TL;DR
- Load balancing for scrapers. One scraper process spraying outbound work across three pools (proxies for IP reputation, browser sessions for state, workers for the queue), inverting the inbound model where N clients fan into M backends.
- Algorithms still apply. Round-robin, weighted, least-connections, exponentially weighted moving average (EWMA), and power-of-two-choices all work, just optimized for not-getting-banned instead of latency.
- Where Browserless fits. Browsers as a Service (BaaS) owns the session pool, residential proxies handle exit-IP rotation, and BrowserQL's
solveandreconnectmutations collapse bot detection and session reuse, leaving you the queue and the rate limiter.
Introduction
Proxy pools tip overnight, sessions break when an IP rotates mid-flow, and Cloudflare quietly serves challenge pages where the actual data should be. Load balancing for scrapers is the layer that catches all of that. The same algorithms inbound systems use – round-robin, weighted, least-connections, EWMA, power-of-two-choices – carry over, just tuned for not getting banned instead of low latency. In this guide you'll learn how those algorithms map to load balancing for scrapers, why coupling sessions to proxies matters more than the algorithm itself, and which parts of the build Browserless handles for you.
What is load balancing for scrapers?
Load balancing for scrapers distributes one process's outbound requests across pools of proxies, browser sessions, and workers, so no single resource burns its IP reputation, breaks a stateful session, or trips a target's rate limit. The model inverts the standard inbound one, where N clients fan into M identical backends you control.
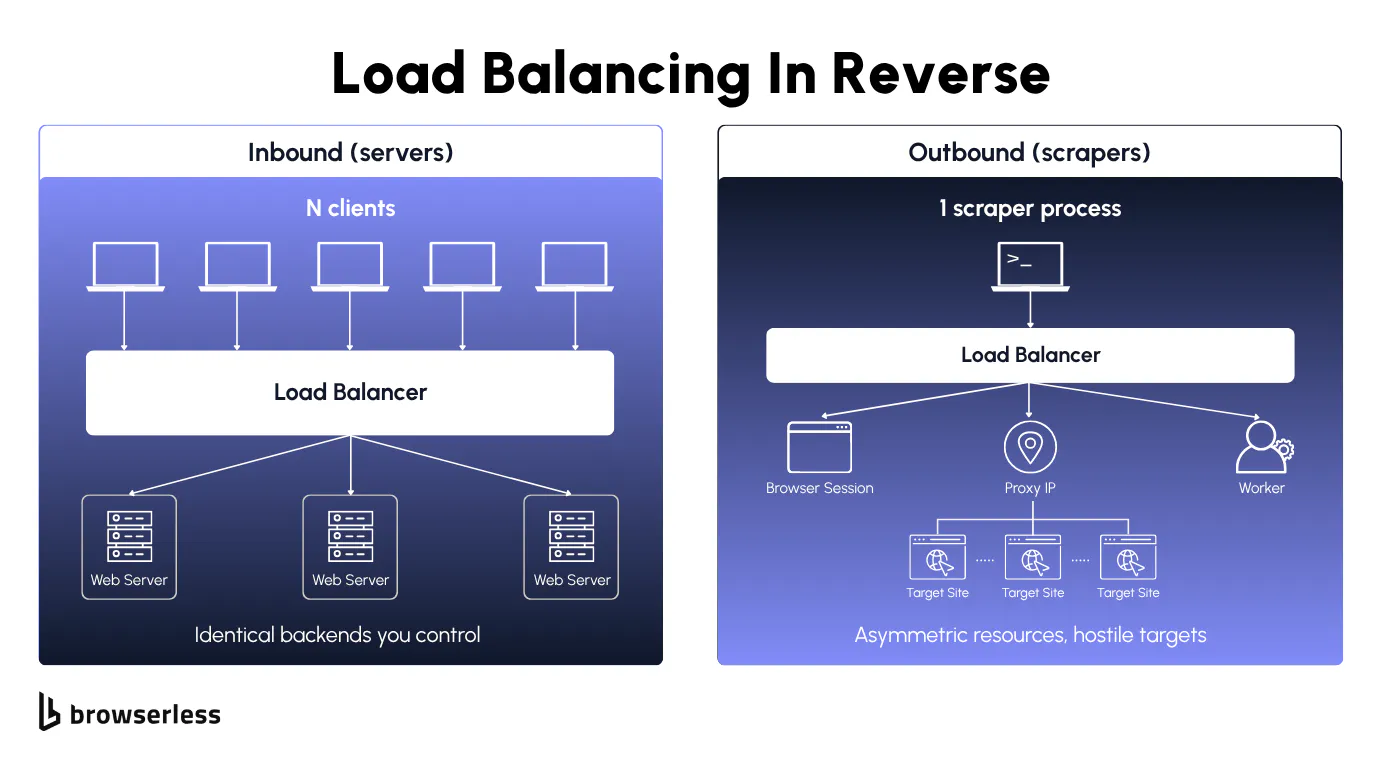
Outbound balancing inverts the inbound model
Standard server-side load balancing assumes incoming requests from N clients fanning into M identical backend servers, and the load balancer's job is to balance traffic across multiple servers for fairness and failover. Common types of load balancers (hardware load balancers, software-based load balancers, cloud load balancing in front of multiple data centers) are built for that inbound shape, where a load balancer reroutes traffic to a single server based on response time, server capacity, or the client IP address.
