Key Takeaways
- Scraping legality isn’t one-size-fits-all; it depends on the data type, method of access, and the applicable legal jurisdiction.
- Violating Terms of Service isn't automatically illegal, but it can contribute to legal disputes or technical enforcement.
- Responsible scraping matters: Following ethical guidelines, such as respecting
robots.txt, avoiding PII, and maintaining transparency, helps reduce risk.
Introduction
Web scraping refers to the automated collection of data from websites using scripts or tools that mimic human browsing. In 2026, legal questions around scraping are more relevant than ever, driven by the rise of AI, competitive data monitoring, and increasing platform restrictions. While scraping tools are powerful, the legal framework around them is complex and constantly shifting. In this article, you’ll learn when web scraping is allowed, where it gets risky, and how to stay compliant.
What Makes Web Scraping Legal or Illegal?
How Data Type and Access Method Impact Legality
Whether web scraping is legal depends heavily on the kind of data being collected and how it’s accessed. Public data, such as unprotected HTML on a website, generally carries less legal risk when scraped. On the other hand, content behind logins, paywalls, or that contains personal user information often triggers legal concerns. Accessing this type of data without explicit permission could cross legal boundaries, even if it’s technically possible to do so.
The method of access also matters; suppose scraping involves bypassing authentication, ignoring robots.txt, or manipulating URLs to extract hidden or gated content, which raises red flags. Courts and regulators may view those tactics as unauthorized access, especially when combined with large-scale or commercial scraping.
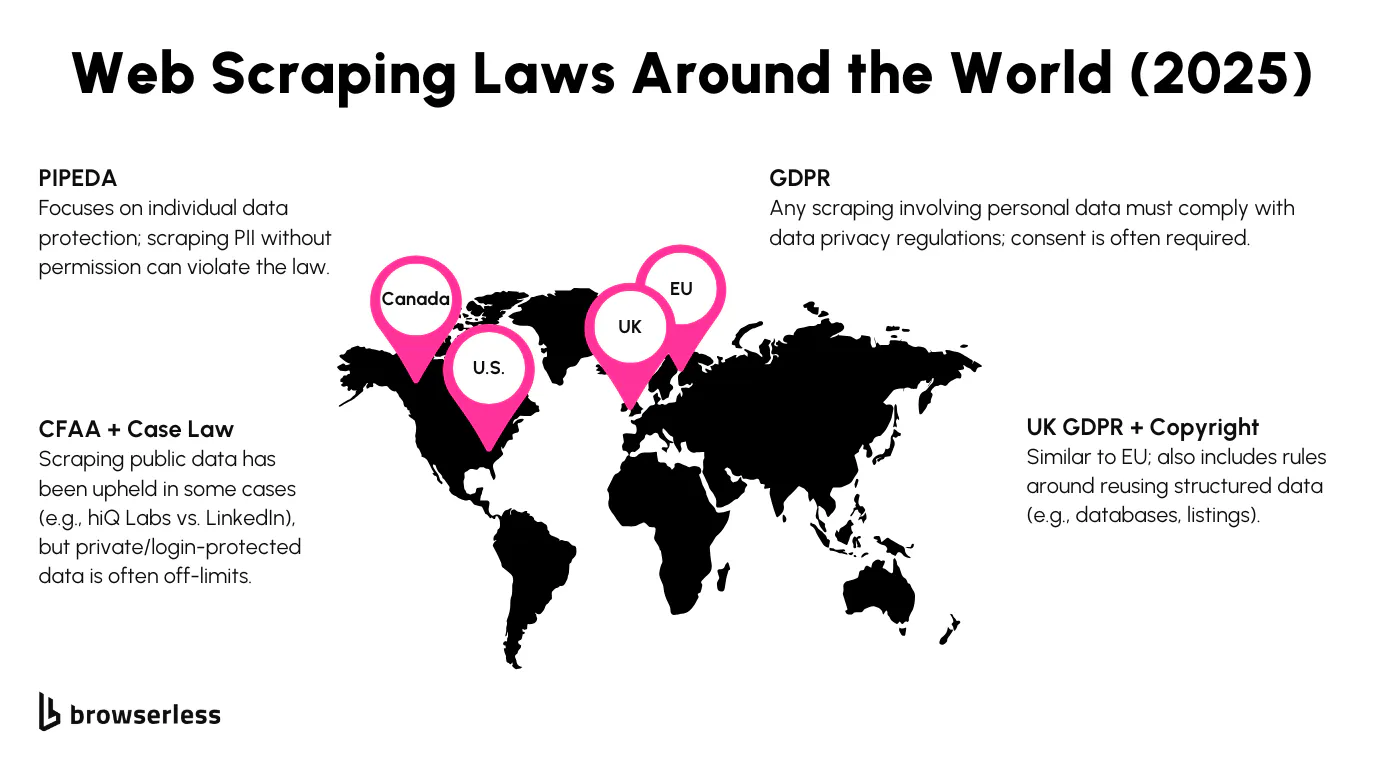
U.S. Laws and Legal Precedents
In the U.S., the Computer Fraud and Abuse Act (CFAA) plays a major role in determining when scraping becomes illegal. Initially designed to prosecute hacking, the CFAA has been applied to scraping cases, where companies claim that bots accessed their systems without permission. The interpretation of what constitutes “unauthorized access” has evolved over the years and remains a subject of debate.
