In this article we'll look at managing sessions and their data when using Puppeteer. That includes:
- Storing and reusing cookies
- Reconnecting to browsers
- Using captcha-approved endpoints
- Managing the --user-data-dir
These techniques are essential if you're performing complex workflows behind login pages, or want to avoid repeat actions such as getting past bot detectors. The clean slate model of automation libraries means it's up to you to connect cookies to instances, secure credentials, synchronize the localstorage and much more.
So let's dive into how to manage sessions.
Freshly baked cookies
Currently, one of the most used approaches is to do a login, then to save the session data to disk. Take for instance, this typical session-data-saving example
const init = async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
/*Your login code*/
const cookies = JSON.stringify(await page.cookies());
const sessionStorage = await page.evaluate(() => JSON.stringify(sessionStorage));
const localStorage = await page.evaluate(() => JSON.stringify(localStorage));
await fs.writeFile("./cookies.json", cookies);
await fs.writeFile("./sessionStorage.json", sessionStorage);
await fs.writeFile("./localStorage.json", localStorage);
browser.close();
};
for which you also have to implement a cookie, sessionStorage and localStorage loading.
const start = async () => {
await innit();
const cookiesString = await fs.readFile("./cookies.json");
const cookies = JSON.parse(cookiesString);
const sessionStorageString = await fs.readFile("./sessionStorage.json");
const sessionStorage = JSON.parse(sessionStorageString);
const localStorageString = await fs.readFile("./localStorage.json");
const localStorage = JSON.parse(localStorageString);
await page.setCookie(...cookies);
await page.evaluate((data) => {
for (const [key, value] of Object.entries(data)) {
sessionStorage[key] = value;
}
}, sessionStorage);
await page.evaluate((data) => {
for (const [key, value] of Object.entries(data)) {
localStorage[key] = value;
}
}, sessionStorage);
};
and to add on that, if you have multiple instances, you also need to implement a logic for synchronizing the data among instances. Not to mention that there's no way to save HTTP-only cookies. It can get very messy very quickly.
Luckily, that's one of the things we realized at Browserless, and we created a painkiller to tackle this issue with ease and cleanly.
Reconnects with Browserless
With Browserless, you can keep the browser session alive and kicking in the background, while your instances connect remotely to run with the existing cookies, localStorage and sessionStorage.
To reconnect to an existing browser is as easy as calling Browserless.reconnect to get the web socket URL to connect to this existing browser.
const init = async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io/chromium?token=YOUR_TOKEN`,
});
const page = await browser.newPage();
const cdp = await page.createCDPSession();
/*Your login code*/
// Allow this browser to run for 1 minute, then shut down if nothing connects to it.
// Defaults to the overall timeout set on the instance, which is 5 minutes if not specified.
const { browserWSEndpoint } = await cdp.send("Browserless.reconnect", {
timeout: 60000,
});
// Use browserWSEndpoint to reconnect to this browser
await browser.close();
};
This keeps the session alive in the background for 60000 ms (1 minute), even if you disconnect all your instances — it can be loading something or just idling waiting for new connections, it won't judge you.
Let's look at a real example of staying logged in.
const init = async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io/chromium?token=YOUR_TOKEN`,
});
const page = await browser.newPage();
const cdp = await page.createCDPSession();
await page.goto("https://news.ycombinator.com/login?goto=news", {
waitUntil: "networkidle2",
});
await page.type("input[name=acct]", "....");
await page.type("input[name=pw]", "....");
await page.click("input[type=submit]");
await page.waitForNetworkIdle();
const { browserWSEndpoint } = await cdp.send("Browserless.reconnect", {
timeout: 300000,
});
browser.close();
return browserWSEndpoint;
};
In this example, init method is creating a new connection, loging to Hacker News and returning the reconnection endpoint. Lets reconnect to this existing browser.
const reconnect = async (browserWSEndpoint) => {
const browserReconnect = await puppeteer.connect({
browserWSEndpoint: `${browserWSEndpoint}?token=YOUR_TOKEN`,
});
const page = await browserReconnect.newPage();
await page.setViewport({ width: 800, height: 500 });
await page.goto("https://news.ycombinator.com/"); // No login!
await page.screenshot({ path: "hackernews.png", fullPage: true });
browserReconnect.close();
};
*et voilà, *we're in, and we're still logged in!