Outbound scraping flips it on its head, with one producer fanning into M asymmetric targets you don't control and the load-balancing work happening across your own resources. If you've ever had a health check report "all green" while requests were quietly served Cloudflare interstitials, you've seen the core problem.
Server-side balancing of the worker pool itself (DNS load balancing, global server load balancing across multiple data centers, application load balancers in front of web servers, virtual load balancers and security load balancers for web applications) is out of scope, covered in the horizontally scaling Chrome post. The vocabulary maps cleanly. "Upstream pool" becomes your proxy pool, "backend" becomes a target host plus the IP you're hitting it from, and "sticky session" becomes pinning a browser session to one exit IP for its lifetime.
The three pools you balance across
Scrapers have three pools to distribute across, with different lifecycles, costs, and rotation rules. Get the layering wrong and you'll burn money rotating things that didn't need rotating, or get banned rotating things that did. In order of cost:
- Proxy pool. IPs (residential, datacenter, mobile) with a finite reputation budget. Rotating costs continuity.
- Browser session pool. Browsers driven by
Puppeteer,Playwright, orBrowserQL. Each one takes seconds and a few hundred MB to spin up, so don't throw them away after a single page. - Worker pool. Processes pulling jobs off a queue. The closest analog to a fleet of individual servers behind a classic load balancer.
Rotation triggers vary by pool:
- Proxy pool. Rotate on IP reputation drops or after a hard request cap against a particular server.
- Session pool. Hold until lifecycle boundaries (login, cart, logout) or hard caps like 50 requests or 10 minutes.
- Worker pool. Pull a new job every event-loop iteration. Server availability and capacity dictate how many workers a single host can absorb at once.
Load balancing algorithms applied to outbound scraping
The same load balancing methods server-side load balancers run (round-robin, weighted round robin, least-connections, EWMA, power-of-two-choices, IP hash (covered under consistent hashing below)) carry over to scrapers, but the metric you're optimizing for shifts from latency to not getting banned. Which static or dynamic algorithm fits depends on whether the proxy pool is homogeneous, whether sessions need to stick to one IP, and how much shared state the workers can tolerate.
