Key Takeaways
- Browserless + n8n + Claude enables fully automated, AI-enhanced workflows that go beyond scraping by interpreting data and producing actionable outputs like pricing suggestions or lead scores.
- n8n serves as the central orchestrator, allowing you to visually build workflows that connect Browserless scraping endpoints with Claude or ChatGPT API calls, Slack alerts, Google Sheets, and CRMs.
- Market monitoring and lead qualification can be tailored to each use case by adjusting prompt structure, data sources, or routing logic without changing the core automation flow.
Introduction
n8n is a low-code automation platform that lets you build workflows by connecting APIs, databases, and tools through a visual editor. Browserless offers scalable headless browser sessions for scraping and interacting with dynamic websites. Claude and ChatGPT add an AI reasoning layer to summarize, classify, or make suggestions based on the data you have collected. These tools automate steps and enable workflows supporting smarter decisions when used together. This article presents three practical examples: scraping marketplace listings to inform pricing strategies, analyzing company websites for lead qualification, and summarizing job board trends to guide hiring decisions.
Setup Connecting Browserless, n8n, and AI Agents
Signing up for Browserless
To get started, you’ll first need a Browserless account. Once signed in, go to your dashboard to find your API token.
This token authenticates your requests and gives you access to headless browser sessions via REST or BrowserQL.
The REST setup is more than enough if you plan to use the standard /content or /scrape endpoints. Copy your API key and prepare it. You’ll use it directly in n8n’s HTTP Request node.
Connecting Browserless API with n8n
Inside n8n, you can trigger a Browserless task using a simple HTTP Request node.
The n8n HTTP requests node handles most of the configuration; you only need to select a few things. First, you need to choose the type of request to set it as a post request, like below:
After setting the method, you need to get your Browserless URL. This is easy; you can pull it from our BQL Editor. As a side note, you can use our online IDE to test your BQL-based queries and see the output before importing them into n8n.
To streamline this even more, once you have a query working in our IDE, you can export a cURL version of the query.
Then copy the cURL request from our IDE and paste it directly into the n8n cURL import feature on the HTTP request node.
You will see a pop-up where you paste your cURL code into the field below.
