How to Scrape Indeed.com With BrowserQL
Introduction
Indeed is one of the biggest job platforms out there, helping millions find jobs across all kinds of industries. It’s packed with job listings, company reviews, salaries, and detailed descriptions perfect for research, analytics, or competitive insights. Scraping this data can be super useful, but it does come with a few hurdles, like CAPTCHAs, dynamic content, and rate limits. In this article, you will learn how to get around these Scraping challenges.
Page Structure
When scraping Indeed.com, understanding the structure of its pages is important for extracting relevant data accurately. Let’s break down the site's layout into key sections, focusing on what can be extracted and where this information is located.
Use Cases for Scraping Indeed.com

Scraping Indeed provides significant opportunities to analyze job market trends, compare salaries, or streamline recruitment strategies. Scraping Indeed unlocks actionable insights whether you are a job seeker, employer, or data analyst.
Some common use cases for scraping Indeed include:
- Job Market Analysis: Understand hiring trends, skill demands, and industry market conditions.
- Competitor Insights: Evaluate competitor hiring practices and job postings for strategy optimization.
- Salary Comparisons: Extract salary ranges to benchmark compensation levels for roles in specific locations.
- Candidate Outreach: Identify companies actively hiring to tailor outreach efforts.
- Job Posting Optimization: Gather insights to craft postings that attract more qualified candidates.
What Data Can You Scrape from Indeed.com
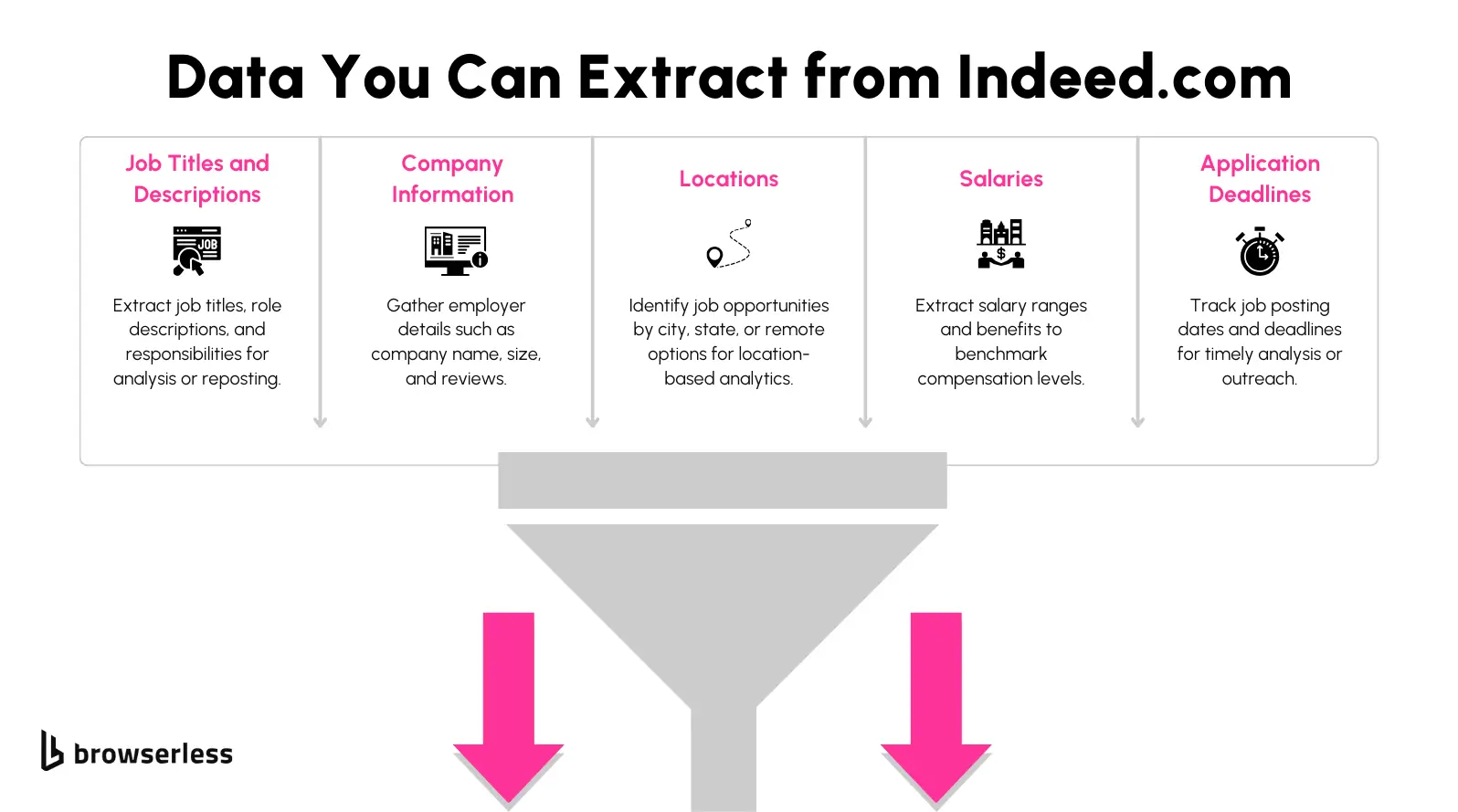
Indeed.com provides a wealth of information across its job search and job detail pages. The data you can extract helps refine recruitment strategies and decision-making.