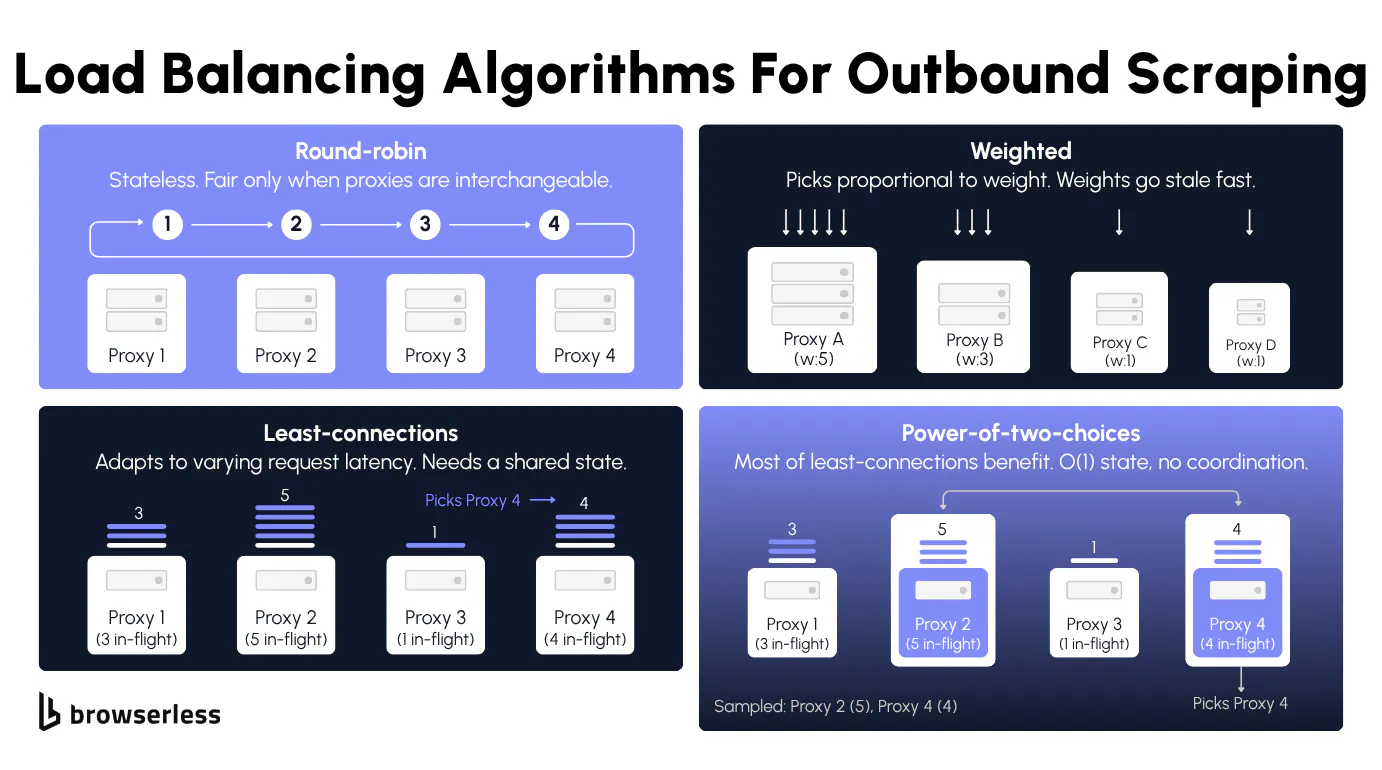
Static load balancing algorithms: round-robin and weighted rotation
Round-robin is usually the first algorithm anyone reaches for. A counter that increments per request and selects proxies[counter % len(proxies)] is two lines of code, deterministic, and fair when proxies are interchangeable. It breaks the moment your pool is heterogeneous, since a fresh residential IP and a 30-day-old datacenter IP are not equivalent but round-robin sends them the same volume.
Weighted rotation is the next step. Each proxy gets an integer weight from something measurable (success rate over the last 100 requests, reputation score, days since the last flag), and random.choices(proxies, weights=weights) skews traffic toward proxies that work. Weights go stale fast, so you need a feedback loop that recomputes them from real outcomes rather than a config from three weeks ago.
Both algorithms are stateless, which makes them trivial to deploy across workers as long as they share a counter (a Redis INCR works fine):
import random
from collections import Counter
# Replace with real proxy URLs (.example is reserved per RFC 6761).
PROXIES = [f"http://proxy-{c}.example:8080" for c in "abcd"]
WEIGHTS = [10, 5, 3, 1]
def pick_round_robin(proxies, counter):
return proxies[counter % len(proxies)]
def pick_weighted(proxies, weights):
return random.choices(proxies, weights=weights, k=1)[0]
# Sample 1000 picks. Higher-weight proxies should dominate the count.
samples = [pick_weighted(PROXIES, WEIGHTS) for _ in range(1000)]
print(Counter(samples))
Dynamic load balancing algorithms: least-connections, EWMA, and power-of-two-choices
When the work isn't uniform across proxies, static algorithms start over-sending to whichever proxy is already struggling. Least connections fixes that by tracking an in-flight counter per (proxy, host) pair and routing new requests to the proxy with the fewest active connections. EWMA (exponentially weighted moving average) of response time gives a rolling latency signal that decays old samples, so you favor proxies that are fast right now rather than ones that were fast last week.
