TL;DR
- A free proxy is an intermediary server you can use at no cost to route scraping or automation traffic through a different IP address.
- Browserless users can run a built-in residential proxy from the free plan without configuring a separate third-party proxy service.
- Testing found success rates below 5% across several public free proxy lists, with most returning 0%, so raw proxy lists need careful validation before you use them in scraping workflows.
- For headless browser automation, proxy type matters as much as proxy source because bot detection checks more than your IP address.
Introduction
Free proxies sound simple until you actually wire them into a scraper. You're usually trying to solve a few practical problems at once:
- Hiding your origin IP address.
- Reducing basic rate-limit failures.
- Testing geo-specific content.
- Keeping browser automation from being blocked after a handful of requests.
"Free" covers a wide range of options, from managed free plans with real infrastructure behind them to raw public proxy lists full of random free proxies you'll need to test yourself.
In this guide, you'll get a ranked breakdown of eight free proxy options for web scraping and browser automation.
We'll look at reliability, protocol support, setup effort, proxy locations, and whether each option is actually well-suited to Puppeteer, Playwright, and other headless browser workloads.
What is a proxy server?
Before you pick the best free proxy for your stack, it helps to define what you're actually routing through.
A proxy server is an intermediary server between your code and the target website. Instead of your request going directly from your machine to https://example.com/products, it goes through another IP address first.
A basic proxy request looks like this:

The target website sees the proxy's IP address, not your server's original IP address, which can help with geo-targeting, load balancing across IPs, accessing geo-blocked content for legitimate testing, and reducing basic IP-based rate limits.
For scraping, you'll usually see three proxy types:
- Datacenter proxies - Fast, cheap, and hosted in cloud or data center networks. They're useful for simple web scraping tasks, but easier for anti-bot systems to fingerprint.
- Residential proxies - Routed through ISP-assigned IPs associated with real user networks. They're usually better for protected sites, browser automation, ad verification, market research, and scraping Google or e-commerce pages.
- Rotating proxies - A proxy service that changes the exit IP across requests or sessions. They're useful when you need to spread requests across a pool instead of hammering one IP address.
You'll also see protocol differences:
- HTTP and HTTPS proxies - Best for standard web traffic through the HTTP protocol
- SOCKS4 and SOCKS5 proxies - Lower-level socks proxies that can handle more traffic types, including browser automation and non-HTTP connections.
What's the difference between a free proxy list and a freemium proxy service?
A free proxy list is a public list of proxy IPs and ports. These lists are usually scraped from around the web, refreshed on a schedule, and made available through a table, download, or proxy scraper API.
A row might look like this:
198.51.100.22:8080
203.0.113.14:3128
192.0.2.88:1080
The problem is that everyone else can use the same free proxy IPs. That means slow speeds, shared proxies, blacklisted IPs, unknown operators, and weak reliability.
A freemium proxy service works differently. You get a limited allocation from a real proxy provider, usually with account-based access, usage limits, and better infrastructure. Browserless, Webshare, and Oxylabs fit that model in different ways.
That distinction sets up the ranking below: managed free tiers come first because they're usually better for automated scraping, while public free proxy lists are more useful for testing, experiments, and fallback workflows.
The 8 best free proxies for web scraping and browser automation
Now that the categories are clear, the list of the best free proxy services runs from the most integrated option to the most basic. Each entry includes key features, trade-offs, and a pros and cons table so you can pick the best free proxy server for your workload rather than the biggest-looking proxy list.
1. Browserless
Best for: Web scraping and headless browser automation with Puppeteer or Playwright
Browserless is a cloud headless browser platform with a built-in residential proxy available to all users. The free plan includes 1,000 units/month, no credit card required, and residential proxy usage consumes 6 units per MB of data transferred.
Browserless isn't a public free proxy list. You're not copying random free proxy servers into your scraper; you add proxy=residential to your Browserless connection URL and run the request through a managed residential proxy pool.
Browserless's residential proxy supports the following configuration options:
- Country-level routing with
proxyCountry. - Sticky sessions with
proxySticky. - Locale matching on stealth endpoints with
proxyLocaleMatch. - Proxy presets such as
px_gov01for government sites andpx_ipv6for Google-family domains.