One of the most influential cases in this space is hiQ Labs vs. LinkedIn. hiQ was scraping publicly accessible LinkedIn profiles, and LinkedIn tried to block them, citing the CFAA.
In a major ruling, the court sided with hiQ, saying that scraping public data did not constitute unauthorized access under the CFAA. While this decision clarified one aspect of the law, it didn’t provide blanket approval for all scraping, especially if the data is personal, sensitive, or protected behind authentication.
International Regulations and Compliance Factors
Outside the U.S., different privacy and data protection laws shape how web scraping is viewed. In the European Union, the General Data Protection Regulation (GDPR) sets strict rules on collecting and storing personal data.
If scraping includes names, emails, or behavioral information tied to identifiable individuals, it likely falls under the GDPR, which carries consent, disclosure, and storage requirements.
In Canada, PIPEDA governs the collection and use of personal data, and similar principles apply. The UK Data Protection Act (the post-Brexit version of the GDPR) mirrors much of the EU’s stance, meaning that scraping personal data from UK-based sites or users requires thoughtful compliance measures. These international laws don’t just regulate what’s scraped; they often impact how that data is handled after it is collected.
Scraping vs. Terms of Service Violations
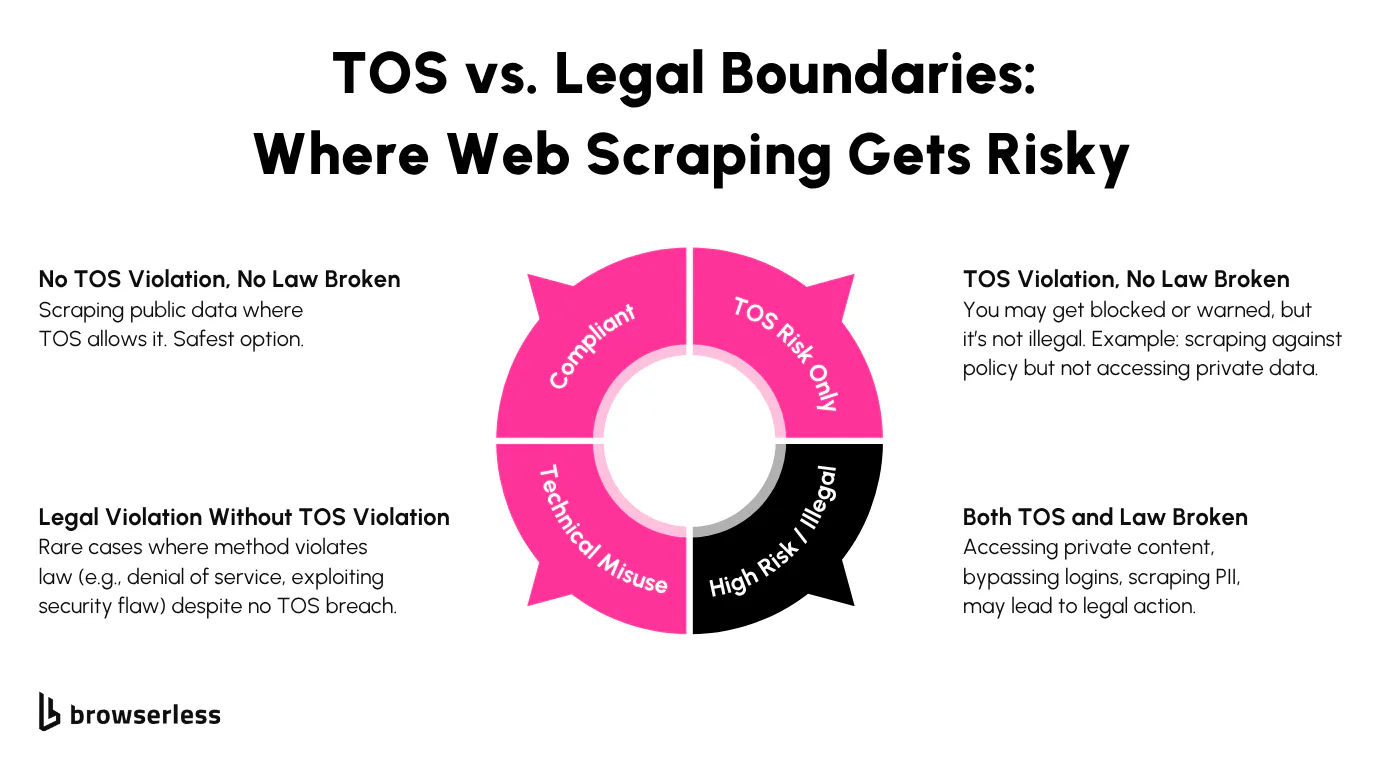
Terms of Service Aren’t Laws, But They Can Still Block You
Terms of Service (TOS) define how a website expects users and automated systems to behave. Violating those terms doesn’t automatically lead to criminal charges, but it does open the door to being blocked, flagged, or contacted by the site’s legal team.
Most scraping-related TOS clauses specifically prohibit bots, automated data collection, or high-frequency access, and when those boundaries are crossed, operators often respond quickly.
In practical terms, violating TOS can lead to a cascade of disruptions: sudden IP bans, automated takedowns, or cease-and-desist notices. Some sites monitor traffic signatures or authentication behavior to detect non-compliant clients.
