
What was the goal of your automation?
Dropdeck is all about helping people create slide decks quickly without feeling like they have to be a designer. So a key use case for us is being able to export their content to other formats, such as PDF.
What were the results?
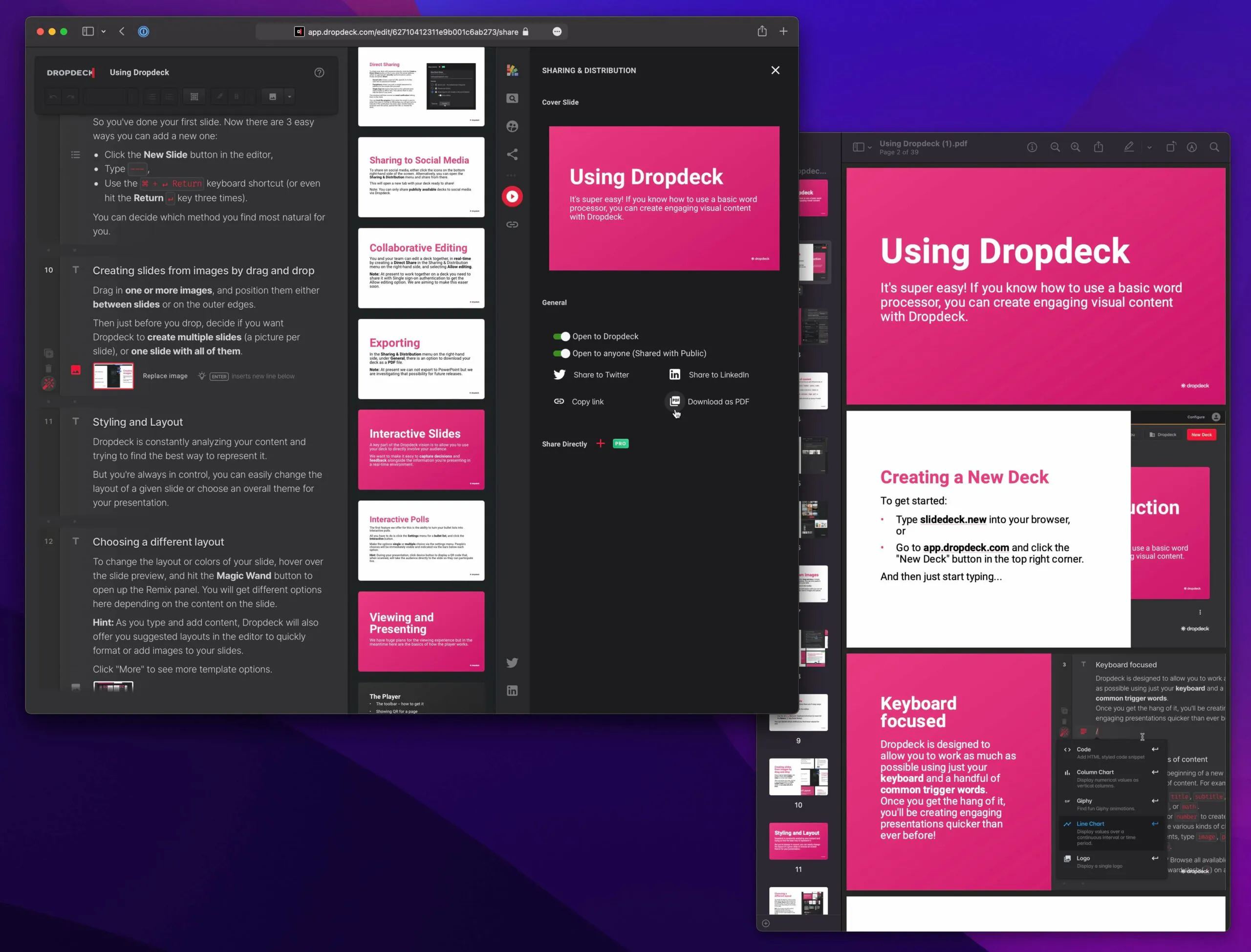
With the export automation in place, our users are now able to create a PDF of their slide deck, with the exact styling and formatting they see on their screen.
To achieve this, we created a variation of our slide player which removes any of the surrounding chrome of the UI, and lists the slides out in semantic HTML with markup for page breaks and such. This allows us to get an exact page fit when generating the PDF with Puppeteer. As an example, you can check out this slide deck and the corresponding PDF version.

In fact, you can try it out for yourself, without even signing up! Just go to dropdeck.com, add some content and then export to PDF via the menu on the right.
Why did you choose Browserless for automation?
Our customers use Dropdeck to generate rich visual documents and presentations, which typically include interactive elements or embedded web content such as videos, Figma files or real-time charts.
In many cases, however, one might need a static version of a presentation, for offline distribution or printing, for example. By using Puppeteer with Browserless we can faithfully translate a slide deck as a PDF that respects the detailed design of each page.
The Browserless service has allowed us to focus on our core product and value, and delegate the operation and scaling of the Puppeteer process to a dedicated service, which has run pretty much hands-off since we set it up. We even use the same service architecture to generate other static assets, such as PNG thumbnails, and we hope to add more export options in the coming months; for example, allowing users to download individual slides as images, or export a set of slides to social media.
/*
* The `generatePdf` snippet below illustrates the main steps of our export process.
* This function takes the ID of a slide deck, along with optional size parameters,
* and the stream of HTTP cookies of the client that originated the request.
* These are forwarded by Puppeteer to the endpoint that renders the slide deck,
* to respect any authorization of web assets that may be necessary for rendering.
*/
// We assume browserlessUrl and browserlessToken are config parameters
const browserlessEndpoint =
`${browserlessUrl}?token=${browserlessToken}` +
"&--no-sandbox=true" +
"&--disable-setuid-sandbox=true" +
"&--disable-dev-shm-usage=true" +
"&--disable-accelerated-2d-canvas=true" +
"&--disable-gpu=true";
const generatePdf = async ({ deckId, width = 800, height = 500, cookies = [] }) => {
const url = getUrlForDeck(deckId);
const fileName = `${deckId}.pdf`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserlessEndpoint,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
// We forward cookies from the client that originated the request, for authorization.
await page.setCookie(...cookies);
try {
// Waiting until networkidle0 ensures we only take action once the network is idle
// (no requests for 500ms).
await page.goto(url, { waitUntil: "networkidle0" });
// The page's JavaScript has likely produced markup by this point, but we may need to wait
// further if the site performs lazy fetching of data, for example. In this case, we wait for
// the window.isReady flag to have been turned on.
await page.waitForFunction("window.isReady === true");
// Set the viewport size and emulate screen media.
await page.emulateMedia("screen");
await page.setViewport({ width, height });
// Now the page has been rendered, so we proceed to stream it to PDF.
const pdf = await page.pdf({
path: fileName,
width,
height,
preferCSSPageSize: false,
printBackground: true,
});
await browser.disconnect();
return pdf;
} catch (err) {
// ...
}
};
How to get started with Browserless
There are different ways to use our product.
-
Use our online debugger to try it out!
-
Sign up for a free account and get an API key.
-
You can self-host for development purposes by using our OpenSource browserless docker image
-
If you’ve already tested our service and want a dedicated machine for your requests, you might be interested in signing up for a dedicated account, this works best if your doing screencasting or have a heavy load of requests since you won’t be sharing resources.
If you’re using one of our hosted services; be that usage-based or capacity-based, just connect to our WebSocket securely with your token to start web scraping!