Introduction
AI web browsing agents are emerging, reshaping how teams extract data, automate tasks, and interact with the modern web. Startups like Skyvern, Browseruse, Browserbase, and Hyperbrowser push technical boundaries, creating agents that can think through pages, adapt in real time, and make mid-session decisions. These aren’t simple scrapers; they’re intelligent systems with reasoning capabilities. However, scaling these agents past prototypes remains a bottleneck while innovation accelerates. This article explores the emerging wave of AI-powered browsing, the builders leading it, and how Browserless enables these systems to run at production scale.
The Rise of AI Web Browsing Agents (and Why They Matter Now)
Early web scraping was pretty straightforward. You’d use requests and BeautifulSoup to fetch and parse static HTML. That worked fine until you hit a site that loaded data with JavaScript. From there, you fought with brittle selectors or pulled in headless browsers to simulate user behavior. It got the job done, but anything dynamic or slightly different meant things broke fast.
What’s happening now is more interesting. AI-driven agents are starting to handle full web sessions with reasoning. Instead of hardcoding steps, they adapt based on the page's structure or task. Some use vision models to “see” elements, while others use token-based context models to reason through actions. Either way, they can operate like a real user: clicking, filling forms, waiting for async events, and recovering from errors in ways scripts couldn’t.
A big part of this shift is due to better foundation models and easier access to scalable compute. LLMs can now run in lightweight containers or via APIs, and teams can spin up browser sessions on demand. With more businesses needing dynamic automation, like running pricing audits or handling complex signups, there’s a clear reason to invest in agents that don’t follow a script.
But there’s a catch. Running one agent is easy. Running hundreds, consistently, without them crashing or getting blocked is hard. That’s where most projects stall. You need orchestration, session management, proxies, and some fallback logic. The tech is there, and the agents are getting better. Now it’s about solving scale and stability so they can handle real workloads.
Meet the Innovators: Skyvern, Browseruse, Browserbase, and Hyperbrowser
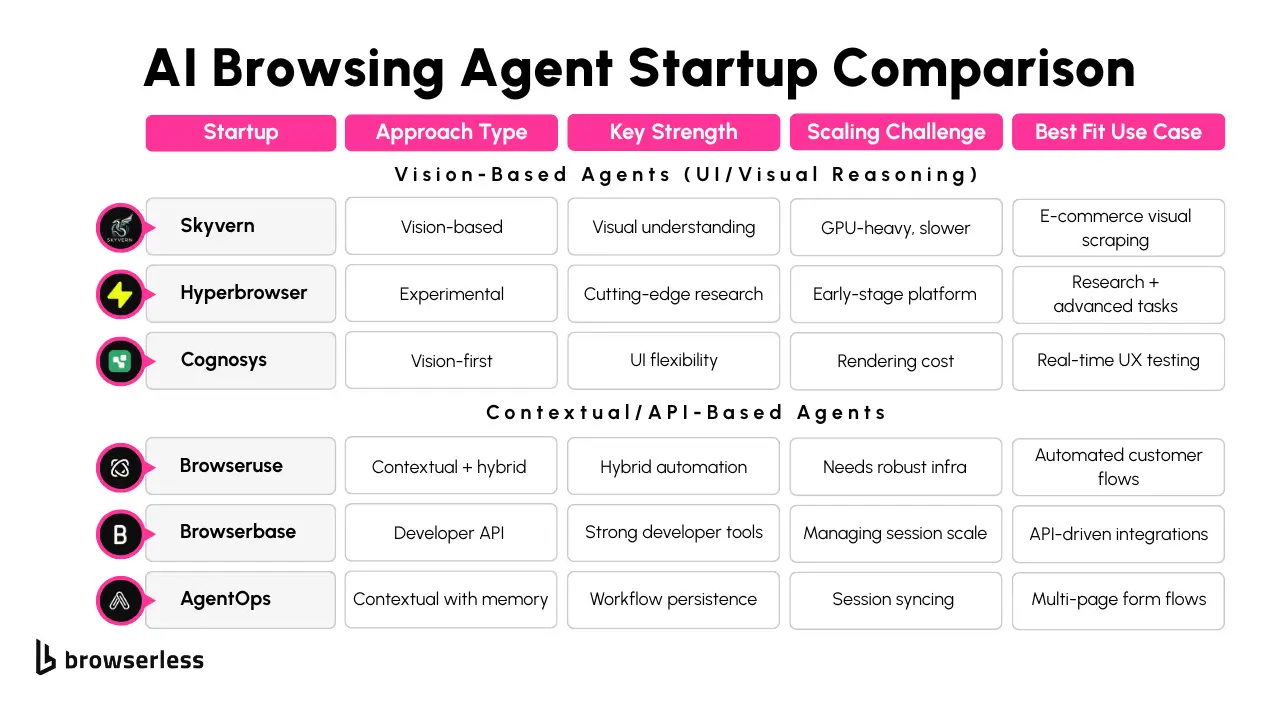
These startups are approaching AI browsing from different angles, each with its own focus and technical strengths. Some lean toward visual understanding, others toward contextual flows, and others toward orchestration at scale.
