Introduction
Web scraping has become a skill that almost every developer, researcher, or data-driven team eventually uses. Need to track competitor pricing? Scrape it. Want to stay on top of market trends? Scrape it. Pulling together a dataset for research or a side project? Scrape it. A web scraper turns the web into data you can actually work with. Of course, scraping isn’t always straightforward. Some sites are static and easy, while others rely on JavaScript, AJAX calls, infinite scroll, or bot detection that can block you fast. That’s why understanding scraper types, key techniques, and the right tools makes all the difference. This guide will walk you through everything, from the basics to advanced approaches.
What Is Web Scraping?
Web scraping is a method for extracting data and useful information from websites without requiring manual intervention. Instead of spending hours copying and pasting product listings, job posts, or news headlines, you can write a bit of code that does the heavy lifting for you. It’s like giving your browser superpowers to grab exactly what you need and organize it into clean, usable data. Whether you’re conducting market research to collect data, tracking prices, or building a dataset for a machine learning model, web scraping is the engine that makes it possible.
There are two primary approaches here: manual versus automated scraping. Manual scraping might work if you’re grabbing a few things occasionally, perhaps poking around in the developer tools, or copying content into a spreadsheet.
But for anything more serious or repetitive, you’ll want to use an automated tool to do it. That’s where tools like Python, JavaScript, Puppeteer, Playwright, and Browserless can help you programmatically load pages from the web server, handle dynamic content, and extract exactly what you need, all while skipping the repetitive grunt work.
Instead of manually copying data from a page, you can automate it with just a few lines of Python:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# Extract titles
titles = [t.get_text() for t in soup.find_all("h2")]
print(titles)
Different Types of Web Scrapers
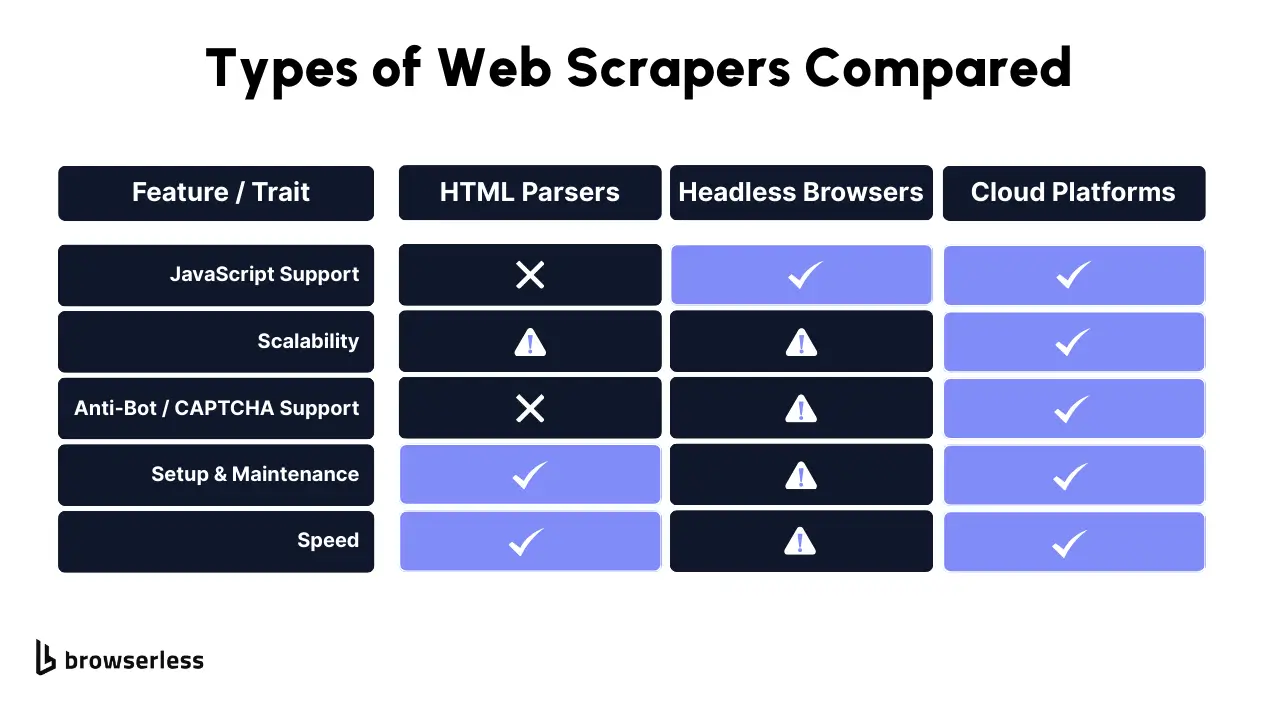
When it comes to web scraping, there’s no one-size-fits-all solution. The tool or method you choose depends heavily on the type of site you're dealing with, especially if it's publicly available data. , how the data is loaded, and what kind of web crawling or data extraction you need.