For Puppeteer, that looks like this:
import puppeteer from "puppeteer-core";
const TOKEN = "YOUR_API_TOKEN_HERE";
const browserWSEndpoint =
`wss://production-sfo.browserless.io?token=${TOKEN}` +
`&proxy=residential` +
`&proxyCountry=us` +
`&proxySticky=true`;
const browser = await puppeteer.connect({ browserWSEndpoint });
const page = await browser.newPage();
await page.goto("https://ip-api.com/");
console.log(await page.title());
await browser.close();
For Playwright, the pattern is the same:
import playwright from "playwright-core";
const TOKEN = "YOUR_API_TOKEN_HERE";
const pwEndpoint =
`wss://production-sfo.browserless.io/chrome/playwright?token=${TOKEN}` +
`&proxy=residential` +
`&proxyCountry=us`;
const browser = await playwright.chromium.connect(pwEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://ip-api.com/");
await browser.close();
City-level targeting with proxyCity is available, but it requires the Scale plan with 500k+ units/month. Browserless also supports third-party proxies through externalProxyServer.
For sites where a proxy alone isn't enough, consider BrowserQL. BrowserQL is a stealth-first browser automation tool that uses GraphQL mutations to navigate, interact, extract data, solve CAPTCHAs, and route traffic through built-in or third-party proxies.
Key features
- Multiple REST APIs for different use cases, providing extensive data extraction capabilities.
- Built-in residential proxy with no third-party account needed.
- Country-level routing via ISO 3166 codes.
- Sticky session support to maintain a consistent IP.
- Locale matching on stealth endpoints.
- Proxy presets for government and Google-family domains.
- Compatible with Puppeteer and Playwright.
- Third-party proxy support through
externalProxyServeron paid plans (Prototyping and above). - 1,000 free units/month with no credit card required.
| Pros | Cons |
|---|---|
| Natively integrated with Browserless browser sessions | Proxy usage draws from your unit balance at 6 units/MB |
| Residential IPs are a better default than datacenter proxies for protected browser workloads | Free tier is limited to 1,000 units/month total |
| Sticky sessions and locale matching are available through URL parameters | City-level targeting requires the Scale plan |
| Works with Puppeteer, Playwright, BrowserQL, and REST APIs | Not a standalone proxy list or generic free proxy server |
Bottom line: Browserless is the most seamless option when your real problem is headless browser automation rather than collecting proxy IPs.
2. Webshare
Best for: Simple datacenter proxies for small scraping tests
Webshare's free plan gives you 10 datacenter proxies with no expiry. The free proxy server page also states that no credit card is required and that the free proxies support HTTP and SOCKS5.
Webshare is a good fit when you're validating scraper logic, testing request rotation, or running low-volume web scraping tasks that don't need residential proxies. It's not the right choice for high-volume production scraping on protected targets, but it's much more predictable than random free proxies from a public list.
A basic Python request looks like this:
import requests
proxy_url = "http://USERNAME:PASSWORD@p.webshare.io:80"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
response = requests.get(
"https://httpbin.org/ip",
proxies=proxies,
timeout=15,
)
print(response.status_code)
Key features
- 10 permanently free datacenter proxies.
- Up to 1GB/month on the free tier.
- HTTP and SOCKS5 support.
- No credit card required.
- Dashboard-based proxy management.
- Upgrade path to paid datacenter and residential proxies.
| Pros | Cons |
|---|---|
| Permanently free, not a trial | Only 10 proxies on the free tier |
| Cleaner than public proxy lists | 1GB/month data limit |
| HTTP and SOCKS5 support | Datacenter IPs are easier to block than residential IPs |
| Simple dashboard and API docs | Not natively integrated with headless browser sessions |
Bottom line: Webshare is a good free proxy service for request-level testing.

3. Oxylabs
Best for: Testing managed datacenter IPs before committing to paid proxy infrastructure
Oxylabs is primarily a paid proxy provider, but its datacenter proxy product includes 5 free IPs upon registration with no credit card required. The pricing page lists the free trial as 5 IPs, 5GB/month, US locations, and 24/7 support.
Oxylabs is useful when you want high-quality proxies for testing purposes without starting on a paid plan. The free allocation is small, but the infrastructure is managed, documented, and closer to premium proxies than to a public free proxy list.
Oxylabs also offers free trials for residential and dedicated datacenter proxies. Its residential proxy page lists 177M+ residential IPs and integrations for Selenium, Puppeteer, Playwright, Scrapy, and other tools.