Here’s an overview of what you can extract:
- Job Titles and Descriptions: Analyze role details and responsibilities for posting optimization or workforce planning.
- Company Information: Collect employer details, including size and reviews.
- Locations: Identify city and remote job opportunities for geographical analytics.
- Salaries: Extract salary ranges to understand market trends better.
- Application Deadlines: Track job posting dates to act quickly on opportunities.
Job Search Results Pages
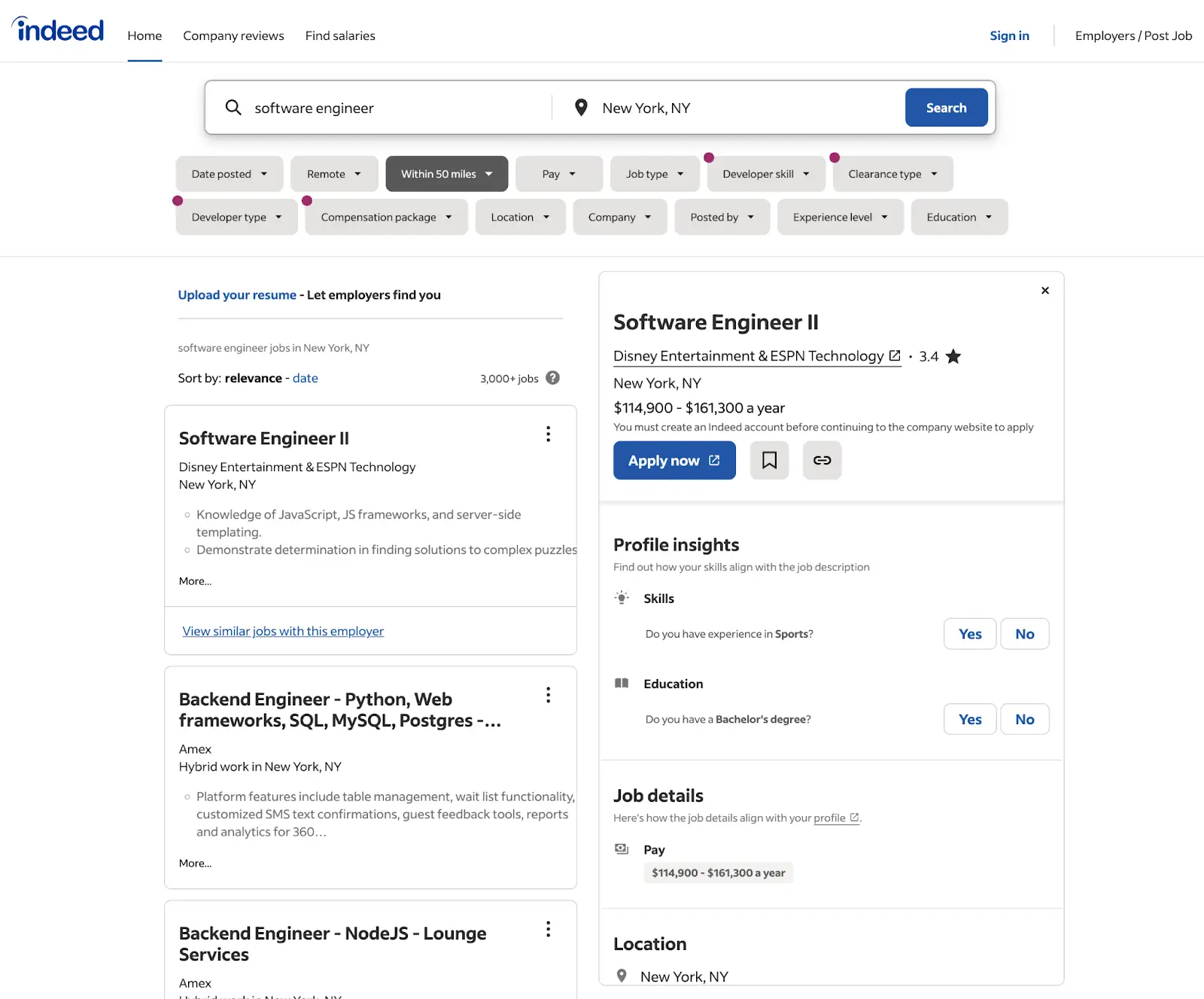
The job search results pages provide an overview of available positions based on a search query. These pages are designed with key data points displayed, making identifying and collecting relevant information straightforward.
Key Elements:
- Job Titles: Displayed prominently in each search result for immediate identification.
- Company Names: Includes the name of the hiring company or organization.
- Locations: Indicates where the job is based or if it is remote.
- Salaries: Shows salary ranges when available.
- Job Posting Dates: Tracks how recently the job was posted.
