Web Scraping vs Data Mining: Understanding the Differences, Use Cases & Best Practices
Key Takeaways
- Web scraping and data mining serve different roles but work better together: Scraping collects structured data from the web, while data mining analyzes that data for patterns, predictions, or insights. When integrated, they enable more effective and real-time decision-making.
- BQL makes browser-based scraping easier and more scalable: With BrowserQL, developers can extract data from dynamic web pages using browser automation, without writing and maintaining fragile Python scraping scripts.
- Combining scraping with machine learning unlocks smarter workflows: From sentiment analysis of reviews to tracking pricing trends, using scraped data as a foundation for modeling and forecasting gives businesses a stronger competitive edge.
Introduction
Web scraping and data mining are often used interchangeably; however, they serve distinct purposes within the data lifecycle. Scraping focuses on collecting structured or semi-structured information from web sources, while data mining analyzes existing datasets to uncover trends, relationships, or predictions. Knowing the difference helps you choose the right approach depending on whether you need data access or deeper insight. This article walks through how each works, where they overlap, and when to use them separately or together for maximum value.
What Is Web Scraping?

Web scraping refers to the automated extraction of information from websites. Rather than manually copying and pasting content, a script or tool fetches the page’s HTML and extracts specific data based on predefined rules.
Scrapers operate much like browsers but are programmed to focus only on the data you care about, titles, prices, tags, dates, links, and other structured elements in the page source.
Scripts can interact with public pages, parse HTML, and extract content using tags, class names, or XPath selectors. Depending on the setup, scrapers might use raw HTTP requests for static content or full browser automation to handle dynamic content rendered by JavaScript.
Common Use Cases for Web Scraping
Web scraping supports a wide range of tasks that require publicly accessible data in a structured format. Some practical examples include:
- Price monitoring: Retailers and analysts track competitor pricing in real time.
- SEO tracking: Marketers extract search result rankings or keyword frequencies.
- Content aggregation: News platforms, blogs, or review sites pull data from multiple sources to centralize coverage.
- Job listing tracking: Recruiters and tools collect openings across multiple job boards.
- Academic research: Analysts collect articles, citations, or metadata for studies.
These use cases often rely on frequent updates and are driven by automation that scales across many pages or categories.
Tools, Technologies, and a Code Example
Several tools exist to make scraping reliable and repeatable. Some focus on handling HTML directly, while others support full browser rendering:
- Python + BeautifulSoup or lxml for static pages
- Selenium or Playwright for automated browser control
- Puppeteer (Node.js) for headless Chrome control
- Scrapy for scalable crawling pipelines
- APIs (when available) to pull data without scraping
Here’s a simple Python example using requests and BeautifulSoup to extract titles from a basic HTML page:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [a['title'] for a in soup.select('h3 a')]
