Imagine you're in a library and need to copy information from hundreds of books by hand. Now imagine having a digital assistant that can scan and extract exactly what you need in seconds. That's essentially what data scraping is - the automated extraction of valuable information from websites and digital sources at scale.
In this comprehensive guide, you'll learn what data scraping is, how it works, the tools involved, and how to do it safely and ethically. Whether you're a developer building data pipelines or a business analyst gathering market intelligence, understanding data scraping fundamentals is essential in today's data-driven world.
What is data scraping?
Data scraping is the automated process of extracting structured information from websites, applications, or other digital sources. Think of it as having a digital assistant that can visit web pages, identify the specific data you want, and collect it in a format that's easy to analyze and use.
Unlike manual copy-pasting, data scraping uses software applications to:
- Visit multiple web pages automatically
- Extract specific data points (prices, contact info, news articles, etc.)
- Format the data into structured formats like JSON, CSV, or Excel
- Handle large volumes of data efficiently
Data scraping consists of two main components:
- Crawler: The algorithm that navigates the web and finds URLs with the target data
- Scraper: The tool that extracts and formats the identified data, which we'll cover in this article.
Data scraping examples & use cases
While reading this article you've probably wondered, "what are some good use cases for web/data scraping?" Let's go over a couple of these use cases.
The first one that we will be talking about is my favorite - price monitoring. You can use price monitoring to keep track of prices and make sure you are finding the best deal. Who doesn't want to save money? I have written a previous blog post about scraping Amazon.com to monitor the prices of specific products. Companies can also use price scraping to see what competitors are pricing similar products. This provides them with the advantage of being able to provide optimal pricing for their products so they can obtain maximum revenue.
Contact scraping is another way data scraping is used. Many companies and individuals can scrape the web for contact information to use for e-mail marketing. A good example of this would be scraping locations like an online employee directory or a bulk mailing list. For example, we shared this method in the Google Maps scraping guide. This use case is very controversial and often requires permission to collect this type of data. If you have ever visited a website and given them access to your contact information in exchange for using their software, you have permitted them to collect personal data like your e-mail address and phone number.
The last use case we'll go over is news monitoring. Many individuals and companies can scrape news sites to stay current on stories and issues relevant to them. This could be especially useful if you are trying to create a feed of some type, or if you just need to keep up with day-to-day reports.
How does data scraping work?
Data scraping follows a systematic process that mimics how humans browse websites, but at scale and speed. Scrapers can take all the content on web pages or just the specific data that you want. In many situations, it is best to pinpoint the specific data you want so that the data scraper can quickly extract it. For example, in the Amazon web scraping blog post that I mentioned earlier, we look at pricing for office chairs. In that instance, we are only trying to identify the price of the chairs and the title of the item. That allowed the data scraper to swiftly filter out any unneeded clutter resulting in the script being run relatively fast.
The steps to scrape data typically go as follows:
1. URL Targeting
The scraper starts with a specific URL or list of URLs to visit. This could be a single product page, search results, or an entire website structure.
2. Page Loading
The scraper loads the HTML content of the target webpage. While simple HTTP requests can work for basic static content, using headless or headful browsers (like Chrome, Firefox, or Safari) is often better because many modern websites rely heavily on JavaScript to render their content. These sites may appear empty or incomplete when accessed via basic HTTP requests, as the data is dynamically loaded after the initial page load through JavaScript execution.
3. HTML Parsing
Once the page loads, the scraper analyzes the HTML structure to locate the specific data elements you want to extract.
4. Data Extraction
Using selectors (CSS selectors, XPath, or other targeting methods), the scraper pulls out the desired information.
5. Data Formatting
The extracted data is converted into your preferred format - typically JSON, CSV, or a database structure.
6. Output & Storage
Finally, the structured data is saved to a file, database, or sent to another application for further processing.
What Is a Data Scraper?
A data scraper is the software tool or application that performs the actual data extraction. Think of it as the "robot" that does the heavy lifting of visiting websites and collecting information.
Types of Data Scrapers
Web Scrapers: Extract data from websites and web applications API Scrapers: Collect data from application programming interfaces Social Media Scrapers: Gather posts, comments, and engagement data E-commerce Scrapers: Extract product information, prices, and reviews News Scrapers: Collect articles, headlines, and publication data
Popular Scraping Tools
- Puppeteer: Google's Node.js library for browser automation
- Playwright: Microsoft's cross-browser automation framework
- Browserless: Headless Chrome browser service for scalable scraping
- Beautiful Soup: Python library for parsing HTML and XML
Why Do People Use Data Scraping?