Key features
- 5 free datacenter IPs on signup.
- 5GB/month traffic on the free datacenter allocation.
- US-based free IPs.
- No credit card required.
- Paid residential, mobile, ISP, and datacenter proxy products.
- Puppeteer and Playwright integration docs.
| Pros | Cons |
|---|---|
| Professionally managed proxy infrastructure | Free IPs are US-only |
| 5GB/month is useful for testing | Only 5 IPs |
| No credit card needed for the base free datacenter allocation | Mostly a path into paid plans |
| Strong upgrade path to residential and enterprise proxy services | More than many solo developers need |
Bottom line: Oxylabs gives you a small managed pool instead of a giant public list.
4. ProxyScrape
Best for: Accessing a frequently refreshed public proxy list through an API
ProxyScrape is closer to what many developers mean by a proxy scraper. Its free proxy list covers HTTP, SOCKS4, and SOCKS5 proxies, and the public page says proxies are updated every 5 minutes.
ProxyScrape also provides an API that returns free proxies with filters for protocol, country, timeout, anonymity, and more - an API access that makes it easier to plug a free proxy list into a script.
Key features
- Free proxy list with HTTP, SOCKS4, and SOCKS5 support.
- Refreshed every 5 minutes.
- API access for programmatic use.
- Filters for protocol, country, timeout, and anonymity.
- Downloadable proxy list output.
| Pros | Cons |
|---|---|
| API access makes integration straightforward | Public proxies are often slow or blocked |
| Supports HTTP, SOCKS4, and SOCKS5 | Potentially has low success rates |
| Frequent refresh cycle | No uptime guarantee on free proxies |
| Useful for building a proxy validation pipeline | Not suitable for production scraping without testing |
Bottom line: ProxyScrape is useful when you want raw inputs for your own proxy checker.
5. Geonode
Best for: Browsing a large free proxy list with advanced filtering
Geonode offers a free proxy list with filters for country, protocol, speed, anonymity level, uptime, and more. Its public proxy API response showed 8,338 total entries at the time of checking, with metadata such as protocol, country, latency, uptime, and last checked time.
The interface is easier to work with than many basic free proxy provider list pages. For debugging, testing, or building a free proxy provider list to feed into your own checker, that's useful.
Key features
- Large public free proxy list.
- Filters for country, port, protocol, speed, uptime, and anonymity.
- HTTP, HTTPS, SOCKS4, and SOCKS5 entries.
- Metadata-rich proxy entries.
- Paid residential proxy product available separately.
| Pros | Cons |
|---|---|
| Advanced filtering makes proxy selection easier | Free list reliability can be very low |
| Large pool of proxy IPs | Free entries still need validation |
| Metadata includes latency and uptime fields | Public proxies may already be blocked |
| Good for testing proxy validation logic | Not a production proxy service by itself |
Bottom line: Geonode is good for filtering and exploration.
6. IPRoyal
Best for: A public proxy list with a fast refresh cycle
IPRoyal maintains a free proxy list covering HTTP, HTTPS, and SOCKS proxies. The list is refreshed every 10 minutes.
IPRoyal is convenient when you need no-sign-up access to fresh proxy candidates. Like other public lists, though, it's not the same as using IPRoyal's paid residential proxies, ISP proxies, datacenter proxies, or mobile proxies. The free list is best treated as an input to your own testing pipeline.
Here's an example validation flow:
import requests
candidate = "http://203.0.113.10:8080"
try:
response = requests.get(
"https://ipinfo.io/json",
proxies={"http": candidate, "https": candidate},
timeout=10,
)
print(response.status_code, response.text[:200])
except requests.RequestException as exc:
print("proxy failed:", exc)
Key features
- Free HTTP, HTTPS, and SOCKS proxy list.
- Refreshed every 10 minutes.
- No signup required for the public list.
- Multiple countries represented.
- Paid proxy products available separately.
| Pros | Cons |
|---|---|
| Fast refresh cycle | Still a public proxy list |
| Supports multiple protocols | Reliability varies heavily |
| Easy to access | No managed browser integration |
| Useful for testing and fallback pools | Not suitable for production scraping on its own |
Bottom line: IPRoyal keeps the public-list model simple.