Job Detail Pages
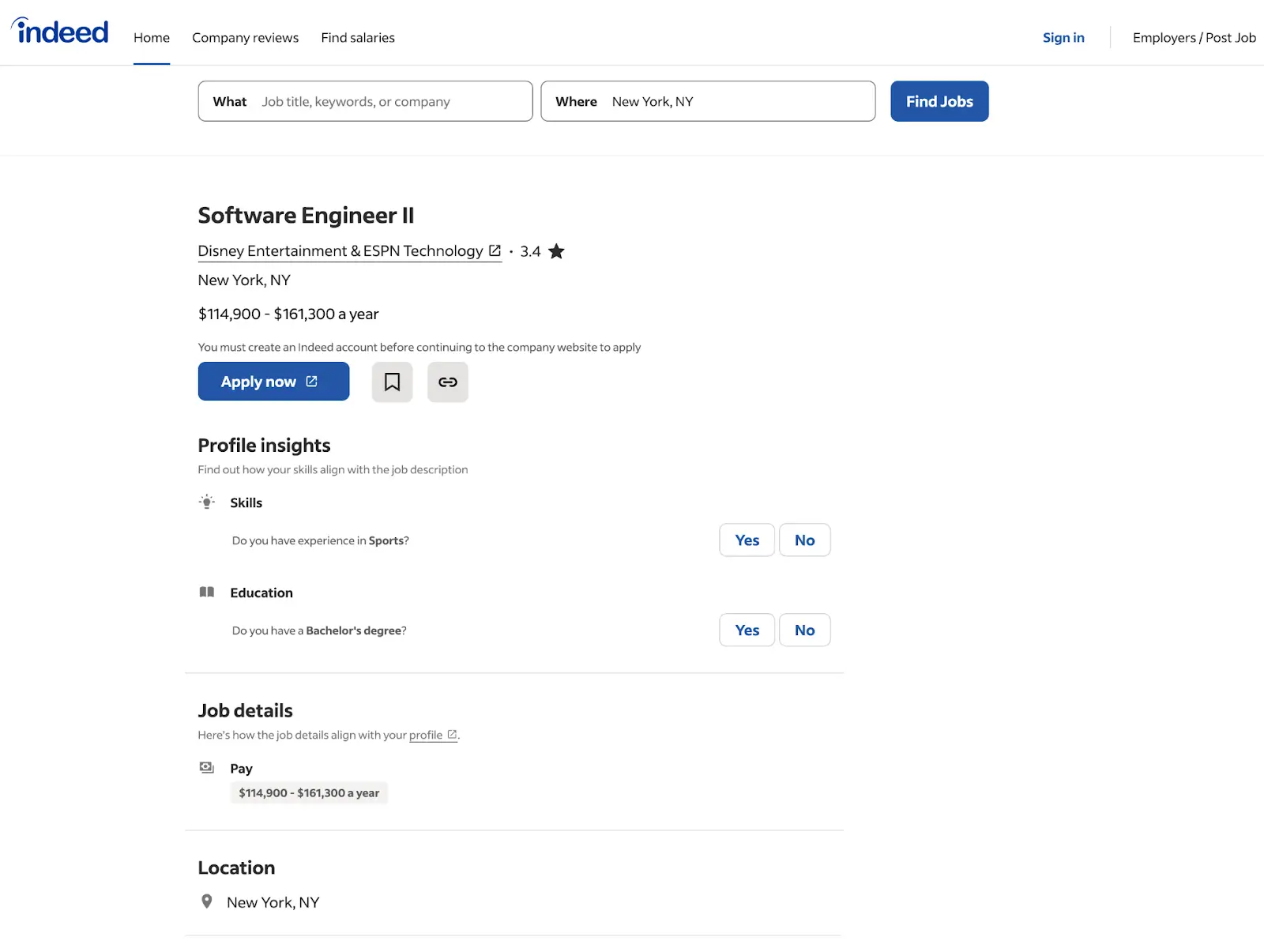
The job detail pages on Indeed provide deeper insights into each position, including the responsibilities, qualifications, and application requirements. These details are critical for understanding the nature of the job and evaluating it for applications or analysis.
Key Elements:
- Job Descriptions: Explains the responsibilities and daily tasks of the role.
- Qualifications: Lists educational and experience requirements.
- Application Instructions: Outlines how to apply for the job.
- Recruiter Contact Details: Sometimes includes recruiter or hiring manager information.
Puppeteer Tutorial
In this section, we’ll walk through the steps required to scrape job listings from Indeed.com using Puppeteer. We will create two scripts: one for extracting job URLs from a search results page and another for scraping details from the collected URLs.
Step 1 - Setting Up Your Environment
Before we get started, ensure you have the following ready:
- Node.js: Download and install Node.js from nodejs.org.
- Puppeteer: Puppeteer is a Node.js library that provides a high-level API to control headless Chrome browsers.
- Install Puppeteer by running:
npm install puppeteer
- Basic JavaScript Skills: Familiarity with JavaScript helps modify the scripts as needed.
We’ll hard-code a search query for this tutorial and write two scripts. The first script will collect job URLs from a search results page, and the second will scrape details from those URLs.
