-making.
Understanding Alternative Data in Finance

What Alternative Data Means in Practice
When people talk about alternative data in finance, they're usually describing information that shows what a business is doing right now, not what it reported weeks or months later.
Traditional financial statements and market feeds are structured, standardized, and reliable, but they're also periodic. Alternative data fills the space between reporting cycles by capturing activity as it unfolds in the real world, often at a much higher frequency.
That immediacy is why these datasets matter. They offer earlier signals, finer-grained changes, and a closer connection to operational reality. Used well, alternative data doesn't replace fundamental or quantitative analysis; it strengthens both.
Financials provide the baseline, while alternative signals help explain why numbers are moving and whether trends are likely to persist. As adoption has grown across the buy side, expectations have risen too; today's alternative data needs to be consistent, well-documented, and suitable for repeatable research, not exploratory one-offs.
Common Signals Derived from Public Web Data
Many of the signals investors care about are already publicly available, just not in a tabular feed. Job postings are a good example. Tracking hiring volume, role types, or geographic distribution over time can reveal expansion plans, cost controls, or strategic shifts well before they appear in earnings commentary.
Similarly, pricing pages and product listings often reflect changes in demand, competitive pressure, or early inflation signals as companies adjust in near real time. Customer reviews and sentiment data add another layer, offering insight into product quality, customer satisfaction, and brand perception when measured consistently.
On the operational side, inventory availability, shipping notices, and logistics updates can signal supply chain strength or emerging constraints. When collected thoughtfully and interpreted in context, these web-derived signals become practical inputs for investment research, helping teams move from raw activity to informed analysis.
Why Web Scraping Powers Modern Alt Data
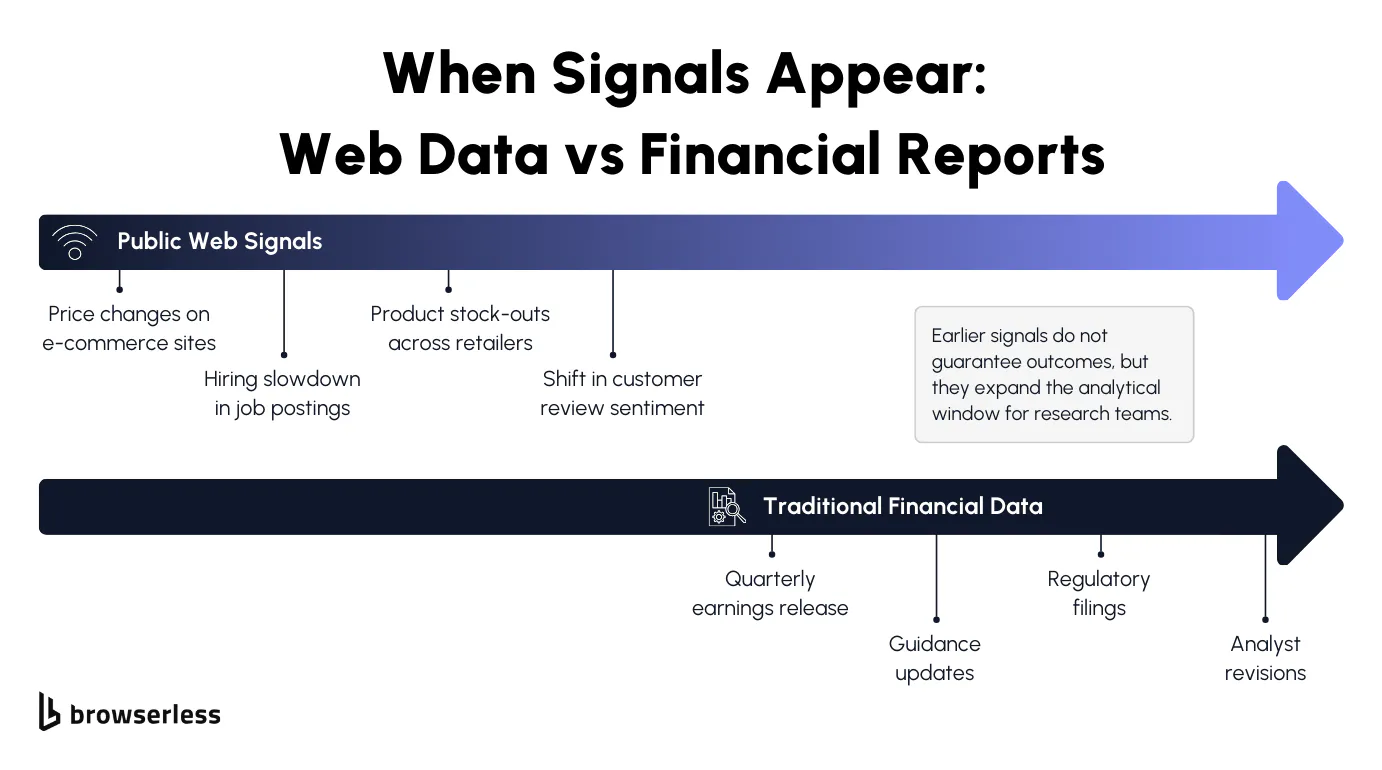
The Public Web as an Early Information Source
Many of the signals investors care about appear online long before they show up in earnings reports, filings, or third-party datasets. Companies update websites continuously, adjusting prices, changing product availability, posting new roles, or modifying messaging in response to real business conditions. Those changes often reflect internal decisions that haven't yet been formalized or disclosed elsewhere.