Data scraping serves numerous legitimate business and research purposes:
Business Intelligence
- Price Monitoring: Track competitor pricing in real-time
- Market Research: Gather industry trends and customer sentiment
- Lead Generation: Collect business contact information
- Competitive Analysis: Monitor competitor products and strategies
Research & Development
- Academic Research: Collect data for studies and analysis
- AI Training: Gather datasets for machine learning models
- Content Aggregation: Build news feeds and content databases
- Data Validation: Verify information across multiple sources
E-commerce & Marketing
- Product Research: Analyze market trends and customer preferences
- SEO Analysis: Study competitor keywords and content strategies
- Social Media Monitoring: Track brand mentions and sentiment
- Customer Feedback: Collect reviews and ratings from various platforms
Risks & Challenges of Data Scraping
While data scraping offers powerful capabilities, it comes with several challenges and risks:
Technical Challenges
- Anti-Bot Measures: Websites may block automated access
- Dynamic Content: JavaScript-rendered content can be difficult to scrape
- Rate Limiting: Too many requests can trigger IP blocks
- Data Structure Changes: Website updates can break scraping scripts
Security & Privacy Concerns
- Personal Data Exposure: Accidental collection of sensitive information
- Authentication Requirements: Some sites require login credentials
- Data Breach Risks: Storing scraped data securely
- Privacy Compliance: Ensuring GDPR, CCPA, and other regulations
Ethical Considerations
- Terms of Service Violations: Many websites prohibit scraping
- Server Overload: Excessive requests can impact website performance
- Data Misuse: Potential for collecting and using data inappropriately
- Intellectual Property: Respecting copyright and content ownership
Is Data Scraping Legal?
The legality of data scraping depends on several factors and varies by jurisdiction:
Legal Considerations
- Terms of Service: Violating website terms can have legal consequences
- Copyright Law: Scraping copyrighted content may infringe on rights
- Computer Fraud Laws: Some jurisdictions have anti-hacking statutes
- Data Protection Regulations: GDPR, CCPA, and similar laws apply
Ethical Guidelines
- Respect robots.txt: Check website scraping policies
- Rate Limiting: Don't overwhelm servers with requests
- Data Minimization: Only collect what you actually need
- Transparency: Be clear about how you'll use the data
- Consent: Obtain permission when possible
Best Practices
- Review Terms of Service: Always check website policies
- Use APIs When Available: Many sites offer official data access
- Implement Delays: Add pauses between requests (typically 1-5 seconds) to prevent accidental DDoS attacks. Without proper delays, rapid-fire requests can overwhelm a website's servers, causing performance issues or even taking the site offline for other users
- Monitor Impact: Ensure your scraping doesn't harm the target site
- Seek Legal Advice: Consult with legal professionals for complex cases
Web Scraping Tutorial: How to Do Data Scraping (Safely & Ethically)
Now that we know how a data scraper functions let's identify some preliminary steps that are needed before you try to scrape a website yourself. There are many cool tools and software applications out there that help with scraping websites. Because of this we will stay at a high level and focus on the basics.
First, you want to find the URLs you want to scrape. This might seem obvious, but it is a key factor and how well your data scrape will work. If the URL you give the scraper is even slightly incorrect the data you get back will not be what you want, or even worse, your scraper won't work at all. For instance, if you're trying to do a price monitoring data scrape you want to make sure that your URL goes to a relevant site like Amazon or Google shopping.
Secondly, you want to inspect the webpage ("F12" on most keyboards) to identify what your scraper needs to scrape. If we use the same Amazon price monitoring example, you could go to a search result page on Amazon, inspect that page, and locate where the price is in the HTML code.
Once you have that, you want to identify the unique tags that are around the price so you can use that in your data scraper. Some good tags would be div tags with IDs or very specific class names.
<div id="price">$1.99</div>
After finding the code you want to collect and use, you'll want to incorporate this into your data scrape. This could be writing a script with the IDs or class names that you found in the previous step or simply inputting the tags into scraping software. You'll also probably want to add supporting information to help when displaying your data. Sticking with our Amazon example, if you are collecting the price of office chairs on Amazon it would be nice to also have the title of the item to accompany the price.
