Google Maps is a vast source of data including locations, phone numbers, reviews, ratings, etc., of businesses worldwide. Although Google Maps has the places API, it just touches the surface of what Google Maps shows in the UI. Browserless (browserless.io) can help automate scraping the UI via various approaches and can take care of the overhead of maintaining the infrastructure to run an automated scraping setup. Let’s see how we can use puppeteer along with browserless.io to automate scraping data off of Google Maps.
We've already shared guides on how to scrape Google Shopping, Youtube, Twitter, Glassdoor, Amazon and other useful web automation tutorials. But today, let's dive deeper into web scraping Google Maps.
What’s the plan?
In this article, we will explore how you can curate a database of hotels and various parameters about each hotel listing. We will gather information like phone numbers, public reviews, ratings, addresses, business hours, photos, etc. We will also deal with lazy-loaded content and scrape paginated content.
Google Maps scraper step #1 - Browserless
- Create an account on browserless.io (You can try it for free).
- In this article, we will be using Puppeteer. Please follow step 1 of this guide to set up Puppeteer.
- Login to your browserless.io account, go to the Account page on the left sidebar, and now keep the API key handy. We will be using that soon
Google Maps scraper step #2 - Puppeteer
Now that we have our account set up on browserless.io we will need to set up Puppeteer to interact with it and implement Google Maps data scraping.
Since we don’t want to spend money on local testing, we will set up puppeteer for local development testing and connect to browserless.io URL in production mode. We don’t want to handle the hassle of setting up and managing puppeteer in the production, so browserless.io can do that for us.
Check out the comments to know more about how we make use of local puppeteer setup in the development environment and rely on browserless.io in production.
Instead of installing the whole puppeteer package and a browser with it, you can also install puppeteer-core. The puppeteer-core is intended to be a lightweight version of Puppeteer for launching an existing browser installation or for connecting to a remote one (in our case browserless.io). If you want to know more about how to use puppeteer-core with browserless, check out this guide. Also, you can try out the docker version of browserless.io to test things locally (read more about this at the end of this article).
Let’s start by creating a simple yarn project and installing a few dependencies.
In your project folder run
yarn init
Install puppeteer
yarn add puppeteer
Let’s begin with automating the flow of visiting maps.google.com and searching for queries. Check out the comments in the code for specific details/descriptions.
// script.js
// You can also use puppeteer core, know more about it here https://developers.google.com/web/tools/puppeteer/get-started#puppeteer-core
const puppeteer = require("puppeteer");
const API_TOKEN = process.env.API_TOKEN;
const IS_PRODUCTION = process.env.NODE_ENV === "production";
// In prod: Connect to browserless so we don't run Chrome on the same hardware
// In dev: Run the browser locally
const getBrowser = () =>
IS_PRODUCTION
? puppeteer.connect({
browserWSEndpoint: "wss://chrome.browserless.io?token=" + API_TOKEN,
})
: puppeteer.launch({ headless: false });
(async () => {
let browser = null;
try {
browser = await getBrowser();
const page = await browser.newPage();
// Connect to remote endpoint
// Reset the viewport for more results in single page of google maps.
await page.setViewport({ width: 1440, height: 789 });
// Visit maps.google.com
await page.goto("https://maps.google.com");
// Wait till the page loads and an input field
// with id searchboxinput is also present
await page.waitForSelector("#searchboxinput");
// Simulate user click
await page.click("#searchboxinput");
// Type our search query
await page.type("#searchboxinput", "Hotels in dublin, Ireland");
// Simulate pressing Enter key
await page.keyboard.press("Enter");
console.log("Completed");
browser.close();
} catch (error) {
console.log(error);
}
})();
The above code initializes Puppeteer to either connect remotely to the browserless.io URL or launch a locally installed browser in headless mode, and the first step of searching our query. Then we can through the results and start collecting the data.
This is what the page will look like after running the above script in non-headless mode.
