Key Takeaways
- Browserless enables real browser automation inside n8n. You can automate tasks that involve JavaScript rendering, logins, redirects, or full-page scraping, all without scripts or servers.
- Session persistence and full-page rendering unlock complex workflows. From scraping gated content to analyzing UX with AI, Browserless handles tasks that go beyond basic HTTP requests.
- Each workflow remains modular and reusable in n8n, allowing data extraction, transformation, AI processing, and PDF generation to be mixed and matched without requiring backend code.
Introduction
Browserless + n8n lets you run browser-based workflows directly inside your automation, no custom scripts or headless setup needed. Whether you're scraping data, handling login-gated pages, or analyzing content at scale, Browserless adds real browser power to your no-code stack. As teams build data flows, content monitors, or lead gen tools, the need for more flexible automation grows, especially for JavaScript-heavy sites, session handling, and redirect workarounds. Standard HTTP nodes often fall short. This article shares four new Browserless + n8n use cases, all based on real user questions from authenticated scraping to AI analysis and automation resilience.
For guidance on how to integrate Browerless into n8n, please look at our previous installment of the n8n use cases.
Use Case 1: Scrape Authenticated Portals + Trigger CRM Actions
Let’s say you’re looking to get data inside a login-protected site, maybe your telecom dashboard or supplier portal.
Doing this manually is error-prone and does not scale well. With Browserless and n8n, you can build a workflow that logs in once, extracts the data you care about, and only triggers downstream logic when something meaningful changes.
Here’s a snapshot of how the workflow looks inside n8n: @@image(filename="n8n-auth-session-flow", alt="Authenticated Session Flow in n8n")
In this example, we used Browserless to log into a gated quote site and extract structured data from a page that’s only visible after authentication.
The data in this case, quotes, is parsed and filtered based on author, and only certain matches (like Albert Einstein) trigger downstream actions. While we’re using quotes for demonstration, this pattern is widely applicable to any structured content behind a login.
Here’s how the workflow runs in n8n:
Trigger:
A Cron node runs the workflow on a schedule, like every hour or day, depending on how often the content updates.
HTTP Request Node (Browserless /graphql):
Browserless performs a login using a BrowserQL mutation. It fills the login form on quotes.toscrape.com, submits the credentials, and navigates to the page containing quote data. Session persistence is managed using userDataDir, so the workflow can reuse a logged-in state without redoing the login every time.
Selector-based Scraping:
The page content is extracted using mapSelector, which structures the output as a list of objects each containing a quote, its author, and associated tags. This structure mimics how you might scrape product entries, user records, or ticket logs from an authenticated web portal.
mutation QuotesLoginScraper {
reject(type: [image, media, font, stylesheet]) {
enabled
time
}
goto(url: "https://quotes.toscrape.com/login") {
status
}
typeUsername: type(selector: "input[name='username']", text: "admin") {
time
}
typePassword: type(selector: "input[name='password']", text: "admin") {
time
}
clickSubmit: click(selector: "input[type='submit']") {
time
}
waitPostLogin: waitForNavigation {
url
}
gotoQuotesPage: goto(url: "https://quotes.toscrape.com/") {
status
}
quotes: mapSelector(selector: ".quote") {
text: mapSelector(selector: ".text") {
value: innerText
}
author: mapSelector(selector: ".author") {
name: innerText
}
tags: mapSelector(selector: ".tags .tag") {
tag: innerText
}
}
html(clean: { removeAttributes: true, removeNonTextNodes: true }) {
html
}
}
Code Node
We use a Code node to filter the output format the data for the filer node:
const rawQuotes = $input.first().json.data.quotes || [];
const formattedQuotes = Array.isArray(rawQuotes)
? rawQuotes.map((q) => ({
text: q.text?.[0]?.value || "",
author: q.author?.[0]?.name || "",
tags: Array.isArray(q.tags) ? q.tags.map((t) => t.tag).filter(Boolean) : [],
}))
: [];
return [
{
json: {
quotes: formattedQuotes,
},
},
];
Filter Node:
If the filtered data is not empty, the workflow continues. This logic ensures that downstream systems only react when something meaningful is found.