Whether you're scraping a static web page or working with a JavaScript-heavy single-page app, picking the right web crawler can make the difference between clean, structured data and a frustrating mess of HTML code. Let’s break down the most common types of web scraping tools and when each one makes the most sense for your data collection process.
HTML Parsers (e.g., BeautifulSoup)
HTML parsers are often the starting point for individuals interested in web scraping. If you’re dealing with static sites where the content is directly embedded in the HTML code, tools like BeautifulSoup (Python) are lightweight, fast, and surprisingly powerful.
These scrapers excel at extracting specific data to efficiently gather information from consistent tags across multiple web pages, such as retrieving product names from e-commerce websites or aggregating headlines from news sites. While they can’t handle JavaScript-rendered content, they’re perfect for straightforward web data extraction tasks where the content is already visible in the source.
Headless Browsers (e.g., Puppeteer, Playwright)
For websites that rely on client-side rendering, meaning the web page loads content through JavaScript after the initial load, you’ll need a more advanced approach. Headless browsers like Puppeteer and Playwright emulate real web browsers and allow you to interact with the page using scraping programs, as if you were a user.
This means they can handle things like dropdowns, lazy-loaded images, or infinite scroll, making them ideal for complex web scraping applications that gather data.
For dynamic websites that load content with JavaScript, a headless browser like Puppeteer makes the process easy:
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto("https://example.com");
const headlines = await page.$$eval("h2", (els) => els.map((el) => el.innerText));
console.log(headlines);
await browser.close();
})();
Here, Puppeteer spins up a real browser, loads the page, and extracts the data just as a human user would. They’re widely used in lead generation, price monitoring, data mining, and even academic research, where a reliable and structured format is essential for output.
Browser Automation Platforms (e.g., Browserless)
Managing headless browsers at scale can be a pain, especially when you're running multiple concurrent scrapers or dealing with too many requests from a single IP. That's where platforms like Browserless shine.
They give you plug-and-play access to headless browsers via online services that provide a web scraping API, allowing you to focus on scraping data without managing infrastructure.
With built-in features such as proxy rotation, CAPTCHA solving, session persistence, and stealth mode (which helps avoid detection by website owners), Browserless is ideal for production-scale tasks like brand monitoring, market research, or large-scale scraping of contact details.
APIs for Structured Data Retrieval
Sometimes, the smartest move is not to scrape sites at all but to use an API if one’s available. APIs are the cleanest form of web data extraction because they enable you to gather information and provide structured data directly, typically in JSON or XML formats.
This eliminates the need to parse unstructured data from messy HTML and is ideal for projects such as sentiment analysis, where you should also consider whether web scraping is legal for business intelligence or real-time market trends tracking.
Many companies offer application programming interfaces (even if they don’t advertise them), and using one is typically more stable, more ethical, and far more efficient than scraping raw web page content.
How Web Scrapers Work
Whether you're building a web scraper for fun, academic research, or production-level data scraping, understanding the flow behind it is key not just for performance, but to avoid memory leaks, minimize memory usage, and ensure long-running background tasks don’t go rogue. Here’s a deeper look at each step in the web scraping workflow, with real-world concerns like memory allocation, heap management, and performance bottlenecks in mind.