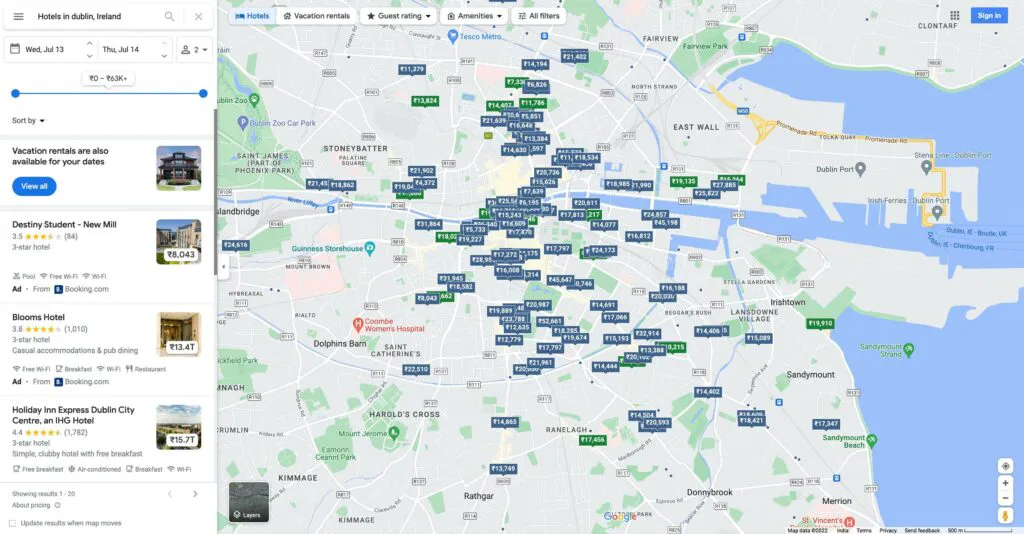
This part is a little tedious, depending on the data you are trying to collect. One catch with Google maps is that the whole map is drawn on an HTML canvas, and a few text elements/details that you see on top of the maps are also canvas elements. So, you cannot find the data that is on the maps by our usual DOM query methods.
One thing you can observe as soon as you type your query and hit enter is that all the results are shown on the left sidebar as well. These results are in sync with the actual map on the right side. By default, those results on the left sidebar already have some vital information.
Example of such a card
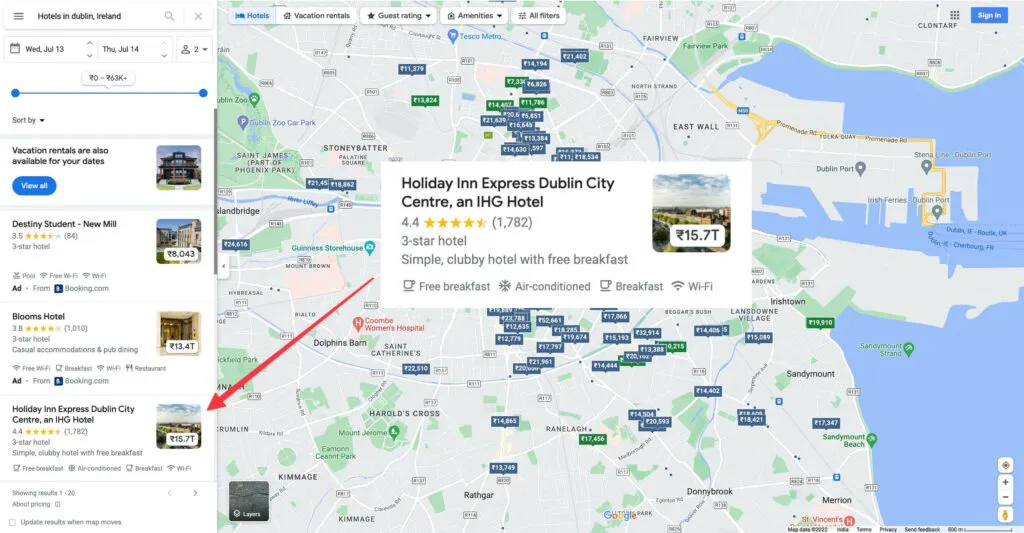
You can click on these cards if you need more information about these listings.