Power-of-two-choices is the algorithm you'll want most of the time. You pick two random proxies and choose whichever has the lower in-flight count. That trick gets you most of the benefit of full least-connections with O(1) state and no shared coordination, which is why Envoy and Linkerd both use it. For sticky workloads where a session must keep the same exit IP, consistent hashing on (target_host, session_id) pins the session to one proxy until you explicitly rotate.
The mental shortcut is to use power-of-two-choices by default, consistent hashing when sessions are sticky, and round-robin only when your pool is genuinely homogeneous (which it almost never is). A minimal P2C scheduler looks like this:
import random
from collections import Counter
class Scheduler:
def __init__(self, proxies):
self.in_flight = {p: 0 for p in proxies}
def pick(self):
# Sample two random proxies, return the one with fewer in-flight requests.
a, b = random.sample(list(self.in_flight.keys()), 2)
chosen = a if self.in_flight[a] <= self.in_flight[b] else b
self.in_flight[chosen] += 1
return chosen
def release(self, proxy):
self.in_flight[proxy] = max(0, self.in_flight[proxy] - 1)
proxies = [f"http://proxy-{c}.example:8080" for c in "abcdef"]
scheduler = Scheduler(proxies)
picks = Counter()
# Mixed load: 30% slow, 70% fast. P2C avoids slow proxies since they stay in-flight longer.
in_progress = []
for tick in range(50):
proxy = scheduler.pick()
picks[proxy] += 1
ticks = 5 if random.random() < 0.3 else 1
in_progress.append([proxy, ticks])
still_running = []
for entry in in_progress:
entry[1] -= 1
if entry[1] <= 0:
scheduler.release(entry[0])
else:
still_running.append(entry)
in_progress = still_running
print(picks.most_common())
Two-axis load balancing and health checks that lie
Outbound scraping balances two things at once: your compute (sessions, workers) and your IP space (proxies). The sticky-vs-rotating choice on each side decides whether you blend in or get banned, which is why your health checks also have to look past the status line, since a 200 OK from a hostile target rarely means what it looks like.
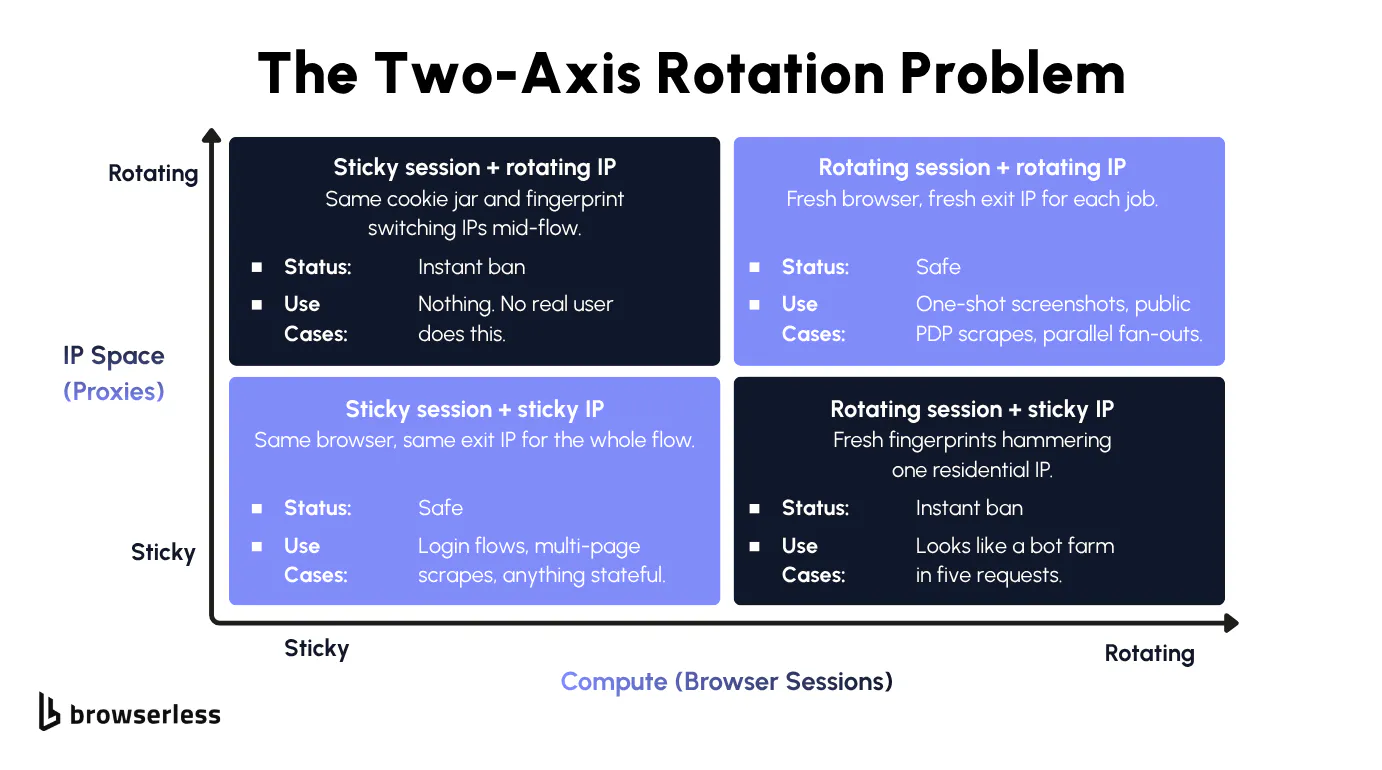
Coupling proxy rotation with session lifecycle
Outbound balancing has an extra dimension inbound doesn't. You're moving two things at once (the compute and the exit IP), and they have to move in sync. Let them drift apart and you'll trip detection in ways your request logs make hard to debug.