Step 2 - Collecting Job URLs from the Search Page
We’ll scrape job URLs from a search results page. Indeed, URLs are structured like this:
https://www.indeed.com/jobs?q={job+title}&l={city+name}%2C+{state+initials}
For this tutorial, we’ll hard-code a search URL. The script will collect job URLs from the search results page and save them to a CSV file.
import puppeteer from "puppeteer";
import fs from "fs/promises";
(async () => {
console.log("Scraping job URLs...");
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Set user agent to mimic a real browser
await page.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
);
// Open Indeed search results page
const searchUrl =
"https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY";
await page.goto(searchUrl, { waitUntil: "networkidle2" });
try {
// Wait for job title links to load
await page.waitForSelector("h2.jobTitle > a.jcs-JobTitle", { timeout: 30000 });
// Extract job URLs
const jobUrls = await page.evaluate(() => {
const links = Array.from(
document.querySelectorAll("h2.jobTitle > a.jcs-JobTitle"),
);
const baseUrl = "https://www.indeed.com";
return links.map((link) => {
const href = link.getAttribute("href");
return `${baseUrl}${href}`;
});
});
console.log(`Found ${jobUrls.length} job URLs.`);
if (jobUrls.length > 0) {
// Write job URLs to a CSV file
const csvContent = jobUrls.join("\n");
await fs.writeFile("indeed-job-urls.csv", csvContent);
console.log("Job URLs saved to indeed-job-urls.csv");
} else {
console.log("No job URLs found.");
}
} catch (error) {
console.error("Error while scraping job URLs:", error);
} finally {
await browser.close();
}
})();
- Launch Browser: Opens a headless browser instance using Puppeteer.
- Navigate to URL: Loads the search results page for "Software Engineer" in "New York, NY."
- Extract URLs: Captures all job URLs by selecting anchor tags with the
jcs-JobTitleclass. - Save to CSV: Writes the extracted URLs into a CSV file for further processing.
Step 3 - Scraping Job Details from the Collected URLs
Next, we’ll create a separate script to scrape job details, such as the title, company, salary, job description, and location, from the job URLs saved in the previous step.
import puppeteer from "puppeteer";
import fs from "fs/promises";
import path from "path";
(async () => {
console.log("Scraping job details...");
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Set user agent to mimic a real browser
await page.setUserAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
);
try {
// Read job URLs from CSV
const csvFilePath = path.resolve("indeed-job-urls.csv");
const csvContent = await fs.readFile(csvFilePath, "utf-8");
const jobUrls = csvContent.split("\n").filter((url) => url.trim() !== "");
console.log(`Found ${jobUrls.length} job URLs in the CSV.`);
if (jobUrls.length === 0) {
console.log("No job URLs to scrape.");
return;
}
const jobDetails = [];
for (const url of jobUrls) {
console.log(`Scraping details from: ${url}`);
try {
// Navigate to the job detail page
await page.goto(url, { waitUntil: "networkidle2", timeout: 30000 });
// Extract job details with robust error handling
const details = await page.evaluate(() => {
const getText = (selector) =>
document.querySelector(selector)?.innerText.trim() || "N/A";
const title = getText("h1.jobsearch-JobInfoHeader-title");
const company = getText('[data-testid="inlineHeader-companyName"]');
const location = getText('[data-testid="inlineHeader-companyLocation"]');
const salary = getText("#salaryInfoAndJobType");
const description = getText("#jobDescriptionText");
return { title, company, location, salary, description };
});
jobDetails.push({ ...details, url });
console.log(`Scraped: ${JSON.stringify(details)}`);
} catch (error) {
console.error(`Failed to scrape ${url}:`, error.message);
jobDetails.push({
title: "N/A",
company: "N/A",
location: "N/A",
salary: "N/A",
description: "N/A",
url,
});
}
}
// Write job details to a CSV file
const outputCsvPath = path.resolve("indeed-job-details.csv");
const csvHeaders = "Title,Company,Location,Salary,Description,URL\n";
const csvRows = jobDetails
.map(
({ title, company, location, salary, description, url }) =>
`"${title}","${company}","${location}","${salary}","${description.replace(/"/g, '""')}","${url}"`,
)
.join("\n");
await fs.writeFile(outputCsvPath, csvHeaders + csvRows);
console.log(`Job details saved to ${outputCsvPath}`);
} catch (error) {
console.error("Error while scraping job details:", error.message);
} finally {
await browser.close();
}
})();
- Read URLs: Reads the list of job URLs saved in
indeed-job-urls.csv. - Load Job Page: Navigates to each job page URL.
- Extract Data: Scrapes job title, company name, location, salary, and description using appropriate selectors.
- Save to CSV: Formats the scraped data and writes it into a CSV file for easy analysis.
These two scripts give you a foundation for scraping Indeed.com. You can expand or modify them to target additional data points or automate workflows. This works great if you just need to scrape a couple of records, but what happens when you try to scale up your scraping efforts? That’s what we will cover in the next section, where we explore challenges like rate limiting, CAPTCHAs, and strategies for scaling your scraping efficiently.
Scaling Limitations
So, we successfully scraped a few records from Indeed.com. However, what happens if you want to collect hundreds or even thousands of job postings? At this scale, scraping introduces new challenges requiring advanced strategies. The following are the most common obstacles you’ll face when scaling your scraping efforts.