7. Free Proxy List
Best for: Quick, no-signup access to HTTP and HTTPS proxy candidates
Free Proxy List is one of the most well-known free proxy list sites. It offers HTTP and HTTPS proxies with filters such as anonymity, HTTPS support, country, and port, and its main page says the list is updated every 30 minutes.
The upside is convenience. You can open the page, filter, copy a few free IPs, and test them in a script. The downside is reliability, as you can never be certain of success.
Key features
- No signup required.
- HTTP and HTTPS proxies.
- Filters for anonymity, HTTPS support, country, and port.
- Updated every 30 minutes.
- Simple copy-and-test workflow.
| Pros | Cons |
|---|---|
| Very easy to access | Independent testing found a 0% success rate in one sample |
| Familiar table format | No SOCKS support on the main list |
| Useful for quick experiments | Location data can be inaccurate |
| No account or API key needed | Not suitable for production web scraping |
Bottom line: Free Proxy List is fine when you need quick test inputs.

8. hidemyname
Best for: Granular filtering across a large public proxy list
This option provides a free proxy list with working proxies tested for speed, location, and anonymity. The public hidemyname page supports export to TXT, CSV, or API access by request, and country pages show fields such as IP address, port, country, city, speed, type, anonymity, and latest update.
That makes hidemyname useful when you care about proxy type and location before you test the IP yourself. For example, you can filter for SOCKS5 proxies in a specific country, then run your own validation against your target site.
As with every public free proxy list, the table is only the start. You still need to test speed, uptime, protocol support, and whether the IP is already blocked by your target.
Key features
- Free proxy list with speed, location, and anonymity metadata.
- HTTP, HTTPS, SOCKS4, and SOCKS5 coverage.
- Country and city-level fields.
- Export options for TXT and CSV.
- API access available by request.
| Pros | Cons |
|---|---|
| More granular filtering than basic lists | Public proxy reliability still varies heavily |
| City and speed fields are useful for testing | API access is not as self-serve as some alternatives |
| Broad protocol support | Not a managed proxy service |
| Good for building a candidate pool | Security caveats still apply |
Bottom line: hidemyname helps you find and filter candidates.
What proxy type should you use for headless browsers?
Once you move from simple HTTP requests to headless browsers, the proxy decision gets stricter.
A basic scraper might only need a free HTTP proxy:
requests.get("https://example.com", proxies=proxies)
A browser automation script has more moving parts:
await page.goto("https://example.com/login");
await page.click("button[type='submit']");
await page.waitForSelector(".dashboard");
The site can inspect your IP address, browser fingerprint, TLS behavior, cookies, headers, language, timezone, interaction timing, and session consistency. You're not invisible just because traffic goes through a proxy.
For headless browsers, use these defaults:
- Use datacenter proxies for simple targets - They're fast and cheap, but more likely to be blocked on protected sites.
- Use residential proxies for anti-bot-protected pages - Residential proxies route through ISP-assigned IPs, which are usually a better default for browser automation on e-commerce, travel, social media, and logged-in workflows.
- Use rotating proxies for high-volume collection - Rotation spreads requests across a pool, but you still need session rules so one login flow doesn't jump between unrelated IPs.
- Use sticky sessions for stateful flows - If a target tracks cookies, cart state, login state, or checkout state, keep a consistent IP for that session.
- Use SOCKS5 when you need protocol flexibility - SOCKS5 can handle more traffic types, while HTTP and HTTPS proxies are fine for standard web scraping.
- Use native integration when possible - Browserless lets you add proxy behavior directly to the browser connection URL, which avoids manual proxy authentication setup inside each browser context.
The proxy server market is also getting more attention: Zion Market Research estimated the global proxy server market at USD 4.29 billion in 2023 and projected it to reach USD 7.59 billion by 2032 at a 7.5% CAGR.
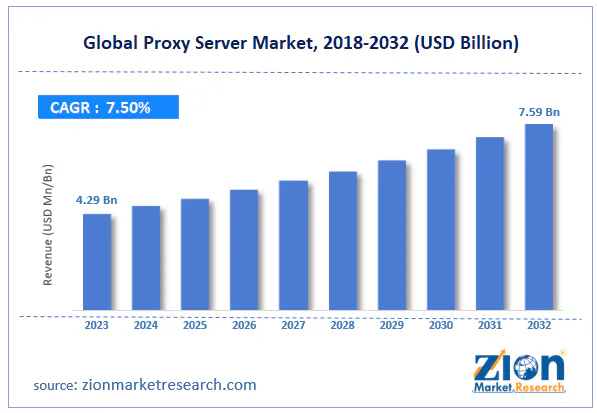
That growth tracks what developers are already seeing. Bot detection is stricter, regional content varies more often, and reliable automation increasingly depends on pairing the right proxy type with browser-level behavior.