Sending a Request
It all starts with the program sending an HTTP request to the target web page. Here’s a Python example of sending an HTTP request and printing the raw HTML:
import requests
url = "https://example.com"
response = requests.get(url)
print(response.text[:500]) # print the first 500 characters
This example illustrates the first step in the data collection process: retrieving raw HTML from a web server. This step is straightforward, but has depth.
You may be interacting with a REST API or targeting search engines. , or crawling through multiple web pages using custom headers, proxy rotation, or stealth techniques to avoid blocks.
If your request logic is sloppy, for instance, if you don’t handle retries or rate limits for retrieving raw data, you can consume system memory, overload the heap, and risk leaking memory through runaway pointers or unclosed sockets.
And remember: every request, especially from a single program, spins up a bit of allocated memory for networking, caching, or queuing. If that’s not released or garbage-collected properly and the data isn't stored in a structured format, the allocated memory accumulates. It’s a small detail many devs miss during code review.
Rendering the Page (If Needed)
If you’re scraping static content, you can skip rendering. However, with dynamic sites, especially those that rely heavily on JavaScript, rendering is crucial for optimal performance.
Headless browsers, such as Puppeteer and Playwright, replicate the full browser environment, making them ideal for extracting data from websites, executing scripts, and loading interactive content. That’s powerful and expensive in terms of memory consumption.
Every new browser instance allocates hundreds of MBs of memory, creating DOM trees, JS contexts, caches, and event listeners. If you don't explicitly release memory by closing pages or sessions. In that case, it's essential to manage it responsibly, as scraping bots can be demanding in handling relevant data.
If a memory leak occurs due to orphaned objects or unreachable memory, the program continues to consume system resources until a critical error occurs, often when the program terminates unexpectedly.
This is where tools like Browserless shine: they manage sessions for you, abstract browser state, and help prevent memory leaks by cleaning up unused instances, even during high-volume data collection.
Extracting Relevant Data
Once the page is rendered, the next step is to extract the data from a website. This involves navigating the DOM, running selectors, parsing text nodes, and extracting relevant information into local variables or arrays. It sounds easy, but it’s often where bugs creep in.
Say you’re extracting product titles from a page. You might loop through DOM elements and store each in memory. But what if the loop never ends due to malformed HTML or bad pointer logic? Or what if you’re holding on to every page’s full DOM in memory without purging previous ones? Suddenly, you're holding onto massive heap allocations with no way to free memory, classic leak memory behavior.
The fix? Carefully scoped functions for competitor analysis, proper memory lifecycle control, and testing for common causes of memory retention, like lingering references in closures.
Parsing and Storing
Now that you’ve extracted your data, it’s time to clean, format, and store it, typically as a JSON file, a CSV file, or in a database. But this step, too, can hide performance killers.
If your parser holds onto all raw page content while writing to disk, you're holding more memory than necessary. If you keep too many results in arrays before flushing them to storage for news monitoring, you risk an OOM (out-of-memory) crash.
An example is failing to clear a results list after each page the program runs; memory usage increases, and eventually, your application terminates with no clear exception.
Proper garbage collection helps to mitigate issues caused by unstructured data , but it's not a magic solution. Once you’ve extracted the data, it’s common to save it into a CSV file for later analysis:
import csv
data = [["Product", "Price"], ["Widget", "$10"], ["Gadget", "$15"]]
with open("products.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerows(data)
print("Data saved to products.csv")
Storing scraped results in a structured format, like a CSV file, makes them easier to analyze or share. You must manage heap usage proactively by releasing large objects, dropping references once they’re no longer needed, and detecting memory leaks using profiling tools such as tracemalloc, Valgrind, or Chrome DevTools.
Web Scraping Techniques
There’s a bit of art and a lot of strategy involved in getting scraping right, especially when you’re working with modern websites that throw up roadblocks like JavaScript rendering or bot detection. Below are some of the real-world techniques I’ve found most useful, and the kinds of things you’ll probably run into if you’re doing this at scale.
Static vs. Dynamic Page Scraping
Let’s start with the basics: static pages are the easy ones. All the data you want is already in the HTML, ready to be parsed. But with dynamic pages, what you see in your browser might be generated by JavaScript, and that means you won’t find it in a raw HTML response.