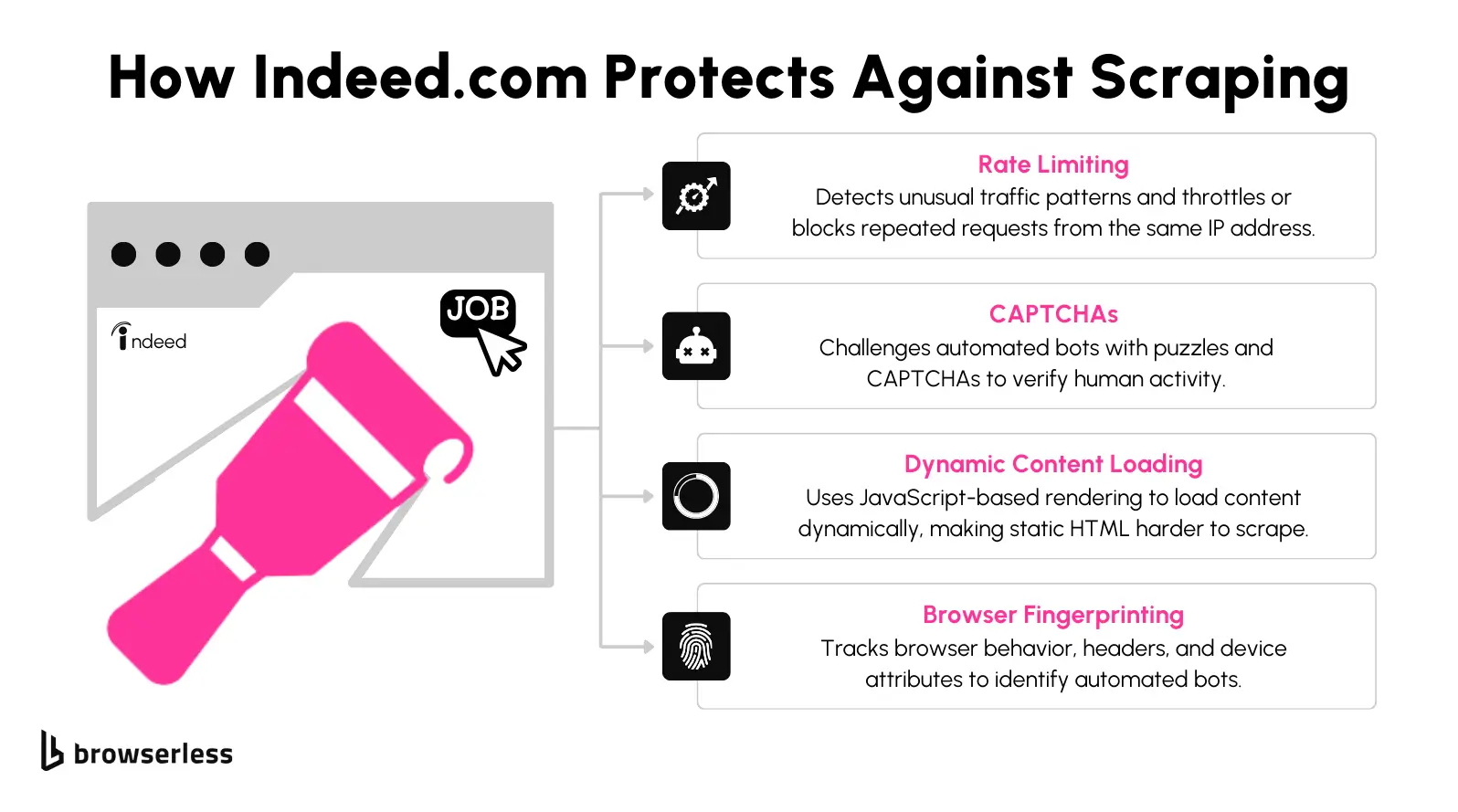
CAPTCHAs are Indeed's primary defense mechanism against automated scraping. You'll likely encounter these prompts when scraping multiple pages or making rapid requests. CAPTCHAs stop your scraper, demanding manual intervention or advanced solutions like automated solvers. Addressing CAPTCHAs at scale requires integrating external CAPTCHA-solving services or leveraging scraping tools designed to mimic human behavior more effectively.
Indeed.com has strict rate limits and IP monitoring to prevent excessive requests. If your scraper sends too many requests quickly, you avoid being temporarily or permanently blocked. Overcoming this limitation often requires strategies like rotating proxies, randomizing request intervals, or adopting more advanced tools that distribute requests across multiple IPs to avoid detection.
Many of Indeed’s pages rely on JavaScript to load dynamic content, such as salary information and detailed job descriptions. Traditional scraping methods that only fetch the raw HTML may miss these elements entirely. Extracting this content requires rendering the page in a headless browser or using tools capable of executing JavaScript to ensure all data is fully loaded before extraction.
Indeed.com also employs browser fingerprinting to detect automated scraping tools. This technique analyzes various browser attributes like user agent strings, screen resolution, and even installed plugins to identify and block non-human activity. To bypass browser fingerprinting, you need to configure your scraper to mimic real browser behavior carefully. This includes using tools that randomize browser fingerprints or employing headless browsers with realistic configurations.
How to Overcome Indeed.com Scraping Challenges
When using traditional tools like Puppeteer, tackling challenges like CAPTCHA triggers, rate limits, and dynamic content requires extensive configuration and manual adjustments. You may find yourself adding proxy rotations, integrating CAPTCHA-solving services, and scripting human-like interactions, which can quickly become time-consuming and complex. This is where a tool like BrowserQL can make a significant difference.

BrowserQL simplifies these tasks by offering advanced features designed specifically to handle modern web scraping challenges. To avoid detection, it simulates human-like behavior, including realistic browsing patterns and interactions.
Built-in CAPTCHA-solving capabilities eliminate the need for external services, saving time and reducing friction. BrowserQL also integrates proxy support directly into its configuration, allowing you to scale up your efforts without worrying about IP blocks or rate limits. These features make it a highly effective solution for scraping Indeed.com, even at scale.