Once you've specified the tags in your script or scraping application, you'll want to execute the code. This is where all the magic happens. Everything that we talked about in the above section about how data scrapers work comes into play here.
Hopefully, you now have the data you need to start building your application. Whether that be a dashboard of charts, a cool table, or a sweet content feed the data is yours to do with it what you like. Lots of times you may get data back that you don't expect. That is completely normal. Just like anything else in the engineering world, if one tiny thing is off it can often lead to things being incorrect. Don't get discouraged! Practice makes perfect and you will catch on.
Data scraping with Browserless
All the basics have been covered for scraping the web. Before we end, I want to mention a cool tool that allows you to do data scraping. Browserless is a headless Chrome browser as a service. You can use Browserless with libraries like Puppeteer or Playwright to automate web-based tasks like data collection. To learn more, make sure to visit the Browserless website where you can find blog posts, documentation, debuggers, and other resources.
Start using Browserless web automation for FREE
Key Benefits
- Scalability: Handle multiple scraping tasks simultaneously
- Reliability: Built-in error handling and retry mechanisms
- Performance: Optimized for speed and efficiency
- Integration: Works seamlessly with Puppeteer, Playwright
Data Scraping Example: Browser Automation with Puppeteer
In this example, we are going to do a simple data scrape of the Y Combinator Hacker News feed. For this, we will use two main tools, Puppeteer and Browserless. In the above paragraph, I mentioned these tools with corresponding links. I highly recommend you check them out before diving into the example.
Initial setup
Alrighty, let's get to it! We are going to start with the initial setup. Luckily for us, there aren't many dependencies we need to install. There's only one... Puppeteer.
npm i puppeteer
Once you've run that command you are good to go! 👍
Browserless setup
Let's look at how to set up Browserless real quick.
For starters, you'll need to set up an account. Once you get your account set up, you'll be directed to your Browserless dashboard.
Here you can find your session usage chart, prepaid balance, API key, and all of the other account goodies.
Keep your API key handy as we'll use that once we start writing our script. Other than that we are ready to start coding!
The code for scraping data
Ok now for the exciting part! Here is the code example:
const puppeteer = require("puppeteer");
const scrape = async () => {
const browser = await puppeteer.launch({ headless: false });
// const browser = await puppeteer.connect({ browserWSEndpoint: 'wss://production-sfo.browserless.io?token=[ADD BROWSERLESS API TOKEN HERE]' })
const page = await browser.newPage();
await page.goto("https://news.ycombinator.com");
// Here, we inject some JavaScript into the page to build a list of results
const items = await page.evaluate(() => {
const elements = [...document.querySelectorAll(".athing .titleline a")];
const results = elements.map((link) => ({
title: link.textContent,
href: link.href,
}));
return JSON.stringify(results);
});
// Finally, we return an object, which triggers a JSON file download
return JSON.parse(items);
};
scrape();
Lines 4 and 5 are very important in this example.
Line 4 uses Puppeteer when running your script. This is good for testing so you can view how the browser is interacting with your script.
Line 5 is the Browserless connection. This is where you can add your API key which will link up to your Browserless account and allow you to run your script with Browserless.
Make sure one of these two lines are commented out. You only need one. That is all you need for this example. Once things are installed and the code is implemented, you can open up your preferred command-line interface in your project and run node [insert name of js file here].
The output should be a JSON file with real-time titles and links from the Hacker News feed!
Web scraping without installing a library
If you don't want to install and run puppeteer on your machine or server, you can also use our /scrape REST API and if the site ahs very heavy bot-detection systems, you can use our /BQL endpoint which allows you to define a series of steps to automate or scrape. BQL will allow you to solve captchas, and comes with very convincing fingerprints and human-like behaviors.
Once you have an account, you can access our BQL IDE and start scripting your scraper.