Screenshot of a detailed card below
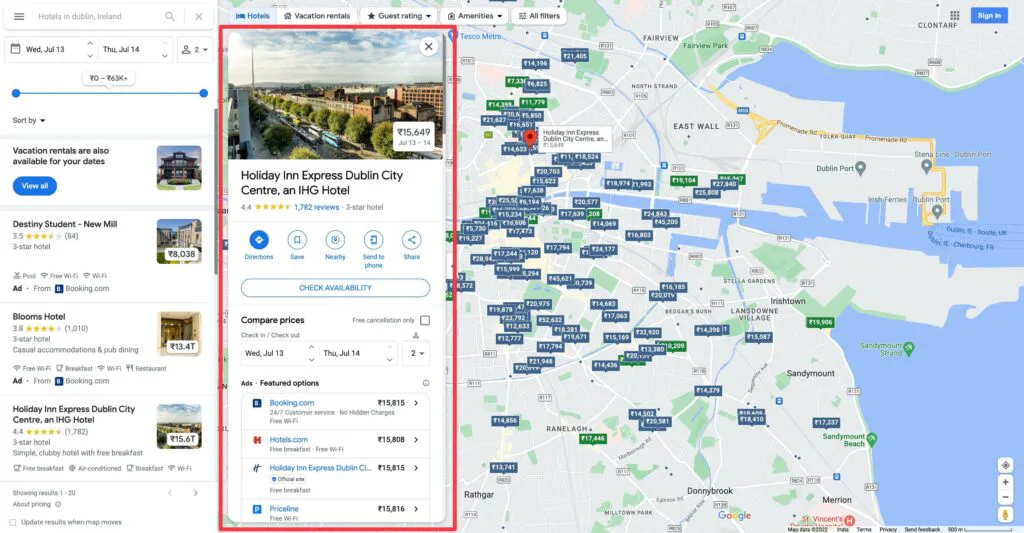
For the scope of this article, we will proceed with scraping data off of these cards on the left sidebar only.
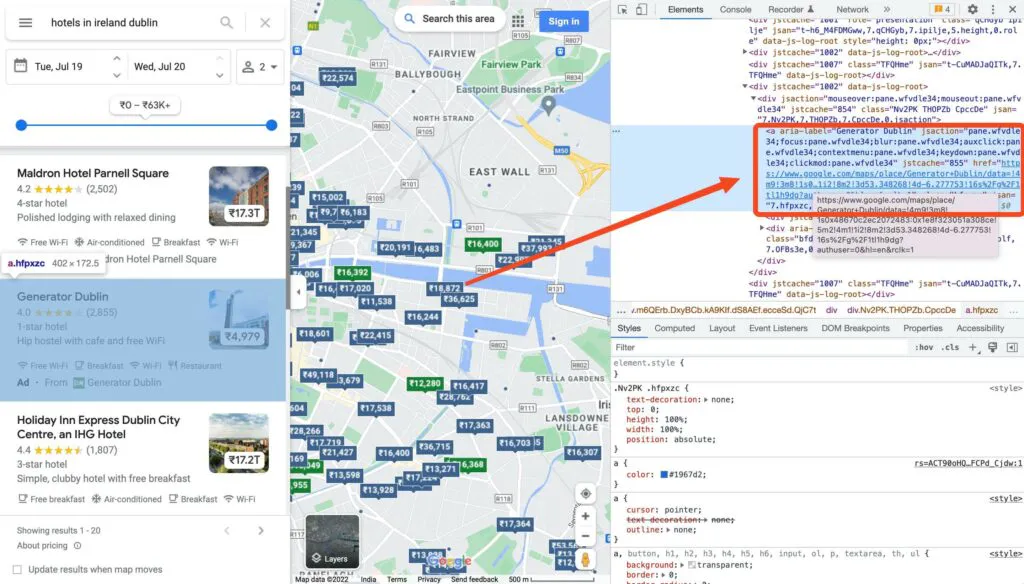
You can find all the selectors that we will be using in the* SELECTORS* object in the below code.
// You can also use puppeteer core, know more about it here https://developers.google.com/web/tools/puppeteer/get-started#puppeteer-core
const puppeteer = require("puppeteer");
const API_TOKEN = process.env.API_TOKEN;
const IS_PRODUCTION = process.env.NODE_ENV === "production";
// In prod: Connect to browserless so we don't run Chrome on the same hardware
// In dev: Run the browser locally while in development
const getBrowser = () =>
IS_PRODUCTION
? puppeteer.connect({
browserWSEndpoint: "wss://chrome.browserless.io?token=" + API_TOKEN,
})
: puppeteer.launch({ headless: false }); // { headless: false } helps visualize and debug the process easily.