for title in titles:
print(title)
What this code snippet does:
This script fetches the homepage from “Books to Scrape,” selects all the book titles using CSS selectors, and prints them one by one. It’s enough to show how a few lines of Python can extract structured data from a live website. More advanced workflows would introduce pagination, error handling, and data storage, but this is a functional starting point.
What Is Data Mining?
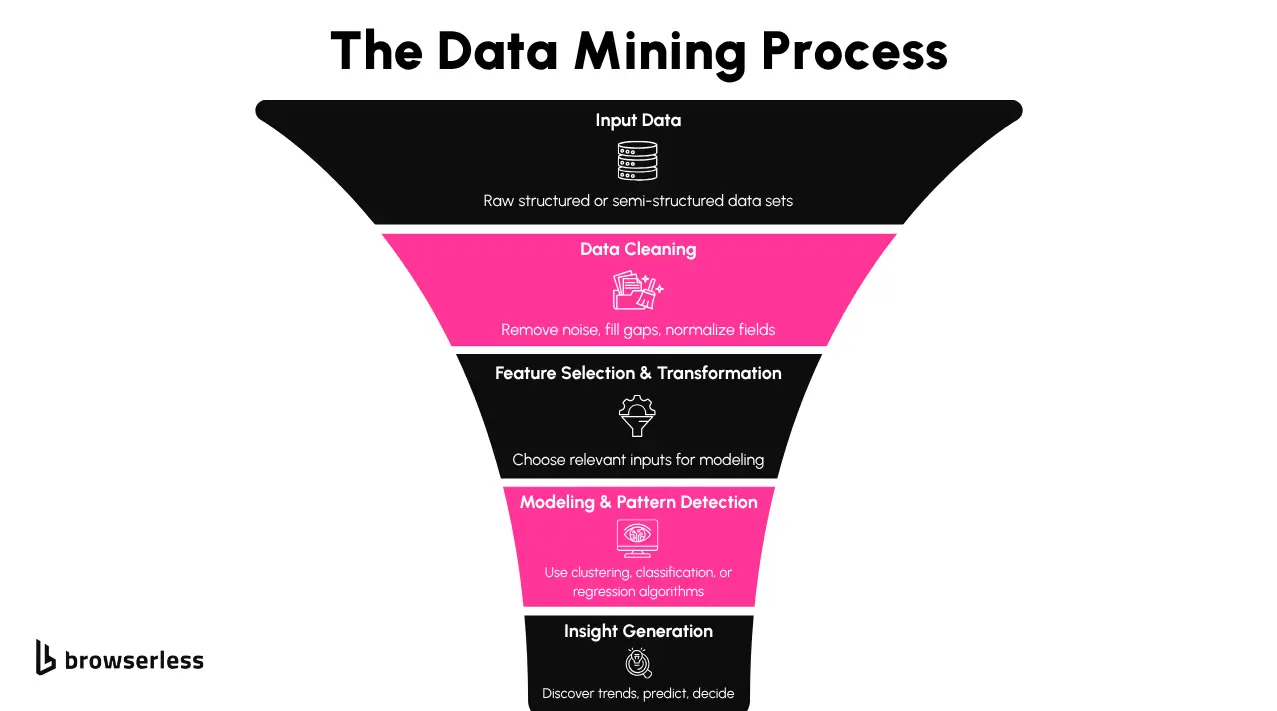
Defining Data Mining in Practice
Data mining is the process of analyzing large datasets to discover patterns, relationships, or trends that aren't immediately obvious. It sits in the middle of the data analysis pipeline—after data has been collected, but before insights can be acted on. Unlike web scraping, which is focused on gathering data, data mining is about making sense of that data once it’s in your hands.
This typically occurs within structured datasets, such as databases, CSV files, or large-scale data warehouses. Analysts or machine learning models comb through that data to uncover actionable insights, like common behaviors, predictive trends, or meaningful clusters of information.
Where Data Mining Is Applied
The techniques used in data mining are applicable across various industries. These are a few areas where it’s regularly put to use:
- Marketing: Segmenting audiences, predicting churn, or identifying customer lifetime value
- Finance: Detecting fraud, modeling credit risk, or forecasting investment outcomes
- Healthcare: Predicting patient outcomes, analyzing treatment efficacy, or flagging anomalies in diagnostic data
- Retail: Recommending products based on past behavior, managing inventory, or modeling demand
These applications depend on structured, reliable datasets—often pulled from internal systems, but increasingly also from scraped public data or third-party APIs.
Process and Tools for Data Mining
The workflow for data mining usually follows a few recurring stages:
- Data Cleaning: Fixing inconsistencies, filling gaps, and converting formats
- Exploratory Analysis: Looking for signals in the noise through visualization or summary stats
- Modeling: Applying algorithms like clustering, regression, or classification
- Evaluation: Validating that findings are statistically sound and practically useful
Several tools support these steps:
- Python libraries: pandas, scikit-learn, XGBoost
- R: For statistical modeling and academic workflows
- SQL: For querying structured data in relational databases
- Jupyter or Google Colab: To combine code, results, and documentation in one place
To illustrate how data mining reveals structure in datasets, let’s look at a simple clustering example using KMeans and synthetic data. Below is a simple example using scikit-learn to identify clusters in a dataset using KMeans:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Create a sample dataset
X, _ = make_blobs(n_samples=300, centers=4, random_state=42)
# Apply KMeans clustering
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
labels = kmeans.labels_
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title("KMeans Clustering")
plt.show()
What this code snippet does:
This generates a synthetic dataset with clear groupings, applies a clustering algorithm, and visualizes the output. While this is a controlled example, the technique scales to real-world datasets where the structure isn’t always so obvious.