Getting BrowserQL Setup
Sign Up for a Browserless Account and Obtain the API Key
The first step is creating a Browserless account to access BrowserQL. Once registered, log in to your account, navigate to the dashboard, and locate the section for API keys.
Copy your unique API key from this area, as you will need it to authenticate your requests. The dashboard provides a clear view of your usage statistics and account details, making it easy to track your activity.
Set Up the Development Environment
Next, set up your development environment with Node.js. Install the required packages, such as node-fetch for making API requests and cheerio for parsing the HTML output.
If you don’t already have Node.js installed, download it from the official website and ensure it is properly configured on your system. Use a package manager like npm to install the dependencies:
npm install node-fetch cheerio
These tools will enable your scripts to interact with the BrowserQL API and process the results.
Download the BrowserQL Editor
Download the BrowserQL Editor from your Browserless dashboard to simplify writing and testing your queries.
You will find it on the left navbar on your account page:
Caption: Navigate to the BrowserQL Editors section from your dashboard.
Click the "BrowserQL Editors" button to download the installation file tailored to your operating system. Once downloaded, follow the prompts to install the IDE with ease.
Caption: Download the BrowserQL Editor for your operating system.
This editor provides a user-friendly interface for crafting and validating your queries before running them in your application.
Test BrowserQL with a Basic Query
Before diving into detailed scraping tasks, it’s a good idea to test your BrowserQL setup with a simple query. Use the following code to load Indeed’s homepage and confirm that everything is working correctly:
import fetch from "node-fetch"; // To make API requests
import * as cheerio from "cheerio"; // To parse and extract data from HTML
import { createObjectCsvWriter } from "csv-writer"; // To save data into a CSV file
// BrowserQL API details and file paths
const BROWSERQL_URL = "https://chrome-eu-ams.browserless.io/chromium/bql"; // BrowserQL endpoint
const TOKEN = "Your-API-Key"; // Replace this with your BrowserQL API token
const SEARCH_URL =
"https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY"; // Indeed search URL
const OUTPUT_CSV = "indeed-job-urls.csv"; // Output file for saving job URLs
Run this query in the BrowserQL Editor or integrate it into your script. It should return the page's status and loading time, confirming that your API key and setup are functioning correctly.
Once this basic test is complete, you’ll be ready to start crafting more advanced queries to scrape data from Indeed.com.
Writing Our BrowserQL Script
Part 1: Collecting Job URLs from the Search Page
To collect job URLs from Indeed.com, we’ll use BrowserQL to fetch the HTML content of a search results page and Cheerio to parse and extract relevant job links. The extracted URLs will then be saved into a CSV file, which can be used for further scraping or analysis.
This clean process avoids manual intervention, which can be scaled for different job queries or locations. Let’s walk through each step together!
We’ll start by importing the required libraries and defining some constants. These include the BrowserQL API endpoint, the API token, and file paths for saving results.
const query = `
mutation FetchJobSearchPage {
goto(url: "${SEARCH_URL}", waitUntil: networkIdle) {
status
time
}
waitForTimeout(time: 3000) {
time
}
htmlContent: html(visible: true) {
html
}
}
`;
What’s Happening?
- BrowserQL URL: The API endpoint where we send scraping requests.
- API Token: Required to authenticate and run queries using BrowserQL.
- Search URL: The Indeed search page we want to scrape job links from.
- Output CSV: Specifies the file where extracted job URLs will be stored.
Here, we define the GraphQL query that will tell BrowserQL what to do. The query loads the Indeed search results page, waits for the content to load fully, and extracts the HTML. A short timeout is added to ensure all dynamic elements are rendered.
const query = `
mutation FetchJobSearchPage {
goto(url: "${SEARCH_URL}", waitUntil: networkIdle) {
status
time
}
waitForTimeout(time: 3000) {
time
}
htmlContent: html(visible: true) {
html
}
}
`;
What’s Happening?
- goto: Tells BrowserQL to navigate to the specified URL and wait until the network is idle. This ensures the page has fully loaded.
- waitForTimeout: Adds a short 3-second delay to handle any remaining dynamic content that may load asynchronously.
- htmlContent: Extracts the visible HTML content of the page, which we’ll parse later.
We send the query to BrowserQL and retrieve the page's HTML content. This step ensures we get the raw HTML, which we’ll clean up using Cheerio. If something goes wrong, error handling helps us understand the issue.
async function fetchHTMLFromBrowserQL() {
try {
console.log("Sending request to BrowserQL...");
const response = await fetch(`${BROWSERQL_URL}?token=${TOKEN}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }),
});
// Check for HTTP errors
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status} ${response.statusText}`);
}
const data = await response.json();
// Validate the response structure
if (!data?.data?.htmlContent?.html) {
console.error("Unexpected response structure:", JSON.stringify(data, null, 2));
return null;
}
console.log("HTML successfully retrieved!");
return data.data.htmlContent.html;
} catch (error) {
console.error("Error fetching HTML content:", error.message);
return null;
}
}
What’s Happening?
- API Request: The query is sent to the BrowserQL API to fetch the page HTML.
- Error Handling: Catches issues like invalid responses or network errors and logs them clearly.
- Validation: Ensures the returned data contains valid HTML.