Because websites update in near-real time, web data tends to serve as a leading indicator rather than a summary of past performance. Pricing changes can reflect shifts in demand or cost pressure as they happen.
Hiring pages can reveal expansion plans or slowdowns weeks or months ahead of reported headcount changes. When tracked consistently, these signals give researchers a clearer view of how a business behaves between reporting cycles.
Why Firms Build Instead of Buying Data
Off-the-shelf alternative datasets can be useful, but they come with tradeoffs that matter in investment research. Latency is a common issue; data may be days or weeks old by the time it's delivered. Schemas are fixed, coverage is generalized, and updates are designed to serve many customers rather than a specific investment thesis.
That makes it hard to adapt when research questions change. Custom web scraping offers greater control. Teams can collect exactly the signals they care about, at the frequency they need, and adjust scope as hypotheses evolve.
If a new metric becomes relevant or a company changes how it presents information, the pipeline can evolve alongside the research. That flexibility is a major reason many firms treat web scraping not as a stopgap, but as a core capability within their alternative data strategy.
Technical Requirements for Financial-Grade Pipelines
Reliability, Scale, and Data Integrity
Investment research depends on data that is consistent and repeatable over time. A signal is only useful if it can be trusted week after week, not just when it happens to scrape cleanly.
That means collection jobs need to run on a predictable cadence, produce stable outputs, and fail loudly when anything changes, rather than silently drifting. In finance, gaps or inconsistencies don't just reduce confidence in a dataset they can invalidate entire lines of analysis.
Scale adds another layer of complexity. Monitoring thousands of companies, SKUs, or pages turns small issues into systemic ones. A minor layout change or intermittent site failure can ripple through a pipeline if it isn't caught early.
That's why validation, normalization, and anomaly detection matter before data ever reaches a research notebook or model. These steps help distinguish real-world changes from collection noise, keeping analysts focused on signals rather than on cleanup.
Compliance, Risk, and Operational Constraints
Financial data pipelines also face greater scrutiny than most scraping workloads. Teams need to know where data came from, when it was collected, and how it was transformed, often months or years later.
Clear provenance and traceability support internal review, client questions, and regulatory inquiries without forcing engineers to reconstruct history after the fact. Regulatory awareness also plays a role. Even when working with public data, teams need to consider frameworks such as GDPR and CCPA and avoid collecting or retaining information that poses unnecessary risk.
On top of that, many financial and e-commerce sites use aggressive bot detection and access controls, which can disrupt data collection if not handled thoughtfully. Infrastructure choices directly affect both data quality and operational risk. Unstable setups lead to missed updates, blocked access, and inconsistent datasets, all of which undermine the reliability on which financial research depends.
Architecture and Governance for Production Use

Designing Production-Ready Alt Data Pipelines
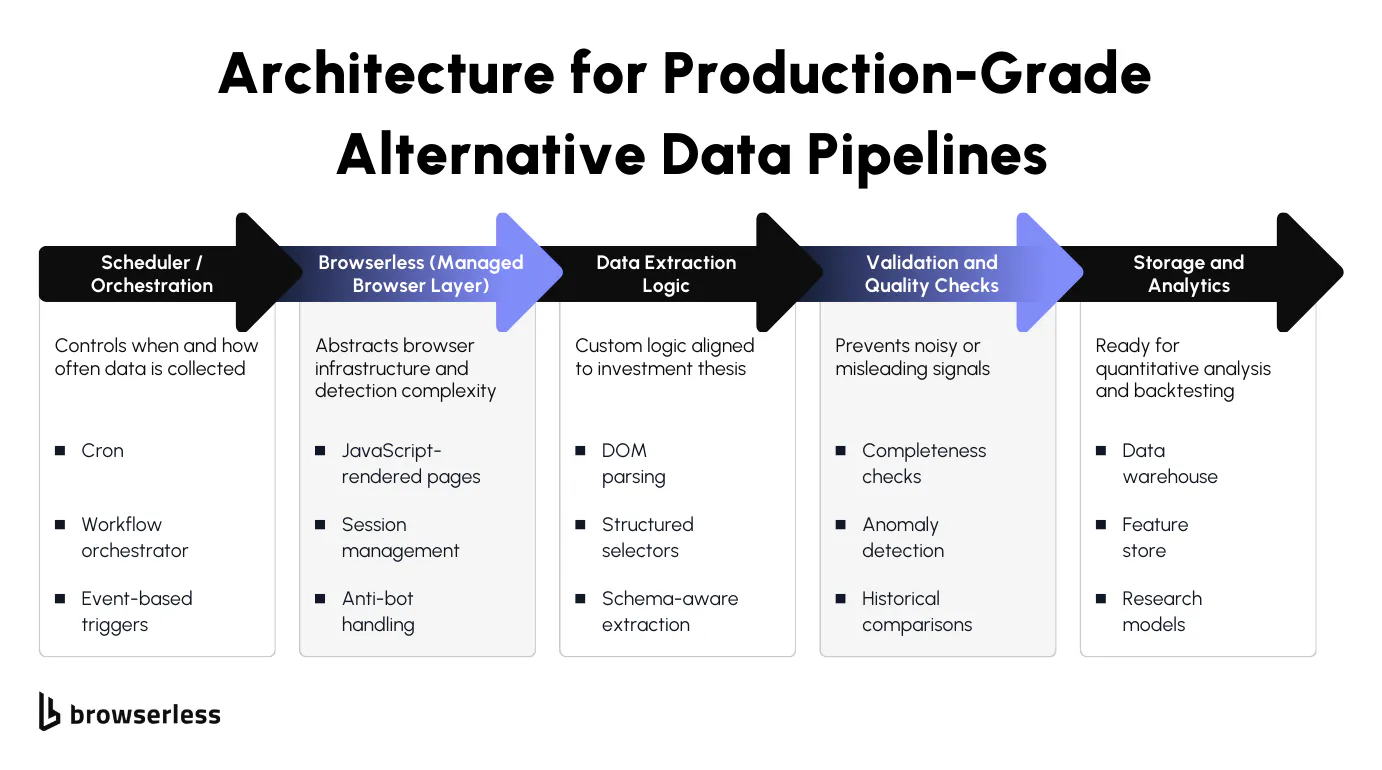
As alternative data moves from experimentation into daily research workflows, pipeline design matters as much as the signals themselves. In practice, most production setups follow a clear flow: scheduled collection jobs trigger browser-based access to target sites, data is extracted and validated, and it is stored only after validation for downstream analysis.