When a proxy alone isn't enough, combine residential proxies with stealth browser configuration. In Browserless, that usually means escalating from Puppeteer or Playwright with proxy=residential to BrowserQL for stricter targets that need CAPTCHA handling, stealth endpoints, and fingerprint mitigation.
Free proxy limitations to know before you start
The list above gives you options, but free proxies still come with sharp edges. The main pattern is simple: managed free tiers are useful for testing real workflows, while public proxy lists are mostly raw material for experiments.
The biggest limitation is the success rate. ScrapeOps tested more than 1,200 free proxies across four providers and found that success rates averaged below 5%, with most providers returning 0% in focused tests.
Common failure modes include:
- Low uptime - Many free proxy servers are dead before your script reaches them.
- Slow speeds - Shared proxies can be overloaded by other users.
- Bad location data - A proxy listed as one country or city may resolve somewhere else.
- Security risk - Unknown operators can log, modify, or inspect traffic.
- Blacklisted IPs - Public proxies are often already burned on major sites.
- Weak session consistency - Random rotation can break logins, carts, and stateful flows.
- No support - Most public free proxy lists give you IPs, not reliability guarantees.
A safer workflow is:
- Start with a managed free plan when possible.
- Use public lists only for testing or non-sensitive scraping tasks.
- Validate every proxy against your target before using it.
- Avoid sending credentials, tokens, personal data, or customer data through unknown proxies.
- Move to paid infrastructure when the workflow becomes production-critical.
Free proxies are useful for learning, validating assumptions, and testing failure handling. For production scraping, you'll usually want reputable providers, paid plans, residential proxies, or a browser automation platform with proxy support built in.
Conclusion
The best free proxy depends on what you're trying to do.
If you're running headless browsers, Browserless is the cleanest starting point because the residential proxy is built into the same platform you use for Puppeteer, Playwright, BrowserQL, and REST APIs. You get 1,000 free units/month with no credit card required, and you can enable the residential proxy with proxy=residential instead of setting up a separate free proxy service.
If you just need simple proxy IPs, Webshare and Oxylabs give you managed free allocations that are more predictable than public lists.
If you're building your own proxy scraper or validation pipeline, ProxyScrape, Geonode, IPRoyal, Free Proxy List, and HideMy.name give you raw proxy candidates to test.
For web scraping and browser automation, a managed free tier beats a random public proxy list almost every time. Sign up for Browserless for free to run a built-in residential proxy directly with your existing Puppeteer or Playwright setup, without adding another proxy provider, dashboard, or authentication layer.
Best free proxy FAQs
What is the best free proxy for web scraping?
For browser-based scraping, Browserless is the best fit because its free plan includes access to a built-in residential proxy that works directly with Puppeteer, Playwright, BrowserQL, and REST APIs. For simple request-level scraping, Webshare and Oxylabs are good managed free-tier options.
Are free proxies safe to use?
Free proxies are safe only when you trust the provider and understand the limits. Public proxy lists are riskier because unknown operators may run the servers, log traffic, or modify responses. Avoid sending credentials, session cookies, API keys, or personal data through random free proxies.
What is the difference between a free proxy list and a free proxy server?
A free proxy list is a directory of proxy IPs and ports. A free proxy server is the actual intermediary server your traffic routes through. Public lists give you candidates to test, while freemium proxy services give you managed proxy access with account controls and usage limits.
Can I use a free proxy with Puppeteer or Playwright?
Yes. With a normal proxy provider, you usually configure the proxy at browser launch and then handle authentication in your browser context. With Browserless, you can add proxy=residential and optional parameters such as proxyCountry=us directly to the connection URL.
Why do free proxies get blocked so quickly?
Public free proxies are shared by many users. That means the same IP address may be used for scraping, spam, credential attacks, and other unwanted activity before you ever touch it. Target sites detect that behavior and block the IP, which is why public proxy list success rates are often low.