Skyvern
Skyvern is heavily investing in vision-based agents. Their models work on rendered webpages rather than raw HTML, using computer vision to identify and interact with visual elements on the screen. This lets them handle UI changes that break traditional selectors and makes their agents feel more human when interpreting layouts.
They also incorporate multimodal models, blending text input with visual reasoning to improve goal alignment. The tradeoff is higher resource requirements rendering and interpreting full UIs in real time is not lightweight but Skyvern’s approach is well-suited for workflows where pixel-level accuracy matters.
Browseruse
Browseruse focuses on contextual agents that operate on the DOM structure and interact through standard browser automation protocols. What makes them interesting is their ability to integrate human-in-the-loop workflows. Agents can hand off sessions to a human via LiveURL or fetch human feedback mid-run.
This is especially useful for tasks like fraud reviews, approvals, or any process that benefits from AI plus human oversight. Browseruse agents are often deployed using CDP events and Browserless sessions, giving them fine-grained control over browser activity and session lifecycle.
Browserbase
Browserbase is building a developer-first automation platform that prioritizes reliability and scalability. Their API abstracts most of the overhead typically needed to control headless browsers at scale.
Rather than building AI agents, they offer the infrastructure to support them, which is especially useful for teams that want to focus on agent logic without handling the browser backend. Their tooling is tuned for massive parallelism, session stability, and debugging support, making them a strong choice for teams scaling experiments into production environments.
Hyperbrowser
Hyperbrowser is exploring how far reasoning-based agents can go using LLMs and decision-making layers. They’re focused more on AI research and are testing workflows that include tool use, memory, and adaptive planning. Their work is early-stage but impressive.
They’re testing agents that can dynamically rewrite their plans based on feedback and environmental context, which is promising for long-form or multi-step workflows. While Hyperbrowser isn’t shipping plug-and-play tools yet, its open research and developer tooling are gaining traction among technical teams building their agent stacks.
These startups are building powerful systems that solve different pieces of the agent puzzle. But running them at scale, reliably, with the right browser infrastructure underneath, is still a challenge. That’s where the cloud automation backbone comes into play.
Scaling AI Agents with Browserless The Cloud Backbone
Running AI agents locally can get you through early tests, but scaling that setup often becomes a bottleneck. Developers working on AI-driven browsing usually run into limits fast browser crashes, system resource caps, or the complexity of managing dozens of sessions simultaneously.
That’s where offloading to cloud browsers makes much more sense. With Browserless, you can trigger browser sessions via REST, BaaS v2, or BrowserQL, without spinning up your browser infrastructure. It works well with Playwright, Puppeteer, and anything else that can talk to Chrome over CDP.
For teams that care about reliability, being able to configure things like proxy rotation, session reuse, and stealth mode is a big help. You’re not stuck reinventing browser orchestration whenever you want to do something more advanced. Want to simulate repeat visits or avoid bot detection? You can set that up with flags or through the API. If you’re debugging why something’s breaking mid-session, having logs and session snapshots gives you real visibility without guessing.