Action Node:
Matching records are pushed to Slack, a CRM, or any other system using webhook, email, or integration nodes in n8n.
Why This Is Useful
This is a practical way to automate “eyes-on” work especially for content or systems that live behind logins and don’t expose public APIs. Teams often need to monitor data that’s only available in browser-rendered views, like:
- Portals with no exports or feeds
- Internal dashboards with session-only access
- Dynamic reports or product lists that require JavaScript to render
Browserless enables interaction with those pages as a real user would. Combined with n8n, you get a repeatable way to extract, filter, and respond to browser-visible changes no scraping scripts or backend logic required.
How This Can Be Extended
We used quotes here for clarity, but the same approach works with any structured content: SKUs, invoices, tickets, logs, usage data, or summaries. You can adapt this flow to:
- Track changes in customer portals or billing dashboards
- Monitor partner sites for product updates or new documents
- Watch authenticated ticketing or reporting systems for critical events
If you can see it in the browser after login, Browserless can extract it, and n8n can decide what to do with it. You can even store historical snapshots, compare new data to old, or generate documents or alerts based on the changes. It’s a flexible pattern for scaling browser-based work into automation.
Use Case 2: Smart PDF Generation from Scraped Data
Automating client reports, invoices, or competitive summaries typically involves combining scripts, templates, and PDF tools or simply doing it manually. With Browserless and n8n, you can skip the backend hassle and go straight from structured HTML to polished, downloadable PDFs.
Here’s the actual setup inside n8n:
@@image(filename="use-case-2", alt="Use Case 2")
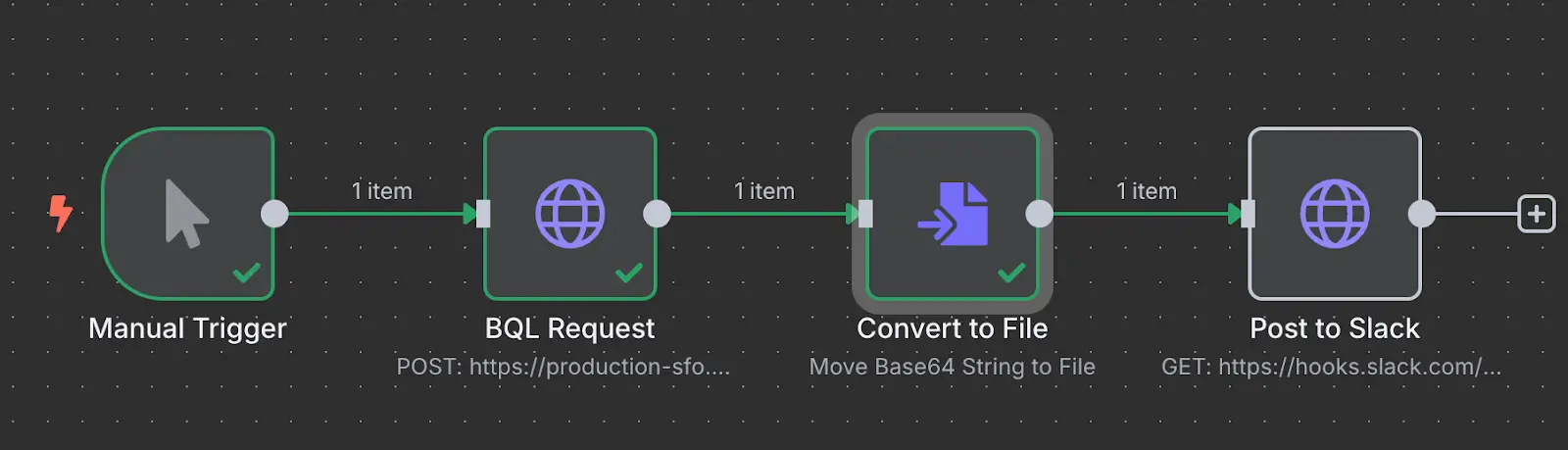
In many internal systems, dashboards are rendered entirely client-side using JavaScript frameworks like Highcharts, Chart.js, or D3. While these UIs are visually useful, they often lack a formal API or export mechanism, leaving developers with no structured way to capture and reuse the information programmatically.