A rotating IP on a sticky browser session is one of the highest-signal bot tells, since the site sees the same cookie jar and fingerprint switching IPs mid-flow. A rotating session on a sticky IP is the symmetric failure, since every fresh fingerprint hitting the same residential IP looks like a bot farm. The valid combinations are sticky-sticky (login flows, multi-page scrapes) and rotate-rotate (one-shot screenshots, public product detail page (PDP) scrapes, parallel fan-outs).
In Browsers as a Service (BaaS), proxySticky on the connection URL couples the two axes so session and IP share a lifecycle:
import puppeteer from "puppeteer-core";
// proxyCountry only applies when proxy=residential is set. proxySticky is a bare flag.
const browserWSEndpoint =
`wss://production-sfo.browserless.io?token=${process.env.BROWSERLESS_TOKEN}` +
`&proxy=residential&proxyCountry=us&proxySticky`;
const browser = await puppeteer.connect({ browserWSEndpoint });
const page = await browser.newPage();
// Both navigations should print the same exit IP. proxySticky is best-effort, not a guarantee.
await page.goto("https://api.ipify.org?format=json", {
waitUntil: "domcontentloaded",
});
const firstIp = JSON.parse(await page.evaluate(() => document.body.innerText)).ip;
console.log(`First request: ${firstIp}`);
await page.goto("https://api.ipify.org?format=json", {
waitUntil: "domcontentloaded",
});
const secondIp = JSON.parse(await page.evaluate(() => document.body.innerText)).ip;
console.log(`Second request: ${secondIp}`);
await browser.close();
If both printed IPs match, the sticky pair held. If they don't, the residential add-on isn't enabled or the sticky parameter wasn't applied. Pin the sticky-or-rotate decision to the scheduler, not the worker, or you'll oscillate between the two failure modes per request.
Application-level health checks and per-host rate limiting
A 200 OK lies when the body is a Cloudflare challenge, a Datadome interstitial, or a thin single-page app (SPA) shell, so your server health check has to read the response, not just the status line. The cheap signals to score live in the HTTP headers and body: a response under 5 KB on a page that should be 100 KB, a cf-mitigated or Server: cloudflare header paired with a JS challenge, a missing canonical selector, or a redirect chain ending on /captcha. Any single signal is a hint, any two together confirm a soft block, and the difference between catching it and missing it is the difference between application availability and silent failure across your worker pool.
Per-host concurrency caps prevent the "100 workers all hammering one host" mode that flags your whole proxy pool in a single autonomous-system (ASN) sweep. Cap the concurrent in-flight requests per (target_host, proxy_subnet) pair, and enforce it in the scheduler before the request fires.