Another area that’s underrated until you need it is event-based control through CDP. You can stream events from a live browser session, trigger actions based on network responses or page loads, and coordinate with an agent to decide what to do next. That feedback loop becomes useful once your AI decides based on the browser state.
Vision vs. Contextual Agents: What’s Next in the Race
AI agents for web browsing are being built around two main approaches. The first is vision-based, where models rely on page screenshots or rendered views and use multimodal understanding to interact. These agents behave more like humans, identifying buttons by appearance, parsing visual layout, and applying spatial reasoning. They often require GPU resources and have higher latency, but they’re promising when dealing with UI-heavy pages that don’t expose much semantic structure.
Conversely, contextual or token-based agents work directly with structured DOM data. Instead of relying on images, they parse the page tree, read attributes like class names and IDs, and act on those signals. This makes them much faster and lighter to run.
They’re easier to test, scale, and monitor in real-time, and they’re usually a better fit when you’re deploying across many sessions. The trade-off is that these agents depend heavily on selector stability and clean markup.
Most teams working on production-ready automation are experimenting with hybrids. You might start with a token-driven parser but fall back to a vision-based fallback when the page structure breaks or elements aren’t labeled cleanly.
It’s not always one or the other; a hybrid agent might run a vision model only for key decision points, like CAPTCHA detection or finding hidden buttons, while handling the bulk of interaction through structured selectors.
Browserless doesn’t push you toward one model. If you’re running a vision-based agent, the platform handles headless and headful modes, so you can still send screenshots or simulate full environments. If your agent is DOM-first, you can hook directly into the browser’s CDP layer or DOM via BrowserQL. Either way, you get full control over the browser state and outputs.
Picking the simpler model first will get you more mileage for most use cases. If you hit a wall due to messy UIs or inconsistent markup, layering on a lightweight visual fallback can be a good next step. The infrastructure should stay out of your way while testing both paths.
Conclusion
We’re beginning a new phase in web automation, where AI agents are starting to move from demos to deployed systems. The biggest wins will come from teams combining flexible reasoning with stable, scalable execution. Browserless makes that second part easier, giving you cloud browsers, session control, stealth features, and event streams without the browser maintenance headaches. If you're building anything from LLM agents to test automation at scale, it's worth seeing how it holds up in your workflow. Sign up for a free trial and start testing today.
FAQs
What are AI web browsing agents, and how do they work?
AI web browsing agents are systems powered by models like GPT, reinforcement learning frameworks, or vision-based tools that can interact with websites dynamically. Instead of relying on static scripts or selectors, they interpret UI elements in real time and make decisions about navigation, data extraction, or form submission using reasoning or perception.
What’s the difference between vision-based and contextual AI agents?
Vision-based agents rely on image input and multimodal understanding to simulate how a human would view a page. In contrast, contextual agents use the DOM structure, metadata, and other page signals to operate more efficiently. Vision agents offer flexibility for unseen layouts but are slower and resource-intensive. Contextual agents scale better and are usually preferred for production environments.
Why do AI web agents struggle to scale?
Most AI agents are tested in isolated conditions and break down when handling hundreds of concurrent browser sessions, unpredictable captchas, or real-time session handoffs. Scaling requires infrastructure that can manage browser orchestration, session memory, and network-level tasks, all of which traditional setups don’t offer out of the box.
How does Browserless help scale AI web browsing agents?
Browserless provides a cloud-based infrastructure where agents can launch headless browser sessions with session management, stealth mode, proxy rotation, and CDP-level control. It supports REST APIs, BrowserQL, and integrations with frameworks like Puppeteer or Playwright to handle both automation and live handoff at scale.
Can AI agents be used for real production web automation tasks?
Yes, with the right infrastructure, AI agents can move beyond experimentation. Use cases include automated checkout flows, fraud review, mobile UX testing, and dynamic data scraping. The challenge is execution at scale, and platforms like Browserless help bridge that gap between AI reasoning and production-grade automation.