How Web Scraping and Data Mining Complement Each Other
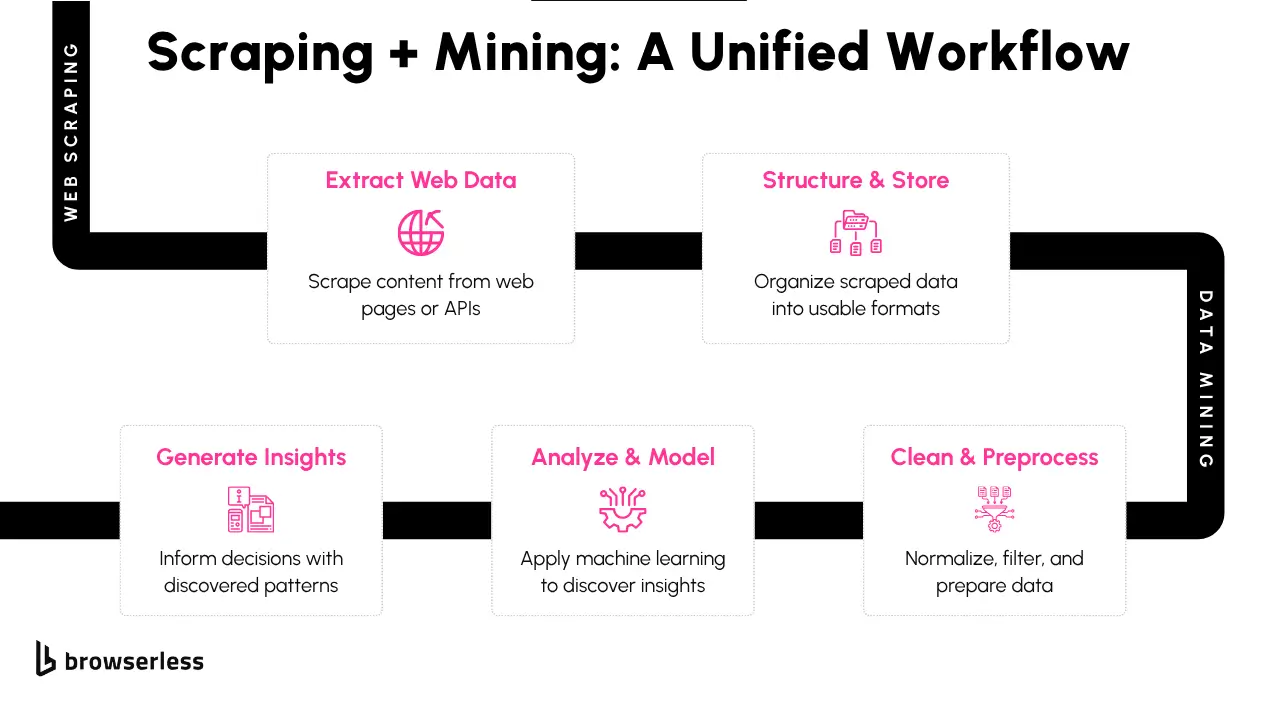
Scraped Data as a Foundation for Deeper Analysis
Data mining doesn’t happen in a vacuum—it requires raw data from somewhere. Web scraping often serves as the first step in that chain, especially when working with publicly available or real-time information that isn’t offered via an API. Once scraped, that data can be structured, stored, and fed into analysis pipelines.
Whether you're collecting product listings, social media comments, news articles, or job postings, scraping gives you a direct feed of current, usable information. That raw data becomes far more valuable once it's mined for trends, clusters, or predictions.
Real-World Example: Product Reviews → Sentiment Analysis
Let’s say you’ve scraped thousands of customer reviews from an e-commerce site. Those reviews contain a mix of ratings, natural language feedback, and metadata like product names or timestamps. While the raw text itself is informative, applying data mining techniques makes it actionable.
For example:
- Sentiment classification: Group reviews as positive, negative, or neutral using NLP models
- Trend detection: Surface recurring complaints or features customers praise
- Clustering: Group similar reviews or products to identify shared user patterns
This type of analysis enables businesses to prioritize improvements, refine their messaging, or inform future product decisions.
Practical Challenges When Combining Both
Integrating web scraping with data mining isn’t always smooth. A few common issues come up repeatedly:
- Data quality: Scraped HTML often contains noise—ads, irrelevant tags, formatting quirks—which need to be cleaned out
- Format compatibility: Scraped content may need to be transformed (e.g., from HTML to structured rows) before it’s ready for analysis
- Scale and performance: Large-scale scraping jobs require storage management, rate limiting, and error handling before the data is stable enough for modeling
Each of these issues adds friction to the pipeline and often requires preprocessing steps that aren't needed with well-prepared internal data.