All your parameters and credentials should be moved to the HTTP request node.
By default, this n8n cURL import feature will hardcode your API key. While this will function, n8n has built-in credential functionality to make it easier to use API keys when building out future workflows that you can reuse.
Go to the authentication drop-down in your HTTP node, select Header Auth.
In the name and value fields, enter the token value, which should appear as follows.
@@image(filename="n8n-set-token", alt="Set n8n token")
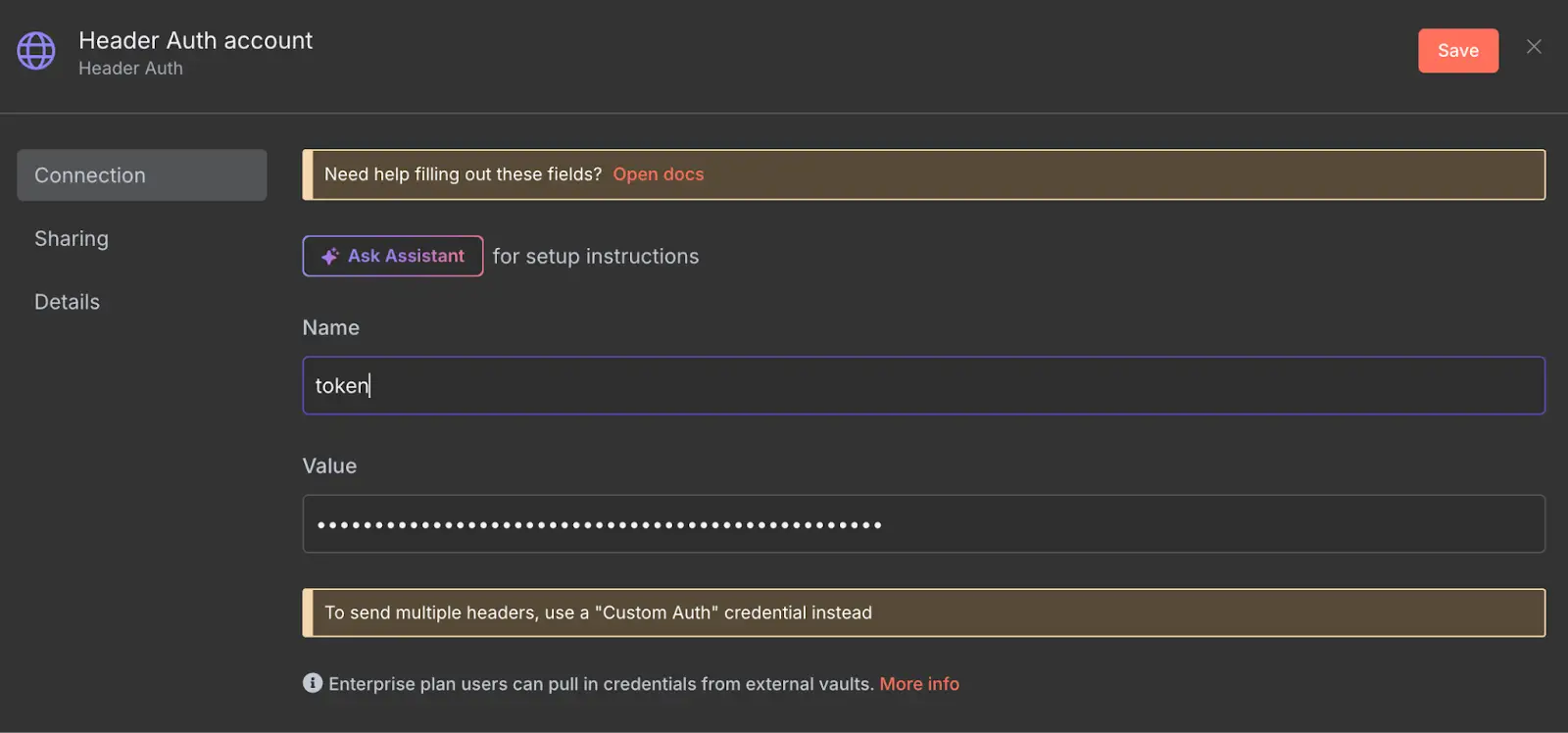
Now, click 'Save,' and your credentials will be saved in your n8n account for future workflows. As we pass the API key via the n8n credential feature, we must delete the token parameters from the query parameters section. So Browserless HTTP nodes should be configured in the following way:
Adding AI Agents API Keys
You can add a model like Claude or ChatGPT to use your AI agent workflow. You will need to sign up for their respective APIs; the n8n documentation shows you how to connect these for OpenAI and Anthropic.
These AI nodes in n8n will be placed immediately after the Browserless HTTP request node, allowing it to process the scraped or extracted data.
So, to recap, you now have:
- Signed up for Browserless and got your API key
- Connected your Browserless credentials to n8n
- Learnt how to configure the n8n HTTP request node
- Connected either ChatGPT or Claude to our n8n account
With all that configuration done, we can now dive into building AI augmented automation flows in the next sections.
Use Case 1: Scrape Marketplace Listings + AI Pricing Recommendations
Tracking product prices across marketplaces like eBay, Amazon, or Etsy can be time-consuming if done manually. With n8n, you can automate this task using a scheduled workflow that scrapes listings with Browserless and passes the results to Claude for price analysis. This helps surface actionable pricing suggestions based on current market trends, all within a few clicks.
Here is what our flow looks like inside of n8n:
Manually tracking product prices across marketplaces like eBay can be time-consuming and let’s be honest, it’s prone to errors and outdated data.
With n8n, Browserless, and ChatGPT, you can build a fully automated pricing intelligence workflow that scrapes live listings, cleans the data, and generates AI-powered pricing strategy reports no spreadsheets, no browser tabs.
Here’s how it works in n8n (see the attached snapshot for reference):
- Trigger: A simple Test Workflow click or a scheduled Cron node.
