Introduction
Etsy is a leading marketplace for handmade goods, vintage items, and unique crafts, making it a valuable source for market research, price tracking, and trend analysis. Scraping Etsy allows access to product listings, prices, seller details, and customer reviews, but challenges like bot detection, dynamic content, and rate limits can make data extraction difficult. Many elements load via JavaScript, requiring advanced scraping methods to capture complete information. This guide provides a step-by-step approach to scraping Etsy efficiently using Puppeteer, Cheerio, or BQL, while avoiding detection and handling dynamic content.
Understanding Etsy’s Structure

How Etsy Organizes Its Data
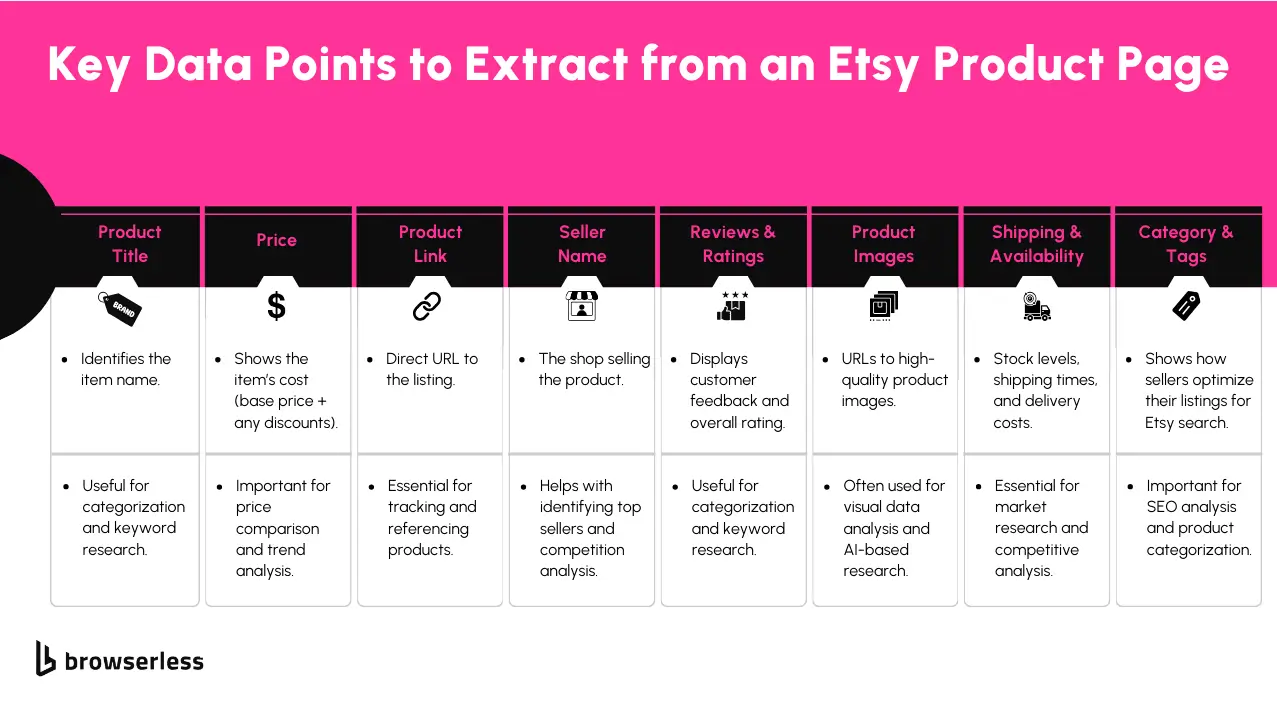
Etsy comprises a few main page types, each designed for a specific purpose. Search results pages show a list of products based on keywords, updating dynamically as you scroll. Product pages contain all the details about a specific item: title, price, images, shipping info, and seller details.
Seller pages act as digital storefronts, listing everything a particular shop offers, along with ratings, policies, and branding. If you're scraping Etsy, your approach will depend on which of these pages you're targeting and the type of data you need.
URL Patterns for Etsy Pages
Etsy’s URLs follow a predictable structure, which makes it easier to target the right data when scraping. Here’s how they’re organized:
- Search Results Pages: show multiple products based on a search term and load more items dynamically as you scroll.
- Example: https://www.etsy.com/search?q=candles
- URL Format: https://www.etsy.com/search?q=[keyword]
- Product Pages: contain details about a specific item, including its description, price, images, and seller info.
- Seller Pages: display all the products from a specific shop, as well as policies and branding.