Token-bucket rate limiting per host adds smooth back-pressure on top. Refill N tokens per second, take one before each request, sleep when empty, halve the refill rate the moment any worker sees a soft block from that host. That last step is load-bearing. A 429 on a single proxy is rarely a single-proxy problem since neighbors in the same ASN tend to share fate, so honor Retry-After and back off the whole pool.
The full implementation has three pieces. First, the soft-block detector that reads bodies, headers, and status:
import requests
SOFT_BLOCK_STATUS = {403, 429, 503}
MIN_BODY_BYTES = 5 * 1024 # 5 KB
CLOUDFLARE_BODY_MARKERS = ("Just a moment", "cf-challenge", "Attention Required")
def is_soft_block(response):
"""Return True if the response looks like an interstitial or thin shell."""
if response.status_code in SOFT_BLOCK_STATUS:
return True
if "cf-mitigated" in {k.lower() for k in response.headers.keys()}:
return True
server = response.headers.get("Server", "").lower()
if "cloudflare" in server and any(
m.lower() in response.text.lower() for m in CLOUDFLARE_BODY_MARKERS
):
return True
if len(response.content) < MIN_BODY_BYTES:
return True
return False
Next, the token bucket gives smooth per-host pacing with a refill rate you dial down when soft blocks show up:
import time
class TokenBucket:
def __init__(self, tokens=2, refill_rate=1.0, max_tokens=None):
self.tokens = float(tokens)
self.refill_rate = float(refill_rate) # tokens per second
self.max_tokens = float(max_tokens if max_tokens is not None else tokens)
self.last_refill = time.monotonic()
def _refill(self):
now = time.monotonic()
elapsed = now - self.last_refill
self.tokens = min(self.max_tokens, self.tokens + elapsed * self.refill_rate)
self.last_refill = now
def acquire(self):
"""Block until a token is available, then consume it."""
while True:
self._refill()
if self.tokens >= 1:
self.tokens -= 1
return
time.sleep((1 - self.tokens) / self.refill_rate)
def slow_down(self, factor=0.5):
"""Halve the refill rate when any worker sees a soft block from this host."""
self.refill_rate = max(0.1, self.refill_rate * factor)
Tie them together with a request helper the worker loop calls directly:
from urllib.parse import urlparse
import requests
def make_request(url, host_buckets, default_rate=1.0, default_tokens=2):
"""
Acquire a token for the URL's host, fire the GET, classify the response.
Returns (ok, response). ok=False means the response looked like a soft block.
"""
host = urlparse(url).netloc
if host not in host_buckets:
host_buckets[host] = TokenBucket(tokens=default_tokens, refill_rate=default_rate)
bucket = host_buckets[host]
bucket.acquire()
response = requests.get(url, timeout=15)
if is_soft_block(response):
# A flag on one IP is shared-fate across the ASN, so slow everyone down.
bucket.slow_down(0.5)
return False, response
return True, response
# Per-host buckets persist across calls so the rate state is shared.
host_buckets = {}
ok, resp = make_request("https://books.toscrape.com/", host_buckets)
print(f"ok={ok} status={resp.status_code} bytes={len(resp.content)}")
To skip writing this layer yourself, the in-session route is ?solveCaptchas=true on the same BaaS connection. For cookie walls, use the blockConsentModals option in BrowserQL or pass it as a parameter to the REST APIs (/screenshot, /pdf). When the site detects Chrome DevTools Protocol (CDP) itself, escalate to the /unblock REST endpoint, which handles Cloudflare and Datadome interstitials and returns HTML, cookies, or a browserWSEndpoint you resume against with puppeteer.connect().
Load balancing with Browserless: BaaS, residential, and BrowserQL
Browserless replaces three of the most painful boxes in an outbound load balancing stack. BaaS owns the session pool, residential proxies handle exit-IP rotation, and the BrowserQL (BQL) solve and reconnect mutations collapse bot detection and session reuse into one declarative flow. The queue, rate limiter, and reputation tracker stay with the application.