Best Practices for Building a Scrape-to-Mine Workflow
Combining scraping with data mining benefits from a modular, clear workflow. These practices can help maintain structure and repeatability:
- Separate scraping and processing logic: Treat them as distinct steps so errors are easier to trace
- Store intermediate results in reusable formats like CSV, Parquet, or JSONL
- Normalize text fields (e.g., lowercase, remove special characters) before modeling
- Use pipelines or notebooks to document the full path from data ingestion to output
- Monitor source changes: Since scraped sites change, pipelines may break silently without alerts
End-to-End Example: Scrape, Store, Analyze
Let’s walk through a simplified example that ties everything together, scraping data, storing it, and running basic analysis all in one Python script. Here’s a simplified Python example showing how you might scrape data, save it, and run basic analysis—all in one script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from textblob import TextBlob
# Step 1: Scrape sample reviews
url = "https://example.com/reviews"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
reviews = [p.text for p in soup.select('.review-text')]
# Step 2: Save to file
df = pd.DataFrame(reviews, columns=["review"])
df.to_csv("reviews.csv", index=False)
# Step 3: Run sentiment analysis
df["polarity"] = df["review"].apply(lambda x: TextBlob(x).sentiment.polarity)
print(df.head())
What this code snippet does:
This pipeline scrapes reviews, saves them to a CSV, and applies a simple polarity score using TextBlob. In a production setup, you’d likely expand this with error handling, more advanced models, and long-term storage.
When to Use Web Scraping, Data Mining, or Both
Matching the Approach to the Problem
Choosing between web scraping, data mining, or combining both depends on the type of insight you’re aiming for. Web scraping focuses on collecting up-to-date information from public or semi-public sources. It’s ideal when APIs are unavailable or when you need to extract structured content from dynamic websites.
Data mining, on the other hand, comes into play once you’ve gathered a substantial dataset. It’s used to uncover patterns, segment users, detect trends, or make predictions. When the goal is insight—not just access—data mining builds on whatever information you already have.
Building Repeatable Pipelines with BQL
Combining the two makes sense when you need continuous access to web data that drives strategic analysis and decision-making. BrowserQL (BQL) is purpose-built for this, allowing you to automate scraping tasks in a way that integrates seamlessly with modern workflows.
With BQL, you can skip manual scripting and extract structured data from dynamic sites using concise, browser-native queries. Here's an example pulling product titles from a webpage:
query {
browser {
goto(url: "https://books.toscrape.com") {
evaluate(
expression: """
Array.from(document.querySelectorAll('h3 a')).map(el => el.getAttribute('title'))
"""
)
}
}
}
What this code snippet does:
That output can be saved, tracked over time, or processed by downstream tools immediately. If you’re working with reviews or unstructured feedback, BQL can also power sentiment workflows. Here’s a query to grab user comments:
query {
browser {
goto(url: "https://example.com/reviews") {
evaluate(
expression: """
Array.from(document.querySelectorAll('.review-text')).map(el => el.textContent.trim())
"""
)
}
}
}
Once collected, the results can be passed into a simple sentiment analysis script like this:
import pandas as pd
from textblob import TextBlob
df = pd.DataFrame(reviews, columns=["review"])
df["sentiment"] = df["review"].apply(lambda x: TextBlob(x).sentiment.polarity)
What this code snippet does:
This pairing of BQL to pull fresh web data and a lightweight model to process it lets you uncover real-time trends from real-world sources without maintaining your browser infrastructure.
Strategic Applications
Scraping works best when information isn’t delivered in a ready-to-use format. Data mining is most effective when you’re ready to delve deeper into pattern discovery, clustering, or modeling. The combination offers more than either alone: it gives you a live, adaptive pipeline for tracking signals as they emerge.
Instead of treating scraping and mining as separate tasks, they can be combined into a single system: Browserless and BQL handle data gathering. In contrast, your analysis tools handle everything that follows.
Conclusion
Web scraping and data mining work best when treated as complementary, not competitive, tools. Scraping brings in fresh, relevant data; mining turns that data into actionable knowledge. Used together, they create feedback loops that adapt to changing markets, customer behavior, or competitive signals. The most effective strategies don’t just collect information; they structure, analyze, and align it with specific business goals. If you’re exploring ways to combine scraping and analysis at scale, book a demo to see how Browserless can support your workflow.
FAQs
What is the difference between web scraping and data mining?
Web scraping is the automated process of collecting data from websites, while data mining involves analyzing datasets to discover patterns or insights. Scraping gathers the data; mining interprets it.
Can you use web scraping and data mining together?
Yes, many workflows benefit from combining both. For example, you can scrape product reviews and use data mining to analyze sentiment trends or classify feedback by topic.
What is BQL in web scraping?
BQL (BrowserQL) is a query language built for headless browser automation via Browserless. It allows developers to extract structured data from JavaScript-heavy sites without managing their browser infrastructure.
Which Python libraries are used for data mining?
Common Python libraries include pandas for data manipulation, scikit-learn for machine learning, and XGBoost for gradient boosting models. These tools help transform raw data into actionable insight.
Why are legacy Python scrapers struggling today?
Legacy scrapers often break on JavaScript-rich websites or require frequent maintenance. Modern tools like BQL offer a more stable, cloud-native approach to extracting content from dynamic pages.