If that’s the case, you’ll need to launch a headless browser, such as Playwright or Puppeteer, that can render the page as a real user would. I’ve learned it’s always worth checking first which type of page you’re dealing with, as it’ll save you hours of troubleshooting.
Dealing with AJAX and JavaScript Rendering
Ever scrape a site and get an empty page back? That’s AJAX messing with you. Many sites load their data after the initial page load, often in the background. If you know where to look, you can sometimes tap into the same API endpoints that those AJAX calls use for web harvesting, without requiring rendering.
At other times, you’ll need to wait for the page to finish loading with a headless browser before retrieving your data. Either way, handling JavaScript rendering is a must if you’re targeting anything built with modern frameworks.
Handling Pagination and Infinite Scroll
Scraping the first page of results is easy, but what about the next 20? Most real scraping jobs involve some form of pagination or infinite scroll. For paginated sites, it’s often just a matter of finding the “next” button and following the link until there are no more. Infinite scroll takes more finesse; you have to simulate scrolling down the page until all the content loads, which can eat up memory if you don’t clean up along the way. Be sure to build in logic to detect when you’ve hit the end, so you don’t end up in an endless loop.
Techniques to Avoid Bot Detection
Bot detection is one of the biggest challenges in web scraping. When scrapers encounter 403 errors or CAPTCHA challenges, it typically indicates that the activity has been flagged as automated. Sites often detect patterns, such as rapid requests, missing headers, or signatures from headless browsers.
To reduce the risk, developers often rotate user agents, stagger requests, and rely on proxies or stealth tools. Platforms like Browserless simplify this process with built-in features such as session reuse, stealth mode, and CAPTCHA handling, making large-scale scraping far more reliable and efficient.
Ethical and Legal Considerations
Ethics matter when it comes to scraping. Just because scraping is technically possible doesn’t mean it’s always the right approach. It’s important to avoid collecting personal data, respect robots.txt files, and refrain from sending excessive requests that could burden a site.
A good guideline is to ask how the site owner would expect a bot to behave. At the end of the day, responsible scraping is about being a good web citizen.
What Web Scrapers Are Used For
Once web scraping begins, the use cases quickly multiply. From side projects to internal tools and time-saving workflows, scrapers in various programming languages can automate tedious tasks, freeing up time to focus on insights. Here are some of the most common ways web scrapers are used day to day:
- Price monitoring and comparison: Let your scraper do the price-checking for you. It's extremely helpful if you're in e-commerce, reselling, or simply trying to track fluctuations across competitors.
- Market research and competitive analysis: Instead of manually collecting product listings or scanning pages for updates, scrapers can quietly collect all that info in the background while you focus on analyzing it.
- News and content aggregation. Need to keep tabs on headlines or industry blogs? A scraper can pull the latest articles from all your favorite sources and drop them into a single, clean feed.
- Lead generation and contact scraping are key areas for sales and growth teams. Scrapers can collect public information, such as emails, names, and job titles, from directories or company websites, eliminating the need for manual copy-pasting into spreadsheets.
- Academic research and data journalism: If you're working on a study or building a dataset for a story, scrapers can help you grab structured info from websites that don’t offer APIs.
Data Scraping vs. Web Scraping
People often use “web scraping” and “data scraping” interchangeably, but they’re not quite the same thing. Here’s how we usually break it down:
What Is Web Scraping?
Web scraping involves extracting data from websites, primarily from their HTML content. Whether you're targeting blog posts, product listings, or stock tickers, the data lives on a web page, and you're using tools like Puppeteer, Playwright, or BeautifulSoup to extract it. It’s great when you’re dealing with online content that’s publicly accessible but doesn’t come with a convenient API.
What Is Data Scraping?
Data scraping goes beyond just websites. It involves extracting information from various sources, including PDFs, Excel sheets, CSV files, APIs, and local data. In many cases, a website may only provide partial information, with the rest stored in downloadable formats, such as PDFs or JSON feeds. Put simply, if data is being collected in an automated way, regardless of format, that’s data scraping.
