
What was the goal of your automation?
We decided to scrape the Irish electrical grid's public real-time dashboard to help create awareness around how Ireland is a leading country in wind power generation.
What were the results?
Our Twitter account @IrishEnergyBot now has 2,000 followers receiving a daily report on how much wind generation there was on the Irish electric grid in the last 24 hours. Over the past ~18 months wind has met ~33% of Irish electrical demand on average. On windy days it regularly goes as high as 75%! We're #2 in the world. Only Denmark has more wind power.
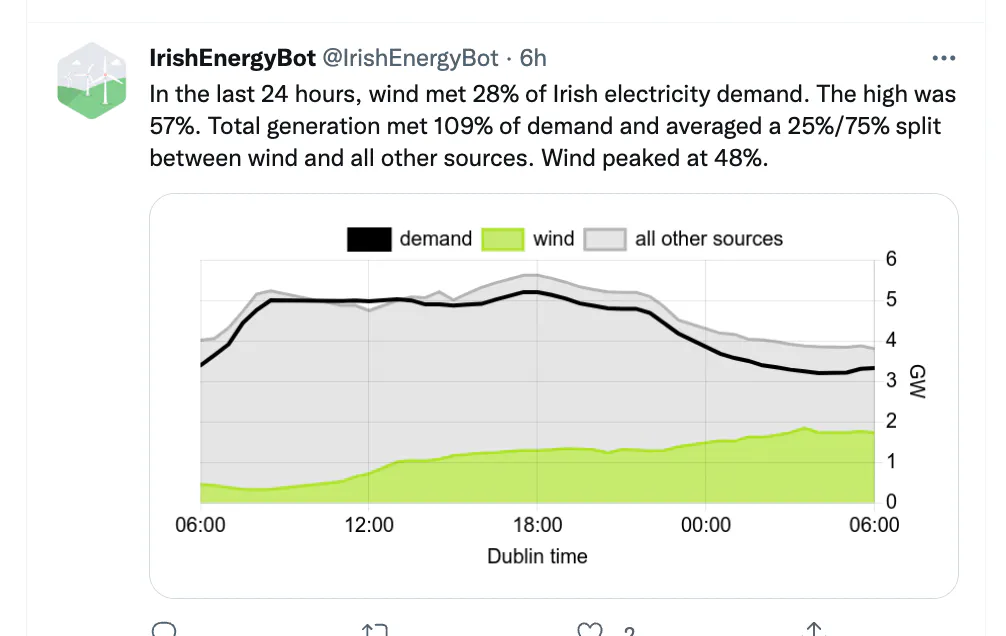
Why did you choose Browserless for automation?
@IrishEnergyBot scrapes its data from a free, public dashboard provided by Ireland's electrical grid operator. Because the dashboard loads data dynamically after the initial page load, a modern browser with JavaScript is required.
Thanks to Browserless I can keep my puppeteer script in a simple, low-maintenance serverless environment. The connection is fast and reliable and since I need just a few minutes of browser time each month, usage-based pricing works out great.
Browserless is an essential component of @IrishEnergyBot that I just never have to worry about.
import * as _ from "underscore";
import puppeteer = require("puppeteer");
const TIMEOUT_MS = 10000;
// or "roi" or "ni".
const REGION = "all";
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: `wss://chrome.browserless.io?token=${process.env.BROWSERLESS_TOKEN}`,
});
try {
const scrapedData = await scrape(await browser.newPage());
console.log(JSON.stringify(scrapedData, undefined, 2));
} finally {
await browser.close();
}
})();
async function scrape(page: puppeteer.Page) {
// data frequently fails to load: empirically, if it hasn't loaded in the
// first ~10s then we may as well fail.
async function impatientGoto(url: string) {
await page.goto(url, {
waitUntil: "networkidle2",
timeout: TIMEOUT_MS,
});
}
async function impatientWaitForSelector(selector: string) {
await page.waitForSelector(selector, {
timeout: TIMEOUT_MS,
});
}
// figures are contained in various divs, all with the class .stat-box. there
// isn't a good way to find the ones we want without inspecting their text
// content. this function extracts the number from the "stat box" under the
// specified parent containing the specified phrase.
async function extractStatBoxFigure(parent: string, keyPhrase: string) {
const selector = `${parent} .stat-box`;
await impatientWaitForSelector(selector);
const statBoxesTextContents = await page.$$eval(selector, (elements) => {
return elements.map((element) => {
return element.textContent || "";
});
});
const matchingStatBox = _.find(
statBoxesTextContents,
(s) => s.toLowerCase().indexOf(keyPhrase) >= 0
);
if (!matchingStatBox) {
throw new Error(`no stat box found containing "${keyPhrase}"`);
}
return extractFirstNumber(matchingStatBox);
}
impatientGoto(`https://www.smartgriddashboard.com/#${REGION}/demand`);
const demand_mw = await extractStatBoxFigure("#demand", "system demand");
impatientGoto(`https://www.smartgriddashboard.com/#${REGION}/generation`);
const gen_mw = await extractStatBoxFigure("#generation", "system generation");
impatientGoto(`https://www.smartgriddashboard.com/#${REGION}/wind`);
const wind_mw = await extractStatBoxFigure("#wind", "wind generation");
return { gen_mw, demand_mw, wind_mw };
}
// extracts the first integer from a (potentially messy) blob of text, e.g.:
// " LATEST SYSTEM GENERATION 4,994 MW " -> 4994
function extractFirstNumber(s: string) {
// remove commas, e.g. 4,800 -> 4800
const withoutCommas = s.replace(/,/g, "");
// https://stackoverflow.com/questions/8441915/tokenizing-strings-using-regular-expression-in-javascript
const tokens = withoutCommas.match(/[^\s]+/g) || [];
const firstNumber = _.find(
tokens.map((t) => parseInt(t, 10)),
(i) => !isNaN(i)
);
if (!firstNumber) {
throw new Error("no number found");
}
return firstNumber;
}
How to get started with Browserless
There are different ways to use our product.
-
Use our online debugger to try it out!
-
Sign up for a free account and get an API key. You have 6 hours of usage for free! After that, you can pay as you go, and only pay per second that you use!
-
You can self-host for development purposes by using our OpenSource browserless docker image
-
If you’ve already tested our service and want a dedicated machine for your requests, you might be interested in signing up for a dedicated account, this works best if your doing screencasting or have a heavy load of requests since you won’t be sharing resources.
If you’re using one of our hosted services; be that usage-based or capacity-based, just connect to our WebSocket securely with your token to start web scraping!