Once we have the HTML, we use Cheerio to parse it and extract job URLs. Cheerio makes it easy to traverse and manipulate HTML, similar to how you’d use jQuery in the browser.
function extractJobUrls(html) {
const $ = cheerio.load(html); // Load the HTML into Cheerio
const baseUrl = "https://www.indeed.com";
const urls = [];
// Find all job title links and construct absolute URLs
$("h2.jobTitle > a.jcs-JobTitle").each((_, element) => {
const href = $(element).attr("href");
if (href) {
urls.push(`${baseUrl}${href}`);
}
});
return urls;
}
What’s Happening?
- Cheerio: Loads the HTML and lets us select elements using CSS selectors.
- CSS Selector: Targets job links using
h2.jobTitle > a.jcs-JobTitle. - Absolute URLs: Constructs full URLs by appending the base domain to the extracted paths.
Finally, we save the extracted URLs into a CSV file using csv-writer. This step ensures you have a clean, organized output ready for further use.
(async () => {
console.log("Fetching search page HTML...");
const htmlContent = await fetchHTMLFromBrowserQL();
if (!htmlContent) {
console.error("Failed to retrieve search page HTML.");
return;
}
console.log("Extracting job URLs...");
const jobUrls = extractJobUrls(htmlContent);
console.log(`Found ${jobUrls.length} job URLs.`);
if (jobUrls.length > 0) {
// Write URLs to CSV
const csvWriter = createObjectCsvWriter({
path: OUTPUT_CSV,
header: [{ id: "url", title: "Job URL" }],
});
await csvWriter.writeRecords(jobUrls.map((url) => ({ url })));
console.log(`Job URLs saved to ${OUTPUT_CSV}`);
} else {
console.warn("No job URLs found. Check your selectors or search URL.");
}
})();
What's Happening?
- Fetch HTML: We call the BrowserQL query to retrieve the page content.
- Extract URLs: Cheerio parses the HTML and extracts job links.
- Save to CSV: The
csv-writerlibrary writes the URLs into a structured CSV file.
When you run the script, you’ll get a CSV file named indeed-job-urls.csv with all the extracted job URLs. Here's an example of what the output might look like:
Job URL
https://www.indeed.com/viewjob?jk=abc123
https://www.indeed.com/viewjob?jk=def456
https://www.indeed.com/viewjob?jk=ghi789
Now that we have collected the URL, next it to scrape the info from the page, which we will do in the next section.
Part 2: Extracting Job Details
Now that we have all the job URLs nicely lined up, it’s time to dig deeper! In this part, we’ll scrape each job page to extract details like the job title, company name, location, salary, and description.
Step 1: Set Up API Configuration
Before diving into the actual scraping process, we need to set up the constants and API configurations that will allow our script to connect to the BrowserQL API. This step ensures we have the necessary details ready for smooth execution.
API Configuration and Imports
import fetch from "node-fetch"; // For API requests
import * as cheerio from "cheerio"; // For parsing HTML
import { createObjectCsvWriter } from "csv-writer"; // For writing CSV files
import fs from "fs/promises"; // For saving debug files
const BROWSERQL_URL = "https://chrome-eu-ams.browserless.io/chromium/bql"; // BrowserQL endpoint
const TOKEN = "your-api-key-here"; // Replace this with your actual BrowserQL API key
const INPUT_CSV = "job_urls.csv"; // Path to input CSV with job URLs
const OUTPUT_CSV = "job_details.csv"; // Path to output CSV for job details
What’s Happening?
BROWSERQL_URL: This is the API endpoint provided by BrowserQL to send our queries.TOKEN: Replace"your-api-key-here"with your actual API key from BrowserQL. This is required to authenticate and use their API.INPUT_CSV: The input file where job URLs are stored. This will be read to extract individual job page links.OUTPUT_CSV: The output file where parsed job details like title, company, location, and salary will be saved.
Step 2: Read Job URLs from a CSV
First things first, we’ll grab the job URLs from the input CSV file. We’re using csv-parser here to read the file efficiently and ensure we only process valid links.
// Constants
const INPUT_CSV = "job_urls.csv"; // Input CSV file with job URLs
const OUTPUT_CSV = "job_details.csv"; // Output CSV for job details
// Function to read job URLs from the CSV
const readJobUrls = async (filePath) => {
const urls = [];
return new Promise((resolve, reject) => {
fs.createReadStream(filePath)
.pipe(csvParser()) // Read CSV file row by row
.on("data", (row) => {
if (row["Job URL"]) urls.push(row["Job URL"]); // Add valid URLs
})
.on("end", () => resolve(urls)) // Done reading
.on("error", (error) => reject(error)); // Handle errors
});
};
What’s Happening?
Here we’re reading each row from the CSV file and collecting only valid job URLs into an array. This array will serve as our to-do list of job pages to process. Simple and clean!
Step 3: Fetch HTML Content with BrowserQL
For each job URL, we’ll use BrowserQL to fetch the HTML content of the job page. This is like asking a browser to load the page and give us the full HTML so we can parse it later.
const fetchHtmlFromBrowserQL = async (url) => {
const query = `
mutation FetchJobDetails {
goto(url: "${url}", waitUntil: networkIdle) {
status
}
htmlContent: html(visible: true) {
html
}
}
`;
try {
const response = await fetch(`${BROWSERQL_URL}?token=${TOKEN}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }), // Send GraphQL query to BrowserQL
});
const data = await response.json();
return data?.data?.htmlContent?.html || null; // Return the HTML content
} catch (error) {
console.error(`Error fetching HTML for URL ${url}:`, error);
return null;
}
};
What’s Happening?