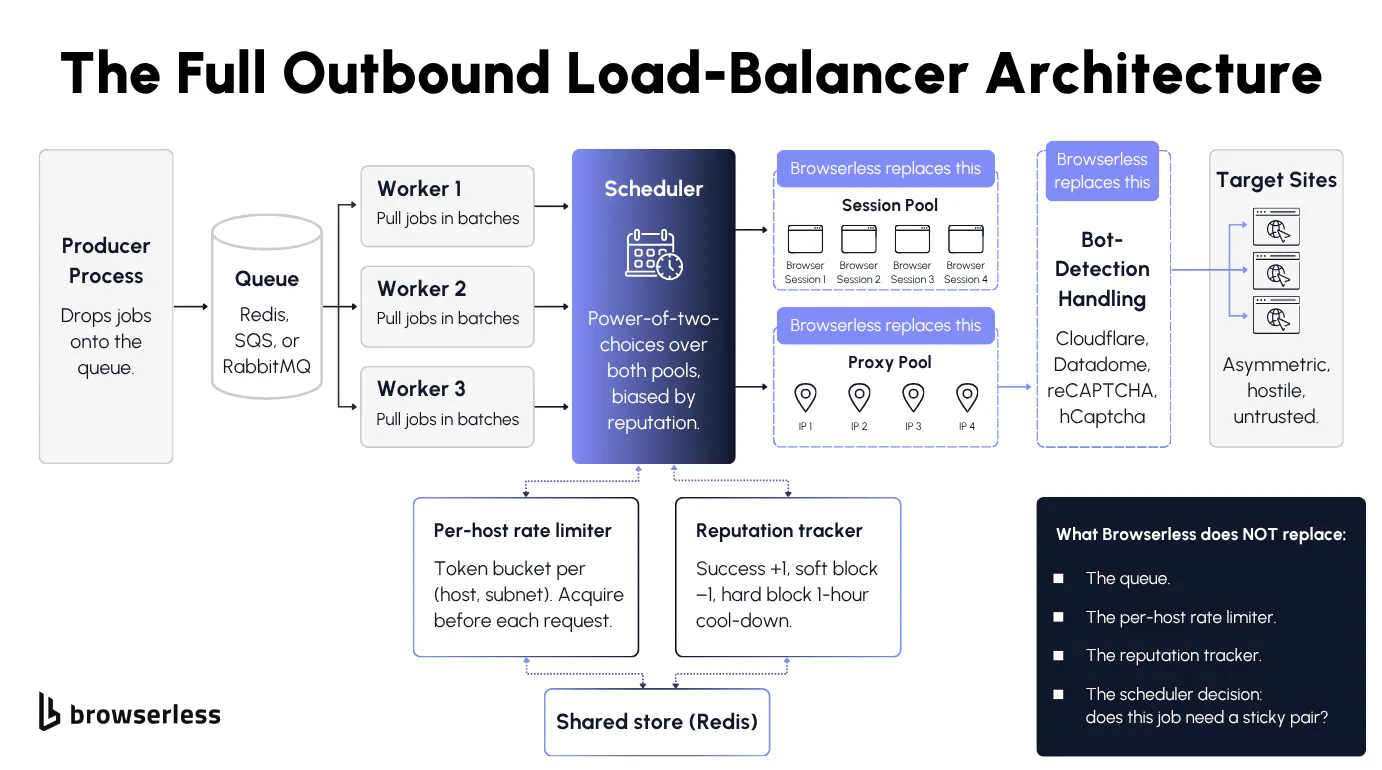
The full outbound load-balancer architecture
The full picture has more moving parts than the average write-up shows. A producer-consumer queue (Redis, SQS, RabbitMQ) holds jobs, each one carrying a target URL plus scheduling metadata (sticky pair needed, session profile, proxy country).
Workers pull jobs in batches and ask a scheduler for a session-and-proxy pair. The scheduler runs power-of-two-choices over both pools, biased by what the reputation tracker last saw, and assigns the pair the way a classic load balancer assigns a backend across data centers. A per-host rate limiter sits between the scheduler and the network, and any pair the scheduler picks has to acquire a token for the target host before it can route requests.
Behind it all, the reputation tracker writes outcomes back, nudging a proxy's score up on success, pulling both the proxy and its ASN down on a soft block, and putting the proxy in a one-hour cool-down on a hard block so the upstream target has time to forget about it. Every component in this chain needs an explicit "no" output (no eligible pair, wait, soft block) the worker knows how to handle, otherwise you'll silently degrade into a system that thinks it's working while every request comes back blocked.