Even without legal action, repeated violations can disrupt scraping workflows, break data pipelines, and erode trust among partners or clients relying on that data.
When Terms of Service Become Legal Evidence
Courts don’t treat every TOS violation as a crime, but in cases involving scraping, those violations are often central to the legal argument. If someone collects data by bypassing authentication, spoofing identity headers, or ignoring technical controls, that activity may be framed as unauthorized access.
In this context, violating the TOS helps establish intent and demonstrates that access wasn’t consensual. This is especially relevant under laws like the Computer Fraud and Abuse Act (CFAA) in the U.S., where “unauthorized access” is the pivot point for liability.
Even if the scraped content is technically public, ignoring access rules laid out in the TOS may be enough to trigger scrutiny. Courts have varied in how they interpret this, but companies defending their platforms often point to TOS violations to support claims of intrusion or misuse.
Technical Enforcement Isn’t Just for Show
Websites serious about limiting scraping don’t rely solely on policy; they also deploy active enforcement. CAPTCHA remains a baseline filter, but detection has become far more sophisticated. Many sites now fingerprint browsers using JavaScript-based entropy checks, examining aspects such as canvas rendering and WebRTC behavior to determine if a session behaves like a typical user session.
User-agent detection and request-rate tracking are still widely used. If your scraper hits a site too aggressively, or rotates user agents in a way that breaks real-world consistency, it usually won’t take long to get flagged.
Some platforms utilize session-based anomaly detection to identify patterns across IP addresses or proxies. The more custom or evasive your scraping stack becomes, the more likely it is to be perceived as a hostile actor, unless you closely mimic a legitimate browsing footprint.