- Example: https://www.etsy.com/shop/DenofSixCo URL Format: https://www.etsy.com/shop/[shop-name]
Each page is structured differently, so scraping it requires adjusting your approach. Search results rely on JavaScript to load new items, so standard HTML scraping won’t cut it. You’ll need a method to handle dynamic content.
Product and seller pages are more straightforward but use lazy loading for images and pricing updates. Knowing how these pages work will help you set up a scraper that gets the needed data.
Use Cases for Scraping Etsy
eCommerce Market Research
Finding out what’s trending and which products are selling well can be a game-changer for anyone looking to understand the marketplace. Scraping product listings, seller details, and customer reviews makes it easier to track popular items, pricing strategies, and what descriptions help drive sales. Whether researching a niche or looking at the bigger picture, having real data takes the guesswork out of spotting trends.
Price Comparison & Monitoring
Prices constantly change, especially with promotions, seasonal demand, and seller competition. Tracking these fluctuations helps set competitive prices, understand when discounts happen, and see how different shops position similar products.
Monitoring these changes can help fine-tune your pricing strategy if you sell online. For researchers and analysts, regular price tracking can uncover valuable insights into market behavior.
SEO & Product Trend Analysis
Sellers carefully consider product titles, descriptions, and keywords to appear in search results. Scraping listings makes it easy to analyze which keywords are used most, how they affect rankings, and what strategies seem to work best.
If you're trying to improve your listings, looking at top-performing products can give you ideas on structuring descriptions and tagging items. For trend tracking, comparing search results over time helps reveal what’s gaining traction and losing interest.
Academic & Business Research
Etsy’s data is useful for sellers, researchers, and businesses studying consumer behavior and market trends. Analyzing product availability, pricing, and customer reviews can help identify buying patterns and industry shifts.
Whether the goal is to study small business competition, track emerging trends, or explore new market opportunities, having structured data makes it easier to draw meaningful conclusions. If you’re considering launching a product, reviewing this data first can help you decide if there’s real demand.
Challenges of Scraping Etsy

CAPTCHAs & Bot Detection
Etsy has systems in place to detect and block automated scraping. If too many requests come from the same IP address or browsing behavior looks unnatural, the site may trigger a CAPTCHA or even block access entirely.
Some pages use anti-bot services that track browsing patterns and flag suspicious activity. To avoid disruptions, scrapers must mimic real user behavior, introduce delays between actions, and rotate IP addresses when necessary.
Rate Limiting & IP Bans
Etsy limits the number of requests that can be made quickly. If too many requests come from the same IP in a short timeframe, access may be restricted or blocked temporarily.
This is meant to prevent scraping at high speeds that could slow down the site. To work around this, scrapers need to space out requests, use proxy rotation, and monitor response headers for signs of rate limits before pushing too many requests at once.
Data Inconsistencies
Some product details on Etsy don’t load immediately when a page opens. Prices, stock availability, and other key data points might be retrieved asynchronously through JavaScript.
If a scraper only collects the initial HTML source, it could end up with incomplete or outdated information. Handling this properly requires a scraping method that can wait for JavaScript execution, such as using a headless browser or an API that captures fully rendered pages.
Step-by-Step Etsy Scraping Guide
Scraping Etsy presents challenges like dynamic content loading, CAPTCHAs, and bot detection. This guide will walk through how to extract Etsy product listings using Puppeteer to load pages and Cheerio to parse the HTML. The extracted data will then be saved to a CSV file for easy analysis. Each step includes an explanation and code snippet.
Step 1: Install Dependencies
To get started, install the necessary libraries:
- Puppeteer – Automates the browser to load pages and handle JavaScript-rendered content.
- Cheerio – Parses the HTML using jQuery-like selectors.
- csv-writer – Saves extracted data to a CSV file.
Run the following command to install them:
npm install puppeteer cheerio csv-writer
Step 2: Fetch Etsy Search Results with Puppeteer
Etsy loads search results dynamically, meaning a simple HTTP request won’t return all product listings. Puppeteer helps load the page as a real browser to retrieve the fully rendered content.
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
const fs = require("fs");
puppeteer.use(StealthPlugin());
async function fetchHTML(url) {
let browser;
try {
browser = await puppeteer.launch({
executablePath: "/usr/bin/chromium",
headless: true,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setUserAgent(
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
);
await page.goto(url, { waitUntil: "networkidle2", timeout: 60000 });
const html = await page.content();
fs.writeFileSync("debug.html", html);
await browser.close();
return html;
} catch (err) {
if (browser) await browser.close();
process.exit(1);
}
}
const etsySearchUrl = "https://www.etsy.com/search?q=candles";
// Example usage
fetchHTML(etsySearchUrl).then((html) => {
// Next step: parse HTML with Cheerio
});
This function opens a headless browser, sets a user agent to mimic normal browsing, navigates to the Etsy search results page, and extracts the fully rendered HTML. This is necessary because product listings load dynamically using JavaScript.