- We’re sending a request to BrowserQL with a GraphQL query that tells it to load the job page and return the HTML content.
- If anything goes wrong (like a network issue), the script will handle it gracefully and let us know.
Step 4: Parse Job Details and Save to CSV
Here comes the fun part: we’ll load the HTML into Cheerio, a helpful tool for parsing HTML, and extract all the job details we need. After collecting the details, we’ll save everything to a new CSV file.
const parseJobDetails = (html, url) => {
const $ = cheerio.load(html); // Load HTML into Cheerio
// Extract job details with consistent selectors
const title = $("h1.jobsearch-JobInfoHeader-title").text().trim() || "N/A";
const company =
$("[data-company-name='true'] a, [data-company-name='true'] span")
.text()
.trim() || "N/A";
const location =
$("[data-testid='inlineHeader-companyLocation'], #jobLocationText span")
.text()
.trim() || "N/A";
const salary = $("#salaryInfoAndJobType span").text().trim() || "N/A";
const description =
$("#jobDescriptionText, .jobsearch-JobComponent-description").text().trim() ||
"N/A";
return { title, company, location, salary, description, url };
};
// Save job details to CSV
const saveJobDetailsToCsv = async (data) => {
const csvWriter = createObjectCsvWriter({
path: OUTPUT_CSV,
header: [
{ id: "title", title: "Title" },
{ id: "company", title: "Company" },
{ id: "location", title: "Location" },
{ id: "salary", title: "Salary" },
{ id: "description", title: "Description" },
{ id: "url", title: "URL" },
],
});
await csvWriter.writeRecords(data); // Write everything to CSV
console.log(`Job details saved to ${OUTPUT_CSV}`);
};
// Main Process
(async () => {
const jobUrls = await readJobUrls(INPUT_CSV); // Get job URLs
const jobDetails = [];
for (const url of jobUrls) {
console.log(`Processing ${url}`);
const html = await fetchHtmlFromBrowserQL(url); // Fetch job page HTML
if (html) {
const details = parseJobDetails(html, url); // Parse job details
jobDetails.push(details); // Add details to the list
}
}
await saveJobDetailsToCsv(jobDetails); // Save all details to CSV
})();
What’s Happening?
- Parsing Job Details: We use Cheerio to grab the job title, company name, location, salary, and description using consistent HTML selectors. If any data is missing, we replace it with
"N/A". - Saving to CSV: The extracted details are structured neatly and saved into a CSV file. Each row represents one job.
- Looping Through Jobs: For each job URL, we fetch the HTML, parse it, and store the details – like a well-oiled machine!
Expected Output
After running the script, the output CSV file (job_details.csv) will look something like this:
- Title: The title of the job position.
- Company: The company offering the job.
- Location: The job location (remote or on-site).
- Salary: The salary range if available.
- Description: A summary of the job description.
- URL: The original URL where the job was posted.
Now you have a neatly organized file containing all the job details, ready for analysis, reporting, or whatever your next step might be.
Conclusion
Scraping data from Indeed doesn't have to be frustrating or overly technical. BrowserQL handles many of the tricky parts for you, whether bypassing CAPTCHAs, managing large-scale scraping, or dealing with dynamic content. It's a tool that saves time, reduces headaches, and helps you focus on analyzing the data rather than worrying about how to get it. If you're looking to collect valuable insights from platforms like Indeed, BrowserQL is worth a try. It simplifies the process and allows you to scale your efforts as needed. Ready to see it in action? Sign up for a free trial today and take your scraping projects to the next level!
FAQ
Is scraping Indeed legal?
Scraping data that’s publicly available on Indeed is usually okay, but it’s always a good idea to review their terms of service. Make sure your approach isn’t overly aggressive, like hammering their servers with excessive requests. Stick to ethical practices, and you’ll stay on the safe side.
What can I scrape from Indeed?
There’s a lot of valuable information you can extract from Indeed, like job listings, company names, salaries, reviews, and detailed job descriptions. Whether you’re analyzing trends, benchmarking salaries, or researching competitors, this data can be super useful.
How does BrowserQL handle CAPTCHA challenges?
BrowserQL is built to act like a human browser, making it much less likely to trigger CAPTCHAs. If one does pop up, no worries; BrowserQL has CAPTCHA-solving features that’ll keep things moving without you stepping in.
Can I scrape salary information from Indeed?
Absolutely. BrowserQL can pull salary data from job postings, even when it’s dynamically loaded. It’s a great way to get detailed insights without manually digging through job descriptions.
Does Indeed block automated scrapers?
Indeed has strong anti-scraping defenses, like tracking browser behaviors and request patterns. BrowserQL is built to bypass these hurdles using features like proxies, randomized behaviors, and human-like interactions. It’s specifically designed for situations like this.
Can I scrape job listings for multiple locations?
Yes! BrowserQL makes it easy to run dynamic searches and scrape job listings across different locations. Whether you’re looking for postings in specific cities, states, or even countries, BrowserQL handles it without breaking a sweat.