When You Use Both
In most real-world projects, you end up doing both. You scrape structured product details from a website (web scraping) and then enrich them with pricing information pulled from an internal API or a spreadsheet (data scraping).
The combo is powerful, especially when working on tasks such as market research, lead generation, or report automation involving real estate listings. Once you see how they work together, it really unlocks some cool possibilities.
The Benefits of Using Browserless for Web Scraping
If you've ever tried to manage your own headless browser infrastructure, you know how messy it can get from browser crashes to memory leaks to managing concurrency. That’s exactly where Browserless shines as a powerful web scraper. It takes care of the hard stuff so you can focus on actually extracting the data you need.
- No browser setup required: You don’t have to install, manage, or maintain headless browsers. Browserless handles all the infrastructure for you, saving hours of DevOps hassle.
- Easy to scale: Whether you’re making requests via REST, GraphQL, or integrating into a BaaS architecture, scaling up with Browserless is simple and efficient.
- Stealth mode to avoid bot detection: Built-in stealth features help you get around anti-bot systems that would normally block scrapers using headless tools like Puppeteer or Playwright.
- Built-in extras: Out of the box, you get CAPTCHA solving, session reuse, automatic retries, and full proxy support. It’s like having your own Swiss Army knife for scraping.
- Works with your favorite tools: Whether you’re building flows with LangChain, automating browser tasks with Puppeteer, or simply hitting it from a REST API, Browserless integrates seamlessly.
Conclusion
Web scraping is all about saving time and unlocking insights that would be impossible to gather manually, from price monitoring to competitive research and beyond. The key is keeping scrapers reliable and efficient, without getting stuck in endless fixes. That’s where Browserless comes in: it handles scaling, stealth, and setup so you can focus on the data, not the headaches. Ready to simplify your workflow? Try Browserless for free and see the difference it makes.
FAQs
What is web scraping, and how does it work?
Web scraping is the process of extracting data from a web page and turning it into a structured format that’s easier to work with. A web scraper typically sends HTTP requests to a site, downloads the page’s HTML code, and then parses out the specific data you want, like prices, product details, or contact information. Some web scraping tools can even act like a browser, rendering JavaScript so you can scrape dynamic sites. At its core, web scraping is about making the messy internet into clean, usable data.
What’s the difference between web scraping and data scraping?
The terms are closely related, but they’re not identical. Web scraping focuses on pulling data from websites, usually HTML-based content across multiple web pages. Data scraping is broader; it can pull information from PDFs, CSVs, APIs, or local files, not just the web. Think of web scraping as one piece of the larger data collection process. Both are utilized in web scraping applications, including lead generation, market research, and academic research.
What are some common uses of web scraping?
There are numerous practical web scraping applications, and they are prevalent in almost every industry. Some of the most common include:
- Price monitoring and comparison for e-commerce websites.
- Market research and competitor analysis for businesses trying to track market trends.
- News monitoring and aggregation from blogs or news sites.
- Lead generation and contact scraping for sales and recruiting teams.
- Academic research or sentiment analysis projects that require large datasets from publicly available data.
Is web scraping legal?
This is one of the biggest questions people have: Is web scraping legal? The short answer is: it depends. Scraping publicly available information is generally safer, but website owners may restrict it in their terms of service. Sending too many requests to a site can also get your IP address blocked. Ethical scraping typically involves targeting publicly available data, adhering to robots.txt guidelines, and avoiding sensitive or private information. Many market research companies and business intelligence platforms rely on web scraping; however, it is essential to always check the rules before scraping sites.
What’s the best way to make web scraping efficient?
The best scrapers don’t just grab data; they do it efficiently, and web scraping is used to achieve this. This involves utilizing the appropriate scraping programs or bots, refining raw data into a structured format, and minimizing wasteful memory allocation during processing. For dynamic sites, a web scraping API can make efficient data extraction much easier than trying to parse complex, unique HTML site structures. Adding techniques like proxy rotation, session reuse, and proper garbage collection in your scripts also prevents crashes when your web scrapers work on large jobs. With the right scraping tools, you can collect data across thousands of pages without burning resources or running into blocks.