Screenshots don’t scale. Manual PDF exports are error-prone. And reimplementing the frontend logic to generate reports on the backend isn't always practical.
That’s where Browserless can help with BQL and n8n, we created a workflow that renders live, JavaScript-driven content as a PDF ideal for automating internal reporting flows or long-term archiving. In this example, we hit a public banking site that visualizes interest rate trends.
These charts are entirely frontend-generated, with no backend endpoint for the raw data. Rather than reverse-engineer the charting logic or scrape unstable HTML, we let the site render as-is inside a headless browser and capture the DOM visually.
Node Workflow Breakdown
Trigger:
A Manual Trigger kicks off the test flow. In production, you could use a Cron node to run this hourly, daily, or in sync with an upstream data update.
HTTP Request Node (Browserless /function):
This node sends a small HTML wrapper to Browserless, which injects or mirrors the rendered data we care about either scraped, composed in n8n, or built inline with dynamic variables. Browserless runs it in a real browser context, which means all JavaScript executes exactly as it would in Chrome. The output is rendered into a PDF using pdfOptions (format, background rendering, etc.).
# Send a POST request to the Browserless /bql endpoint with your API token
curl --request POST \
--url 'https://production-sfo.browserless.io/chrome/bql?token=YOUR_API_TOKEN&proxy=residential&blockConsentModals=true' \
--header 'Content-Type: application/json' \
--data '{
# GraphQL mutation that visits the Bank of Canada interest rates page
"query": "mutation PDFReport {
goto(url: \"https://www.bankofcanada.ca/rates/interest-rates/\", waitUntil: networkIdle) {
status
}
# Generate a simple PDF (defaults)
simple: pdf {
base64
}
# Generate a customized A4 PDF with headers and footers
customPDF: pdf(
format: a4
printBackground: true
displayHeaderFooter: true
headerTemplate: \"Interest Rates\"
footerTemplate: \"Page of \"
) {
base64
}
}",
"variables": {},
"operationName": "PDFReport"
}'
Convert to File:
Browserless returns the PDF as a base64-encoded string. This node converts it into a binary file inside n8n so it can be passed to external systems. In this example, we are taking snapshots of the Bank of Candas' interest rate:
Slack (or Output Node):
The final PDF is delivered to a Slack channel for the finance team. You could POST it to a storage service, attach it to an email, or archive it with metadata in a database.
Why This Is Useful
This solves a common internal pain point: how do you extract usable, repeatable output from frontends that don’t expose data?
Instead of building out fragile scrapers or chasing half-baked APIs, you treat the page like a user would render it, snapshot it, and convert it. Browserless ensures that JS-powered content, animations, and even lazy-loaded graphs are fully executed before the capture happens.
As a developer, this gives you a clean pipeline from arbitrary frontend content → real-world output (PDF, image, JSON, etc.) without writing Puppeteer scripts, setting up Chrome, or building custom report logic from scratch.
How This Can Be Extended
- Build scheduled reports from frontend dashboards (analytics, sales, finance)
- Automatically capture snapshots of compliance reports or metric summaries
- Route PDF captures into ticketing, documentation, or audit systems
- Apply versioning (e.g. date-stamped filenames) and upload to versioned storage
- Use the same approach for form-generated HTML or React-rendered summaries
Browserless handles rendering. n8n orchestrates logic. You control the output, timing, and delivery. This lets you build powerful, developer-friendly automations around frontend-only content that would otherwise be a manual or brittle part of your workflow.
Use Case 3: LLM-Powered Website SEO Analysis
If you're a marketer or dev and you're improving your on-page SEO, reviewing individual article pages for things like meta tags, heading structure, link quality, or keyword density can quickly become unscalable. This kind of manual QA work is challenging to track, standardize, and ensure, especially when new content is published weekly.