// These are class names of some of the specific elements in these cards
const SELECTORS = {
NAME: ".qBF1Pd.fontHeadlineSmall",
LISTING: 'a[href^="https://www.google.com/maps/place/',
RATINGS: ".ZkP5Je",
PRICE: ".wcldff.fontHeadlineSmall.Cbys4b",
LINK: ".hfpxzc",
IMAGE: ".FQ2IWe.p0Hhde",
NAV_BUTTONS: ".TQbB2b",
};
// Scrapes the data from the page
const getData = async (page, currentPageNum) => {
return await page.evaluate(
(opts) => {
const { selectors: SELECTORS } = opts;
const elements = document.querySelectorAll(SELECTORS.LISTING);
const placesElements = Array.from(elements).map(
(element) => element.parentElement,
);
const places = placesElements.map((place, index) => {
// Getting the names
const name = (place.querySelector(SELECTORS.NAME)?.textContent || "").trim();
const rating = (
place.querySelector(SELECTORS.RATINGS)?.textContent || ""
).trim();
const price = (
place.querySelector(SELECTORS.PRICE)?.textContent || ""
).trim();
const link = place.querySelector(SELECTORS.LINK)?.href || "";
const image = place.querySelector(SELECTORS.IMAGE)?.children[0].src || "";
return { name, rating, price, link, image };
});
return places;
},
{ selectors: SELECTORS, currentPageNum },
);
};
(async () => {
let browser = null;
try {
browser = await getBrowser();
const page = await browser.newPage();
// Connect to remote endpoint
// Reset the viewport for more results in single page of google maps.
await page.setViewport({ width: 1440, height: 789 });
// Visit maps.google.com
await page.goto("https://maps.google.com");
// Wait till the page loads and an input field with id searchboxinput is present
await page.waitForSelector("#searchboxinput");
// Simulate user click
await page.click("#searchboxinput");
// Type our search query
await page.type("#searchboxinput", "Hotels in dublin, Ireland");
// Simulate pressing Enter key
await page.keyboard.press("Enter");
// Wait for the page to load results.
await page.waitForSelector(SELECTORS.LISTING);
// Get our final structured data
const finalData = await getData(page);
console.log("Final data", finalData);
browser.close();
return finalData;
} catch (error) {
console.log(error);
}
})();
After running the above script, if everything went fine, you should see output on your terminal like this:
[
{
"name": "Generator Dublin",
"rating": "4.0(2,855)",
"price": "₹4,979",
"link": "https://www.google.com/maps/place/Generator+Dublin/data=!4m9!3m8!1s0x48670c2ec2072483:0x1e8f323051a308ce!5m2!4m1!1i2!8m2!3d53.348268!4d-6.277753!16s%2Fg%2F1tl1h9dg?authuser=0&hl=en&rclk=1",
"image": "https://lh3.googleusercontent.com/proxy/XjZcOx8KA21ywYd9z5Vk9TJQ8eiA27xKEATRHNIbebTu-bhUzWbbKKpjD-rxdCodKfBGaOXWhnSeZxjUq1ZXFxxLNrBJEoLchk5wBbLLGtVWvXjMY1XoOA4E6c8sDqWee0BLblJS5bIv5RNzg_kZWBvFv4VnLg=w137-h92-k-no"
},
{
"name": "The Gibson Hotel",
"rating": "4.3(2,847)",
"price": "₹16.2T",
"link": "https://www.google.com/maps/place/The+Gibson+Hotel/data=!4m9!3m8!1s0x48670ef06ac7842f:0x7cf24046d5cd1116!5m2!4m1!1i2!8m2!3d53.348558!4d-6.228517!16s%2Fg%2F1tp0d2dx?authuser=0&hl=en&rclk=1",
"image": "https://lh5.googleusercontent.com/proxy/YOoODV1ny0ZYW8Aw7uzb8dRgBe6vJOVodeLoafgoHEhztz7FKvXB2HEGbH56BKYL1TZxiDYKwVSZ80WEFEnOr1MGa20YAx4UbMcaXgBWS2cKR_DYQe_WdXSFesLphvztQcttVoxfS0Ap8Ynl3LSvB7G4Iqgq6g=w119-h92-k-no"
},
{
"name": "Holiday Inn Express Dublin City Centre, an IHG Hotel",
"rating": "4.4(1,807)",
"price": "₹17.2T",
"link": "https://www.google.com/maps/place/Holiday+Inn+Express+Dublin+City+Centre,+an+IHG+Hotel/data=!4m9!3m8!1s0x48670e845a54ba5f:0xff504d4459e8c9ca!5m2!4m1!1i2!8m2!3d53.3523056!4d-6.2609549!16s%2Fg%2F11cn6k9vk6?authuser=0&hl=en&rclk=1",