How to Scrape Responsibly and Ethically
Operational Practices That Respect Boundaries
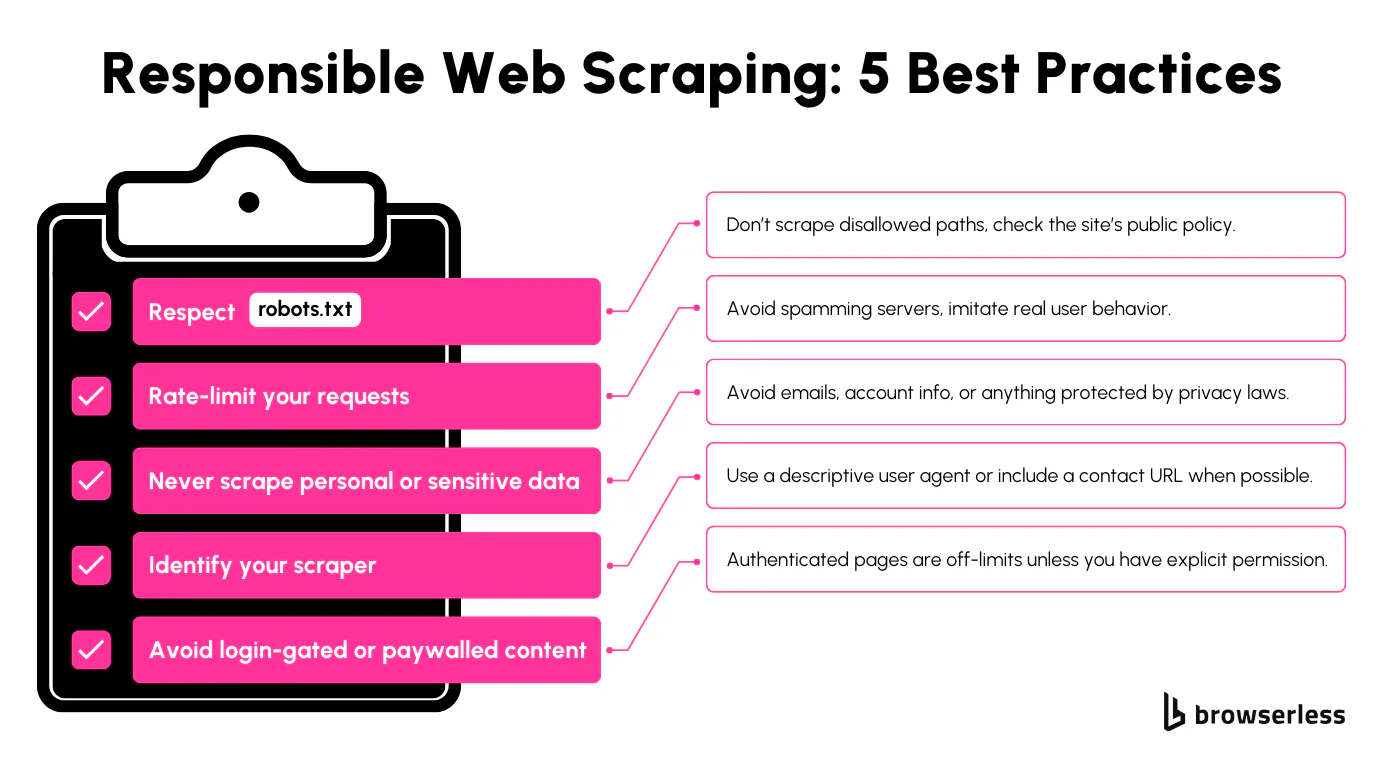
Starting with the basics, you’ll want to examine the robots.txt file. While not legally binding, this file serves as a public signal from the site owner regarding areas of their site that they expect crawlers to avoid. Ignoring it doesn’t guarantee legal problems, but it can undermine claims of acting in good faith. If you’re working on automation that touches multiple endpoints, review the robots.txt file regularly. Sites often change their restrictions without public notice.
Request timing is another practical control. Throttling your request rate to align with normal human interaction, think seconds between clicks, not milliseconds, can make a significant difference in whether your scraping goes unnoticed or gets flagged.
Most commercial sites track user behavior closely. Rapid, repeated requests from the same IP or user agent almost always trigger detection systems. Backing off your frequency and randomizing intervals can help maintain access.
Respect Identity, Permissions, and Privacy
User-agent strings say a lot. Using a fake user agent, or worse, impersonating a legitimate service like Googlebot, can raise immediate suspicion. It’s more honest and more sustainable to use a real, well-structured user agent string.