Step 3: Extract Product Listings with Cheerio
Once the HTML has been retrieved, Cheerio can extract product details like title, price, and product URL.
const cheerio = require("cheerio");
function extractProductListings(html) {
const $ = cheerio.load(html);
const products = [];
$(".v2-listing-card").each((_, element) => {
const title = $(element).find("h3").text().trim();
const price = $(element).find(".currency-value").first().text().trim();
const link = $(element).find("a.listing-link").attr("href");
if (title && price && link) {
products.push({
title,
price,
link,
});
}
});
return products;
}
// Example usage
fetchHTML(etsySearchUrl).then((html) => {
const products = extractProductListings(html);
});
This function loads the HTML into Cheerio and selects product cards using their CSS classes. It extracts the title, price, and product link from each listing and stores them in an array. Only listings that have all three fields are included in the results.
Step 4: Save Extracted Data to a CSV File
The product listings will be saved in a CSV file using CSV-writer to make the extracted data easy to analyze.
const createCsvWriter = require("csv-writer").createObjectCsvWriter;
async function writeToCSV(products) {
const csvWriter = createCsvWriter({
path: "etsy_products.csv",
header: [
{ id: "title", title: "Product Title" },
{ id: "price", title: "Price" },
{ id: "link", title: "Product Link" },
],
});
try {
await csvWriter.writeRecords(products);
} catch (error) {
process.exit(1);
}
}
// Example usage
fetchHTML(etsySearchUrl).then((html) => {
const products = extractProductListings(html);
if (products.length) {
writeToCSV(products);
}
});
The writeToCSV function creates a CSV file named etsy_products.csv and writes the product title, price, and link for each listing. If no listings are found, a message is logged instead of creating an empty file.
Limitations of Scraping Etsy

Bot Protection
Etsy monitors traffic patterns to detect automation and block scraping attempts. If a script sends too many requests too quickly or accesses pages unnaturally, the site may trigger CAPTCHAs or temporarily block access.
Some pages use anti-bot services that analyze browsing behavior to identify automated tools. Slowing down requests, using realistic user agents, and introducing slight delays between actions can help avoid detection.
IP Blocking
Repeated scraping from the same IP address can lead to temporary or permanent bans. Etsy has rate limits to prevent excessive requests in a short period. Access may be restricted when an IP gets flagged, forcing scrapers to wait or switch to a new connection. Using proxies, rotating IPs, and monitoring response headers for early signs of blocking can help maintain uninterrupted access.
Dynamic Content Loading
Many parts of Etsy’s site rely on JavaScript to load product listings, pricing, and other details. A simple HTTP request may not return the full page content since some data loads only after scrolling or interacting with the page.
Scraping methods must account for this using headless browsers or tools that can wait for JavaScript execution. Without this, important details may be missing from the extracted data.
Using BQL to Scrape Etsy
Scraping Etsy isn’t always easy, with CAPTCHAs, bot detection, and pages that load content dynamically, making it tricky to pull the needed data. Browserless Query Language (BQL) helps by providing a structured way to control headless browsers.
It lets you load pages and extract content without dealing with as many roadblocks. In this guide, we’ll go through how to scrape Etsy product listings using BQL, making the process smoother and less likely to get flagged.
Step 1: Install Required Dependencies
To get started, we’ll install a few packages to help us make HTTP requests and save our results. You don’t need to handle HTML parsing here BQL handles the heavy lifting.
npm install node-fetch csv-writer
node-fetchhandles API requests to Browserless.CSV-writerhelps write the results in a CSV file.
These tools simplify your workflow, focusing only on fetching and saving needed data.