"image": "https://lh5.googleusercontent.com/p/AF1QipPXAofOv7lBMZQ2MOiCu-lw7qGulFFpA2SSfaAh=w138-h92-k-no"
},
{
"name": "Maldron Hotel Parnell Square",
"rating": "4.2(2,502)",
"price": "₹19T",
"link": "https://www.google.com/maps/place/Maldron+Hotel+Parnell+Square/data=!4m9!3m8!1s0x48670e87425f43a5:0x3a9fb3ca677909d8!5m2!4m1!1i2!8m2!3d53.3542501!4d-6.2666326!16s%2Fg%2F1tnsrbsp?authuser=0&hl=en&rclk=1",
"image": "https://lh5.googleusercontent.com/p/AF1QipP_ynncOvZhh0ePTQSwHH4epsGfkw77yjHa7Gdt=w128-h92-k-no"
},
{
"name": "Maldron Hotel Pearse Street",
"rating": "4.1(1,357)",
"price": "₹16.2T",
"link": "https://www.google.com/maps/place/Maldron+Hotel+Pearse+Street/data=!4m9!3m8!1s0x48670e93a8b9cf4f:0x41c16eaf5d9426f2!5m2!4m1!1i2!8m2!3d53.3431924!4d-6.2433998!16s%2Fg%2F1tfqqch0?authuser=0&hl=en&rclk=1",
"image": "https://lh5.googleusercontent.com/p/AF1QipMSkpEQi-IYxrr4JdaE0a8EYPmTY8x7D6Emx0Ha=w109-h92-k-no"
},
{
"name": "Camden Court Hotel",
"rating": "4.3(1,355)",
"price": "₹17.4T",
"link": "https://www.google.com/maps/place/Camden+Court+Hotel/data=!4m9!3m8!1s0x48670ea00dcf9391:0xb6f7edf81db77a6!5m2!4m1!1i2!8m2!3d53.3332136!4d-6.2642562!16s%2Fg%2F12jp2dxjb?authuser=0&hl=en&rclk=1",
"image": "https://lh5.googleusercontent.com/p/AF1QipPYXEV6ZlQPnrKOpgMBYusfr9ITXK59Z6tvWzsa=w184-h92-k-no"
}
]
There are still a few limitations with this as of now.
- You can only query what’s loaded initially. If you keep scrolling down the left sidebar manually, you will see more results on the website. We need to support that to get the maximum amount of data.
- These results are also paginated. You can see a previous/next button at the bottom, which lets you see more listings. We will automate scraping data from these paginated results as well.
Extra things to start scraping Google Maps as a pro
- First, we will have to figure out a way to scroll to the bottom of that left sidebar, as these results are lazy-loaded (i.e fetched only when you scroll down), we specifically need to scroll down to get 22 or so items and then click on the next page button to load more results.
- Then, we need to look for these new results and run the same scraping logic from above.
Here is a generic utility function to scroll to the end of the sidebar and load all results until done
// Scrolls till the end of the page
const scrollTillTheEnd = async (page) => {
let endOfPage = false;
let count = 0;
do {
const { _count, _endOfPage } = await page.evaluate(
(opts) => {
const { selectors: SELECTORS, count } = opts;
const allListings = document.querySelectorAll(SELECTORS.LISTING);
const newItemsCount = (allListings ? allListings.length : 0) - count;
if (allListings && allListings.length) {
allListings[allListings.length - 1].scrollIntoView();
}
const _endOfPage = newItemsCount > 0;
return {
_count: allListings.length,
_endOfPage,
};
},
{ selectors: SELECTORS, count },
);
count = _count;
endOfPage = _endOfPage;
await page.waitForTimeout(3000);
} while (endOfPage);
};
This code keeps track of current results and loops through until the new count is 0 (each loop waits for 3 secs before proceeding). If the count is 0 (i.e., the old results - new full length of results available), then we treat it as the end of the page. The setup that Google Maps has here is not easy to scrape, so I had to figure out an alternative way to get this done.
Once we know we are at the end of the page, we can scrape the data just like in the initial part of this article, only this time we will have 22 results on the page.