Many developers also include a contact email in the user agent field. That alone can reduce friction with site owners if you’re ever flagged or asked to explain what your script is doing.
Authenticated content should be off-limits unless you’ve been given explicit permission to access it. That includes paywalled articles, user dashboards, or anything behind a login form. Both technical and legal restrictions almost always protect these areas.
The same goes for personal data. Even if something like an email address is publicly visible, collecting it systematically without a lawful purpose can trigger privacy law violations in jurisdictions such as the EU or Canada. It’s safer to filter out anything that appears to be personally identifiable information (PII) unless your use case requires it and you're certain it's lawful to retain.
Tools That Support Ethical Automation
Browserless is designed to support advanced browser automation while still respecting compliance boundaries. It provides programmatic control over session management, allows you to customize headers and behaviors, and offers stealth features that reduce bot detection.
But it doesn’t mean rules no longer apply. Even with stealth modes enabled, you’re still accountable for what data you access and how frequently you interact with a site.
Tools like this are best utilized in environments where transparency and permission are integral to the workflow. Whether you’re running audits, building internal data pipelines, or prototyping automation tasks, it helps to design your scripts in a way that can withstand external review.
If you’re using automation in production, document your traffic patterns, log scraping decisions, and keep a record of the endpoints you hit. Doing that doesn’t just keep you safe; it shows that you’re serious about compliance.

Legal Scraping Use Cases and How Businesses Can Stay Safe
Practical Use Cases That Align with Legal Norms
Some scraping tasks are widely recognized as low-risk when done correctly. One example is price comparison. Many retailers make pricing data publicly available on their websites, and collecting this information for competitive tracking or aggregation usually doesn’t cross any legal boundaries, so long as the scraping doesn’t overwhelm the site or bypass access controls.
SEO auditing is another common use case. Marketers and technical teams regularly scrape public metadata, keyword placement, and content structure from competitor sites.
Since this data is publicly available and doesn’t involve personal information or authentication, it tends to fall well within accepted usage.
The same logic applies to market research and academic studies when they rely on surface-level HTML, respect public access rules, and avoid targeting sensitive platforms.
Risk Management Through Review and Internal Controls
Before scraping at scale, it's helpful to assess the legal posture of the workflow. Start by classifying the data you’re collecting: is it public HTML, embedded API data, or something pulled from behind a login?
A simple internal checklist helps distinguish between safe projects and those that require additional review. Any activity involving credentials, form submissions, or personally identifiable information (PII) should be subject to further scrutiny.
For larger scraping operations, legal review is worth the effort. High-volume extraction, even from public pages, can raise concerns if the platform in question has strong scraping restrictions in its Terms of Service. It's also smart to monitor those terms over time, especially on high-traffic targets.
TOS updates often include new anti-scraping clauses that weren’t there before. Internally, maintaining policy documents, logging scraping decisions, and keeping a record of data sources provides legal teams and compliance reviewers with more context, which can help reduce long-term risk exposure.
Conclusion
The legality of web scraping depends on the data you collect, how you access it, and the region in which you're operating. Technical ability alone doesn’t mean legal permission. Small details, such as login access or terms of service, can significantly influence legal outcomes. Developers and businesses who stay informed and use ethical practices are more likely to avoid trouble. If you're exploring scraping at scale, book a demo with Browserless to see how it can support safe, effective automation.
FAQs
Is web scraping illegal?
No, web scraping isn’t inherently illegal. It depends on what data is being scraped, whether it’s behind authentication, how it’s accessed, and which laws apply in your region.
Can I legally scrape data from any public website?
Not always. Even if data appears to be public, scraping it may violate a site's Terms of Service or privacy laws, especially if it involves personal information or bypasses security controls.
Does violating a website’s Terms of Service make scraping illegal?
Not necessarily. Violating TOS can lead to technical blocks or civil action, but it doesn’t always mean criminal liability unless paired with unauthorized access tactics.
What are ethical scraping practices?
They include respecting robots.txt, avoiding PII, rate-limiting your requests, using a real user-agent string, and never scraping content behind logins or paywalls without consent.
What laws affect web scraping internationally?
In the U.S., the CFAA governs unauthorized access. In the EU and UK, GDPR and the Data Protection Act apply to personal data. Canada’s equivalent is PIPEDA. Each has different standards for compliance.