Step 2: Write the BQL Query with Mapping
Now let’s define the query that tells Browserless what to do. This query opens the Etsy homepage, searches for "candles", and maps over each product card to extract key info like title, price, and link.
const fetch = (...args) =>
import("node-fetch").then(({ default: fetch }) => fetch(...args));
const fs = require("fs");
const { createObjectCsvWriter } = require("csv-writer");
// === Browserless Config ===
const endpoint = "https://production-sfo.browserless.io/chromium/bql";
const token = "YOUR_BROWSERLESS_API_KEY"; // Replace with your API key
const proxyString = "&proxy=residential&proxySticky=true&proxyCountry=us";
const optionsString = "&humanlike=true";
// === BQL Query ===
const query = `
mutation ScrapeEtsyWithMap {
goto(url: "https://www.etsy.com") {
status
}
fillSearch: type(
selector: "input#global-enhancements-search-query"
text: "candles"
) {
time
}
submitForm: click(selector: "button.wt-input-btn-group__btn") {
time
}
waitForTimeout(time: 2000) {
time
}
listings: mapSelector(selector: ".v2-listing-card") {
title: mapSelector(selector: "h3", wait: true) {
text: innerText
}
price: mapSelector(selector: ".currency-value", wait: true) {
amount: innerText
}
rating: mapSelector(selector: ".wt-text-title-small", wait: false) {
score: innerText
}
reviewCount: mapSelector(selector: "p.wt-text-body-smaller", wait: false) {
total: innerText
}
link: mapSelector(selector: "a.listing-link") {
href: attribute(name: "href") {
value
}
}
}
}
`;
// Fetch function
async function fetchListingsFromBQL() {
const response = await fetch(
`${endpoint}?token=${token}${proxyString}${optionsString}`,
{
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
query,
operationName: "ScrapeEtsyWithMap",
}),
},
);
const result = await response.json();
const listings = result?.data?.listings || [];
const parsedListings = listings.map((item) => {
const getFirst = (arr, key) => (Array.isArray(arr) && arr[0]?.[key]) || "";
const getSecond = (arr, key) => (Array.isArray(arr) && arr[1]?.[key]) || ""; // For rating like "4.9"
return {
title: getFirst(item.title, "text"),
price: getFirst(item.price, "amount"),
rating: getSecond(item.rating, "score"),
review_count: getFirst(item.reviewCount, "total"),
url: getFirst(item.link, "href")?.value || "",
};
});
return parsedListings;
}
This query does everything in one go it loads the page, performs the search, and extracts data with scoped selectors. It's clean and readable and avoids extra steps like parsing or manual DOM traversal.
Step 3: Send the BQL Request and Save Results
Once the query is ready, we send it to the Browserless API and capture the response. Then we save the mapped data to a CSV file.
// Write to CSV
async function writeToCSV(data) {
const csvWriter = createObjectCsvWriter({
path: "etsy_bql_listings.csv",
header: [
{ id: "title", title: "Title" },
{ id: "price", title: "Price" },
{ id: "rating", title: "Rating" },
{ id: "review_count", title: "Review Count" },
{ id: "url", title: "Product URL" },
],
});
await csvWriter.writeRecords(data);
}
// Run it
(async () => {
try {
const listings = await fetchListingsFromBQL();
if (!listings.length) {
console.warn("No listings returned from BQL.");
return;
}
await writeToCSV(listings);
console.log(` Saved ${listings.length} listings to etsy_bql_listings.csv`);
} catch (err) {
console.error("Scraping failed:", err.message || err);
}
})();
This script handles everything from sending the BQL query to saving your results in CSV format. It's reliable, readable, and works without scraping raw HTML.
Conclusion
Scraping Etsy presents unique challenges like CAPTCHAs, bot detection, and JavaScript-heavy pages, but using Browserless with BQL helps you easily navigate those obstacles. Instead of manually wrestling with browser automation, you can load pages, extract content, and handle dynamic elements in one streamlined request. Pairing that with smart practices like IP rotation, proxy usage, and headless browsing ensures your scrapers stay effective and undetected. Try Browserless and start scraping Etsy like a pro today.
FAQ
What data can I scrape from Etsy?
Etsy contains valuable information that can be extracted, including product listings, seller details, customer reviews, pricing, and category data. This data is useful for market research, price tracking, and trend analysis.
How can I avoid getting blocked while scraping?
To reduce the risk of getting blocked, it's important to rotate IPs, use proxies, slow down requests, and mimic human browsing behavior. Small delays between actions and randomizing mouse movements or page interactions can also help prevent detection.
How do I handle dynamically loaded content?
Since Etsy loads many elements using JavaScript, simple HTTP requests won’t always return complete product listings. Puppeteer or Selenium allows you to execute JavaScript, scroll through search results, and load all elements before extracting data.
Can I use proxies to avoid IP bans?
Yes, rotating proxies or using a headless browser with different user agents helps distribute requests across multiple IPs, making it harder for Etsy to detect and block scraping attempts. Proxies also allow access from different locations, which can be useful for region-specific data collection.