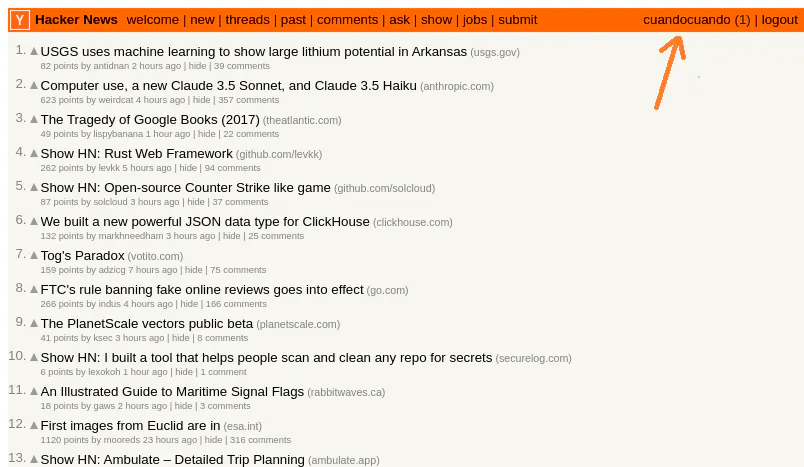
Easy, isn't it?
But there are some things to consider! These connections are basically "new tabs" on a single browser, not isolated instances running from a clean slate. This means all the advantages and disadvantages, like website ads tracking cookies and all the instances/tabs being able to "speak" with each other.
We'd advise against having a single remote browser for all your work with lots of session data, but to break it down into several remote browsers with small amounts of session data.
Connecting to a captcha-approved session
If you are working with bot-protected sites, you can take advantage of our /unblock endpoint. It uses a range of advanced tactics to hide automation fingerprints and get past strict bot detectors.
You can then return approval cookie generated by the captcha, or a websocket for the approved session. Let's try it out.
const unblock = async () => {
const targetURL = "https://example.com";
const unblockURL =
"https://production-sfo.browserless.io/unblock?timeout=60000&proxy=residential&proxyCountry=us&proxySticky=true&token=YOUR_TOKEN";
const options = {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
url: targetURL,
browserWSEndpoint: true,
cookies: true,
content: false,
screenshot: false,
ttl: 60000,
}),
};
//Calling /unblock endpoint to get cookies and wsEndpoint
const response = await fetch(unblockURL, options);
const { browserWSEndpoint, cookies } = await response.json();
return { browserWSEndpoint, cookies };
};
Now you can reconnect to the unblocked site using the browserWSEndpoint similar to the previous example, or you can use cookies for new connections.
Reusing the data directory
Another option for maintaining session configurations is to reuse the user data directory. Browserless supports the --user-data-dir argument, allowing you to create a new browser using an existing data directory. Let's take a look.
const initDataDir = async () => {
const queryParams = new URLSearchParams({
token: "YOUR_TOKEN",
timeout: 60000,
launch: JSON.stringify({ args: ["--user-data-dir=~/browserless-cache-123"] }),
}).toString();
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io/chromium?${queryParams}`,
});
const page = await browser.newPage();
await page.goto("https://news.ycombinator.com/login?goto=news", {
waitUntil: "networkidle2",
});
await page.type("input[name=acct]", "cuandocuando");
await page.type("input[name=pw]", "cuandocuando");
await page.click("input[type=submit]");
await page.waitForNetworkIdle();
browser.close();
};
In this example we are specifying the --user-data-dir argument it means that once the browser is closed the data dir won't be deleted and it can be reused for a future connection. Let's create a new browser with the same use data dir.
const newConnectionSameDataDir = async () => {
const queryParams = new URLSearchParams({
token: "YOUR_TOKEN",
timeout: 60000,
launch: JSON.stringify({ args: ["--user-data-dir=~/browserless-cache-123"] }),
}).toString();
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io/chromium?${queryParams}`,
});
const page = await browser.newPage();
await page.setViewport({ width: 800, height: 500 });
await page.goto("https://news.ycombinator.com/"); // No login!
await page.screenshot({ path: "hackernews_2.png", fullPage: true });
browser.close();
};
The --user-data-dir argument allows you to preserve browser configurations, downloaded images, cookies, etc.