Your query can be as simply as this
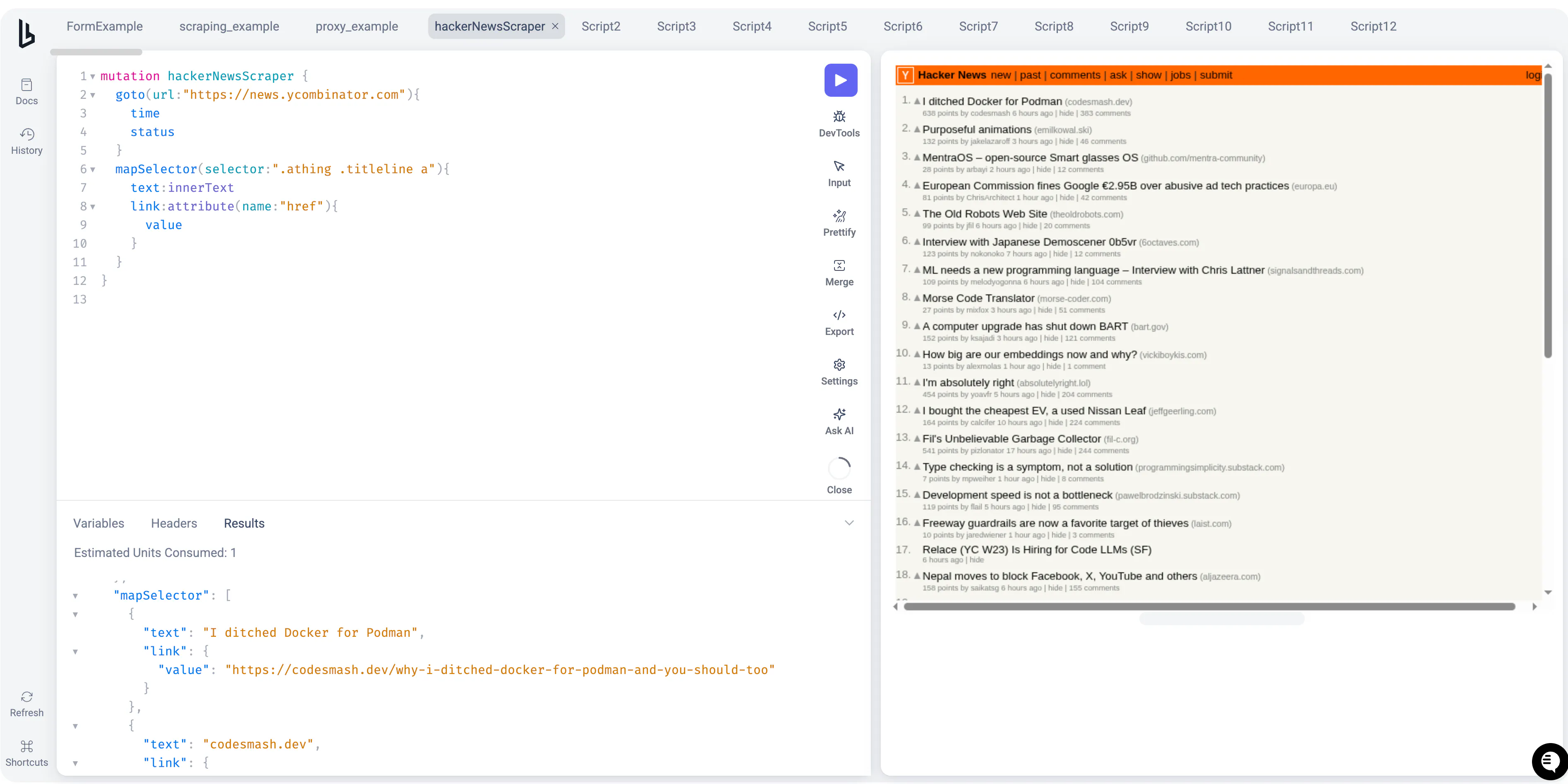
Once you run that and see it working perfectly on the right panel, you can click on the export icon and use the code for whichever language that suits you best!
I hoped this article on data scraping was intriguing and exciting. There are endless possibilities as to what you can accomplish with web and data scraping. I hope this sparks some cool projects for some of you.
Happy coding!
Important things/notes to keep in mind
- You can also try out the docker setup of browserless.io locally to increase the speed of prototyping and testing your scripts. Reach out to sales@browserless.io about licensing for self-hosting. You can learn more about it here
- Browserless.io has a beautiful setup for development. Make sure to connect to the locally installed browser via puppeteer if you connect to your actual browserless.io setup.
- You can always keep an eye on the analytics via your browserless.io dashboard