- HTTP Request Node (Browserless): Calls the
/bqlendpoint to scrape iPhone listings from eBay. For simplicity, we limited the response to 30 listings, but you can expand this and store additional data in memory or external DBs. - Code Node: Cleans and reshapes the response. Here's the logic:
const results = items[0].json.data.results.slice(0, 30);
const cleanedListings = results.map((item) => {
const listing = {
title: item.title?.[0]?.title || null,
price: item.price?.[0]?.price || null,
shipping: item.shipping?.[0]?.shippingCost || null,
buyType: item.buyType?.[0]?.type || null,
location: item.location?.[0]?.itemLocation || null,
condition: item.condition?.[0]?.condition || null,
seller: item.seller?.[0]?.sellerInfo || null,
link: item.link?.[0]?.url?.value || null,
};
Object.keys(listing).forEach((key) => {
if (listing[key] === null) {
delete listing[key];
}
});
return listing;
});
return [
{
json: {
listings: cleanedListings,
},
},
];
- AI Agent Node (ChatGPT): Takes the cleaned data and applies the following prompt:
You are an e-commerce pricing analyst. Based on the following JSON data of marketplace listings, generate a pricing strategy report for iPhones...
{{ JSON.stringify($json.listings, null, 2) }}
- Output: The AI returns a structured pricing strategy report, ready for Slack, email, or internal dashboards.
Why This Is Useful
This isn't just a scraper it's a pricing analyst in a box. The ChatGPT output included:
- Summary of pricing patterns, including how condition and seller rating affect prices.
- Breakdowns by model (e.g., iPhone 13 Pro Max or iPhone 8), showing price ranges and listing volumes.
- Competitive insights like whether certain sellers are underpricing and where opportunities exist for margin gain.
- Clear exclusions (e.g., "Shop on eBay" titles or items with no price) to avoid data noise.
Here’s an example excerpt from the AI-generated output:
iPhone 14 Pro Max – Very Good (Refurbished)
Price Range: $569.99 Listings: 1 Suggestion: Position competitively around the $560–$580 range for similar condition items from high-rated sellers
How This Can Be Extended
This workflow is flexible; you can swap in different marketplaces or product categories by changing the BQL query and tweaking the AI prompt. Since each part, like scraping, cleaning, and analysis, is separated in n8n, you can update one without affecting the rest.
It streamlines the jump from raw HTML to structured, meaningful output. Instead of manually parsing and analyzing CSV dumps, you get structured JSON piped directly into your AI layer. This provides you with insights quickly and ensures everything remains repeatable.
You can take it further by connecting the output to tools like Google Sheets, Slack, or your pricing engine. Trigger the flow from a schedule, a webhook, or a database update, whatever fits your stack. BQL eliminates a significant amount of scraping friction by handling dynamic content reliably, allowing you to focus on building smarter automations around the data.
Use Case 2: Scrape Company Websites + AI Lead Qualification
Manually qualifying leads based on company websites is tedious and doesn't scale well. Using n8n with Browserless and OpenAI, you can now automate this process end-to-end.
This workflow extracts company homepage content, feeds it into an AI model, and updates your Google Sheet with an ICP (Ideal Customer Profile) fit score and reasoning all without manual effort.