Now that we have figured out a way to scroll to the end of the results. We need to visit every other page, by clicking on the next button.
// Emulates pagination
const nextPage = async (page, currentPageNum) => {
const endReached = await page.evaluate(
async (opts) => {
return new Promise(async (resolve) => {
const { SELECTORS, currentPageNum, MAX_PAGE_COUNT } = opts;
const navButtons = document.querySelectorAll(SELECTORS.NAV_BUTTONS);
// const preButton = navButtons[0].parentElement;
const nextButton = navButtons[1].parentElement;
if (nextButton.disabled) {
return resolve(true);
}
// This is our on purpose condition, just for the sake of this article
if (currentPageNum === MAX_PAGE_COUNT) {
return resolve(true);
}
nextButton.click();
return resolve(false);
});
},
{ SELECTORS, currentPageNum, MAX_PAGE_COUNT },
);
if (endReached) {
return false;
}
try {
await page.waitForTimeout(3000);
} catch (error) {
// Ignoring this error
console.log(error);
}
return true;
};
- The above code looks for the the buttons, specifically next button
- Makes sure that the next button is not disabled
- Clicks on next button
- Waits for 3 seconds and returns.
Putting together all the pieces of code in this article, you will be able to scrape all the pages (tweak the MAX_PAGE_COUNT constant in the code to adjust the number of pages to be scraped). You can find the whole script here.
Running the Google Maps data scraper code in production mode
To run the script in production, you will need a browserless API key (the one you set up at the beginning of this article).
The script* final.js* from the repo can be executed in production like this.
NODE_ENV=production API_TOKEN=INSERT_YOUR_TOKEN_HERE node final.js
The final result will look like this when you execute the above command in the repo. Check out the README.md of the repository for more details.
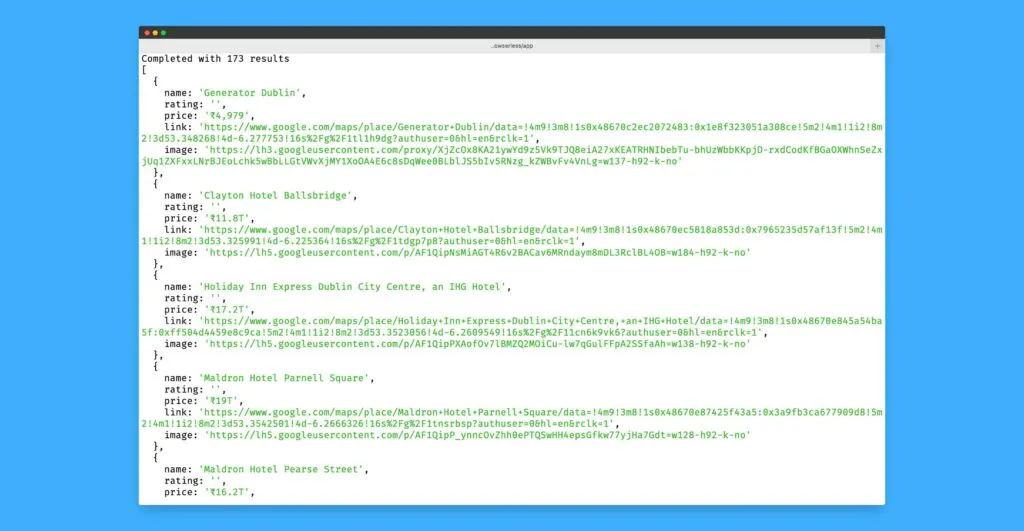
The final.js writes the results to a file final.json in the end.
Link full code setup here
What else is possible?
You can do extra with your Google Maps scraper code:
- Get more detailed data by visiting each detailed card of a listing.
- Automatically generate a PDF report for your clients who would like to profile the competitors in their area (here is the guide on how to automate PDF generation)
- Automating the creation of exciting videos from Google maps using the Screencast API.
- You can integrate this into your service, improvise with it, and provide this as a service to your customers.
Important things/notes to keep in mind
- You can also try out the docker setup of browserless.io locally to increase the speed of prototyping and testing your scripts. Reach out to sales@browserless.io about licensing for self-hosting. You can learn more about it here
- Browserless.io has a beautiful setup for development. Make sure to connect to the locally installed browser via puppeteer if you connect to your actual browserless.io setup.
- You can always keep an eye on the analytics via your browserless.io dashboard.