Let’s walk through a real example using this article from TechCrunch:
AI may already be shrinking entry-level jobs in tech
We used Browserless and n8n to automate a comprehensive SEO audit for this page. Browserless loads the site in a real browser session, rendering all dynamic content and JavaScript-driven markup.
From there, we capture the complete HTML output and pass it into Claude for analysis, eliminating the need for dev tools, scraping libraries, and manual inspection.
Here’s what the workflow looks like in n8n:
Browserless handles the rendering, ensuring the AI sees exactly what a search engine or user would experience. We send the full HTML to an AI Agent node, where Claude reviews it for SEO quality.
That includes structural checks (headings and metadata), content analysis (tone and clarity), accessibility (alt tags), and link assessment (internal/external balance and descriptiveness).
Node Workflow Breakdown:
Trigger: A manual trigger is used here for simplicity, but this could easily be run on a schedule or triggered by a new content deployment.
HTTP Request Node (Browserless /bql): This loads the article in a full browser context. JavaScript is executed, and the final scraped HTML is returned once the page is fully loaded.
AI Agent Node (Claude/OpenAI): The raw HTML is passed to Claude with a structured SEO prompt. The LLM reviews title usage, heading hierarchy, alt attributes, link quality, and keyword coverage.
With the following prompt:
You are an SEO strategist reviewing a SEO article.
Based on the following HTML of the page content, assess:
Whether the title and headings include relevant keywords for SEO
If images are appropriately labeled with alt text
Whether the internal/external links are descriptive and appropriate
If the heading hierarchy (h1, h2, h3) is logical and consistent
Provide suggestions to improve SEO, structure, and accessibility
OUTPUT: Provide a bullet‑pointed summary with specific page improvement recommendations.
Here is the Html {{ $json.data.html.html }}
Output Node: Claude’s feedback is posted to Slack or saved for content teams to review and apply.
Why This Is Useful
This allows you to automate page-level SEO reviews for any article or landing page. You receive consistent, structured feedback from a model trained to identify gaps in structure, optimization, or clarity, eliminating the need to open a browser or run an audit tool manually. It scales well across content teams and publishing schedules, and it’s easy to adjust for different review goals.
How This Can Be Extended
You can use the same pattern for large-scale blog archives, regularly crawl and evaluate product pages, or even run automated post-publish SEO checks as part of your content workflow.
Claude can be prompted differently for different types of content, and the rendered HTML gives you a reliable snapshot of the live page, not just what’s stored in your CMS. Whether you're working on a five-page site or a 5,000-page content hub, this setup gives you a repeatable way to enforce SEO consistency and catch problems early.
Conclusion
These use cases demonstrate how low-code workflows can now handle automation tasks that previously required engineering time or brittle scripts. With Browserless handling browser interactions and n8n managing flow logic, users get a powerful combo that’s both flexible and scalable. If you're ready to go deeper, start by exploring the Browserless API docs or trying one of our n8n-ready templates. You can build on top of these examples or remix them for your workflows. To get started, sign up for a free Browserless account and grab your API token.
FAQs
1. What is Browserless used for in automation workflows?
Browserless lets you run headless browsers via API, making it easy to scrape dynamic sites, navigate login flows, or generate screenshots and PDFs, all integrated into tools like n8n.
2. How does Browserless improve n8n workflows?
Browserless adds browser-level automation to n8n, enabling flows that need JavaScript rendering, session reuse, CAPTCHA handling, and more features that regular HTTP nodes can’t handle.
3. Can I scrape login-protected pages using Browserless in n8n?
Yes. With Browserless session caching or user-data-dir, you can log in once and reuse the session across multiple n8n executions without reauthenticating.
4. What are real-world Browserless use cases with n8n?
Use cases include scraping eCommerce portals, generating PDF reports from scraped data, performing AI-powered audits on websites, and validating redirect-heavy URLs for SEO or cold email tools.
5. Do I need to code to use Browserless with n8n?
No full coding is required. Most workflows use HTTP nodes and JSON handling. JavaScript can be used in Code nodes for custom data shaping, but many flows work with copy-paste templates.