Each stage serves a purpose, and keeping those responsibilities separate makes the system easier to reason about when something changes. Browser-based collection is increasingly necessary because many modern websites rely on JavaScript rendering, dynamic content loading, and authenticated sessions.
Simple HTTP requests often miss large parts of the data or return incomplete views. Separating extraction logic from browser and session management helps keep things stable over time. Analysts and data engineers can focus on what data to collect and how to interpret it, while the browser layer handles rendering, sessions, and access mechanics without leaking that complexity into research code.
Ethics, Compliance, and Enterprise Readiness
Alternative data production pipelines also need clear boundaries. Collecting public data and respecting site policies helps reduce legal and reputational risk, especially in regulated environments.
Just as important is avoiding the collection of personally identifiable information, which can create compliance obligations that far outweigh the value of the data. Being explicit about what is collected and what is intentionally excluded keeps datasets safer to use and easier to defend.
Enterprise readiness goes beyond collection practices. Documented processes, access controls, and audit-friendly workflows matter when data is used to support investment decisions.
Financial institutions often need to demonstrate how data was sourced, handled, and protected over time. Infrastructure aligned with standards such as SOC 2 supports those requirements by providing a foundation of operational controls, helping teams meet internal governance expectations without slowing research or development.
Conclusion
Web scraping has become a standard, defensible source of alternative data for investment research. The challenge today isn't access, but collecting data reliably, ethically, and at scale while meeting regulatory and operational expectations. Financial teams see the most value when data logic is decoupled from infrastructure, allowing research workflows to evolve without constant operational rework. A compliance-first, enterprise-grade approach turns alternative data into a dependable input for investment decisions. Sign up for a free trial to get started.
FAQs
What is alternative data in finance?
Alternative data refers to non-traditional data sources used alongside financial statements and market feeds to better understand business activity in real time. Examples include web-based signals such as pricing changes, job postings, reviews, and inventory availability that reflect operational behavior between reporting cycles.
How is web scraping used for investment research?
Web scraping is used to collect public data from websites that reflect pricing, demand, hiring, sentiment, and supply chain activity. When collected consistently and validated, this data can act as an early signal for trends that may later appear in earnings reports or disclosures.
Why do hedge funds and asset managers use alternative data?
Hedge funds and asset managers use alternative data to gain earlier, more granular insight into company performance and market dynamics. These signals help explain movements in traditional metrics and support research that relies on timeliness, frequency, and operational context.
What are the main challenges of building financial-grade web data pipelines?
The main challenges include maintaining reliability at scale, handling frequent site changes, managing bot detection, and meeting compliance requirements. Financial-grade pipelines also require strong data validation, clear provenance, and repeatable collection processes to support confident research decisions.
How can web scraping be done in a compliant and enterprise-ready way?
Compliant web scraping focuses on collecting public data, respecting site policies, avoiding personally identifiable information, and maintaining audit-ready documentation. Using managed infrastructure like Browserless helps teams separate data logic from browser operations while supporting governance and scalability.