Here is what we are building:
@@image(filename="lead-scoring-ai-n8n-screenshot", alt="n8n AI Lead Qualifying Screenshot")
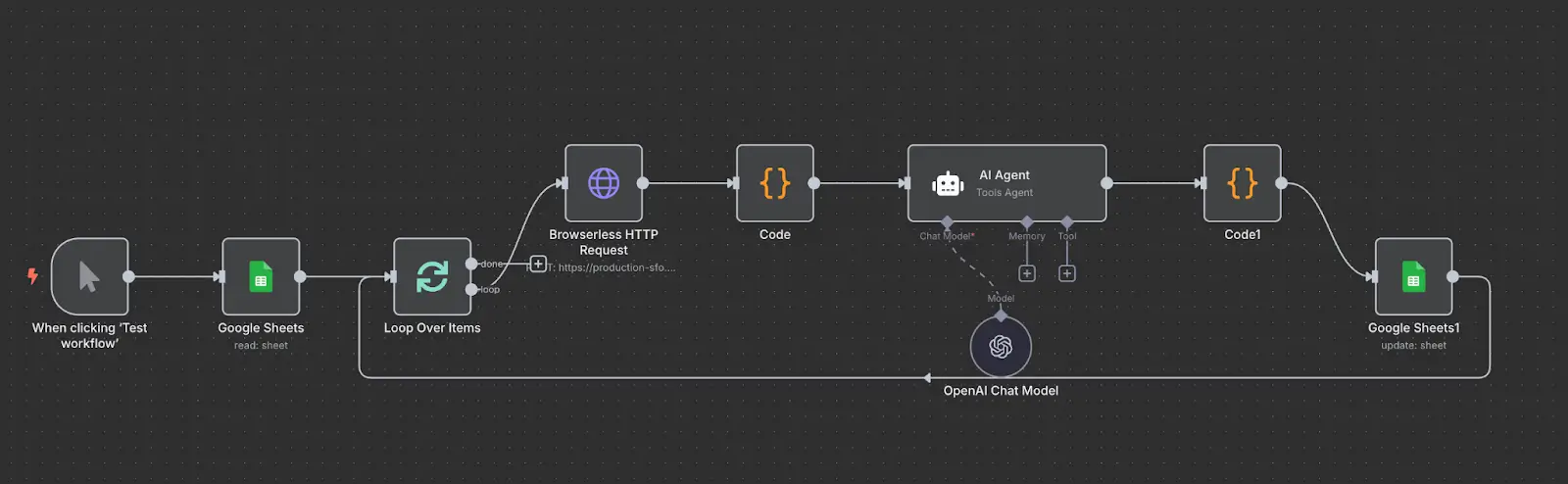
-
Trigger: The process starts with a list of company leads in a Google Sheet. Each entry includes a company name and URL.
-
Loop Over Items: Each company row is processed one at a time using the Loop Over Items node.
-
Scrape Homepage Content: A Browserless HTTP Request node hits the
/contentendpoint for each company URL, returning the page's clean HTML. -
Convert HTML to Markdown: A Code node strips scripts/styles and converts HTML to markdown with this function below:
function htmlToMarkdown(input) {
return input
.replace(/]*>[\s\S]*?<\/style>/gi, "")
.replace(/]*>[\s\S]*?<\/script>/gi, "")
.replace(/]*>(.*?)<\/h1>/gi, "# $1\n\n")
.replace(/]*>(.*?)<\/h2>/gi, "## $1\n\n")
.replace(/]*>(.*?)<\/h3>/gi, "### $1\n\n")
.replace(/]*>(.*?)<\/p>/gi, "$1\n\n")
.replace(/]*>(.*?)<\/strong>/gi, "**$1**")
.replace(/]*>(.*?)<\/b>/gi, "**$1**")
.replace(/]*>(.*?)<\/em>/gi, "*$1*")
.replace(/]*>(.*?)<\/i>/gi, "*$1*")
.replace(/]*>(.*?)<\/li>/gi, "- $1")
.replace(/<\/ul>/gi, "\n")
.replace(/]*>/gi, "\n")
.replace(/]*href="([^"]*)"[^>]*>(.*?)<\/a>/gi, "[$2]($1)")
.replace(/]*>(.*?)<\/code>/gi, "`$1`")
.replace(/]*>([\s\S]*?)<\/pre>/gi, "\n```\n$1\n```\n")
.replace(/]*>(.*?)<\/blockquote>/gi, "> $1\n")
.replace(/<\/?[^>]+(>|$)/g, "")
.replace(/\n{3,}/g, "\n\n")
.trim();
}
const inputHtml = $input.first().json.data.html.html;
const markdown = htmlToMarkdown(inputHtml);
return [{ json: { markdown: markdown } }];
- AI Classification: This markdown content is passed to an AI Agent node using OpenAI Chat. The AI is prompted with the following:
You are a B2B SaaS sales analyst. Below is a list of company homepage. Analyze the text content of the homepage to determine how well the company fits the following Ideal Customer Profile:
ICP Criteria:
- B2B SaaS company
- Offers a software platform, not a marketplace or physical product
- Sells to mid-sized to large enterprises
- Focused on productivity, data, or developer tools
Instructions:
Classify the company as one of: Strong Fit, Moderate Fit, Weak Fit, or Not a Fit.
For each classification, explain the reason in 2–3 sentences.
Return your answer as a JSON array:
[
{
"fit": "Strong Fit | Moderate Fit | Weak Fit | Not a Fit",
"reason": "Explanation based on the content"
}
]
Here is the data to analyze:
Company name: {{ $('Loop Over Items').item.json.Company }}
Company Domain: {{ $('Loop Over Items').item.json.URL }}
markdown: {{ $json.markdown }}
- Parse Agent Output: The AI response is parsed to extract
fitandreasonvalues using this Code node:
let rawOutput = $input.first().json.output;
// Remove trailing commas before closing brackets to fix malformed JSON
rawOutput = rawOutput.replace(/,\s*]/g, "]");
let parsedOutput;
try {
parsedOutput = JSON.parse(rawOutput);
} catch (err) {
throw new Error("Failed to parse output: " + err.message);
}
const fit = parsedOutput[0]?.fit || "";
const reason = parsedOutput[0]?.reason || "";
return [
{
json: {
icp_fit: fit,
icp_reason: reason,
},
},
];
- Update Google Sheet: The ICP Fit and Reasoning are written back to the original row using the Update Sheet node with the row ID.
The Google Sheet is now enriched with lead qualification data letting your sales team focus only on the highest-fit companies.
Once you’ve got the basic ICP scoring workflow running, there are some really powerful ways to build on it. For instance, you can make the AI’s scoring smarter by tweaking the prompt based on the type of company, maybe one version for EU startups, another for large US enterprises.
In n8n, that’s easy to do using Switch nodes. It gives you targeted lead scoring without having to duplicate everything just route each lead to the right criteria set.
One of the best upgrades we’ve found is using BQL (Browserless Query Language). Instead of scraping the whole page, which often includes noisy or irrelevant content, BQL lets you pull just what matters like the hero headline, nav links, or CTA text using simple CSS selectors.
You can feed that clean, structured content into the markdown converter before it hits the AI. The result? Way more consistent scores and reasoning you can trust.
And finally, don’t forget to close the loop. Leads marked as a strong fit can be automatically added to your CRM or paged to your sales team via Slack. You can even keep “not a fit” leads in a separate Airtable for review later.
Over time, you’ll start spotting patterns and when you do, you can go back and refine your prompts or BQL rules to make your scoring sharper. It’s like turning your AI into a mini sales assistant that continually improves with each cycle.
Conclusion
We’ve now walked through two hands-on use cases: scraping product listings with AI-assisted structuring and qualifying B2B leads by parsing company websites. In both, we used Browserless to reliably extract data from modern web pages, n8n to automate the workflow logic, and a language model to reason over the results. This setup enables you to seamlessly transition from raw HTML to clean, structured insights that can be easily integrated into your CRM, Google Sheets, or any downstream system. What stands out here is the adaptability of this stack. You’re not locked into a vertical or a data type; swapping a prompt, adjusting a selector, or rerouting an output is often all it takes to shift use cases. Browserless’s BQL takes the heavy lifting out of scraping. If you’re ready to try this for yourself, sign up for a Browserless account. It’s the quickest way to start building workflows that are reliable, modular, and actually fun to iterate on.
FAQs
How do I use Browserless with n8n?
You can use n8n’s HTTP Request node to call Browserless endpoints, such as/scrape or /content, passing in your API token and configuration as a POST request. The response can then be processed or routed in your workflow.
Can I integrate Claude or ChatGPT into an n8n workflow?
Yes. Use a generic HTTP node to call Claude’s or OpenAI’s API. You’ll send your prompt and scraped content as a JSON payload, then process the response inside n8n for routing or further automation.
What are smart automation workflows with AI?
Smart automation workflows combine data scraping and collection (Browserless), workflow logic (n8n), and reasoning (Claude or ChatGPT) to generate summaries, scores, or strategic recommendations automatically.
What’s the best way to qualify leads using AI?
Scrape company websites with Browserless, then feed the content into Claude with a prompt that checks against your Ideal Customer Profile. High-fit leads can be auto-saved to your CRM.