Where Browserless replaces the build (BaaS, residential proxies, BQL)
Most of the architecture above is plumbing you don't want to own. Browserless collapses three of the most painful boxes into managed components.
BaaS replaces the session pool. Call puppeteer.connect() against a Browserless WebSocket and the session lifecycle is managed for you. BaaS with ?proxy=residential&proxyCountry=us replaces proxy rotation, since Browserless owns the residential IP pool and rotates per request by default, with proxySticky available to hold the same IP for the session (best-effort). Adding proxyLocaleMatch=1 on stealth endpoints automatically sets the browser's language to match the proxy's country, which reduces locale-mismatch detection signals.
BrowserQL's solve and reconnect mutations replace the bot-detection-plus-session-reuse layer. solve auto-detects and handles CAPTCHAs (Cloudflare challenges, reCAPTCHA, hCaptcha, and others), and reconnect returns a browserQLEndpoint so the next query reuses the same browser, cookies, and IP. The cutting proxy usage with reconnects post has the full implementation.
Browserless doesn't replace the queue, rate limiter, reputation tracker, or the scheduler decision about sticky vs. rotate. Those stay yours because they encode your business rules.
The canonical Browserless escalation is Stealth Routes → residential proxies → solveCaptchas=true in-session → /unblock → BrowserQL solve → liveURL:
- BaaS. Plain scrapes that just need a clean Chrome. Fastest path to working code.
- BaaS plus Stealth Route and residential. Targets that check IP reputation. Stealth Routes (
/stealth,/chromium/stealth,/chrome/stealth) plusproxy=residentialcover most manual hardening. - Same connection plus
solveCaptchas=true. When the only blocker is a CAPTCHA mid-session, stay in the same Puppeteer/Playwright session. /unblockREST endpoint. Sites that detect CDP itself (not just CAPTCHA). Returns HTML, cookies, screenshot, or abrowserWSEndpoint.- BrowserQL with
reconnect. Heavy targets that need multi-step handling and session reuse across many queries. liveURLfallback. Last resort when auto-solve fails. Generates a URL a human can open to solve manually.
The first two tiers are URL parameter swaps on the same puppeteer.connect() call. Bare BaaS for plain scrapes, /stealth plus proxy=residential when targets check IP reputation:
import puppeteer from "puppeteer-core";
const TOKEN = process.env.BROWSERLESS_TOKEN;
// Tier 1: bare BaaS, plain Chrome, no proxy.
const bareWS = `wss://production-sfo.browserless.io?token=${TOKEN}`;
// Tier 2: /stealth route plus residential proxy on the same connect() call.
const stealthWS =
`wss://production-sfo.browserless.io/stealth?token=${TOKEN}` +
`&proxy=residential&proxyCountry=us`;
// Using stealthWS so the IP check returns a residential exit. Swap to bareWS when stealth isn't needed.
const browser = await puppeteer.connect({ browserWSEndpoint: stealthWS });
const page = await browser.newPage();
await page.goto("https://api.ipify.org?format=json", {
waitUntil: "domcontentloaded",
});
const exitIp = JSON.parse(await page.evaluate(() => document.body.innerText)).ip;
console.log(`Exit IP: ${exitIp}`);
await browser.close();
For heavy targets that need bot detection handling and session reuse, BQL with reconnect collapses the remaining layers:
const TOKEN = process.env.BROWSERLESS_TOKEN;
const BQL_ENDPOINT = `https://production-sfo.browserless.io/chromium/bql?token=${TOKEN}`;
// solve returns false/false when no challenge fires. reconnect returns a browserQLEndpoint to reuse.
const startSession = `
mutation StartSession {
goto(url: "https://books.toscrape.com", waitUntil: networkIdle) {
status
}
solve(type: cloudflare) {
found
solved
}
reconnect(timeout: 30000) {
browserQLEndpoint
}
}`;
const followUp = `
mutation FollowUp {
title { title }
}`;
async function postBQL(url, query) {
const r = await fetch(url, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query }),
});
return r.json();
}
const start = await postBQL(BQL_ENDPOINT, startSession);
const reconnectUrl = start.data.reconnect.browserQLEndpoint + `?token=${TOKEN}`;
// Reuse the same browser session, with cookies, IP, and page state carrying over.
const result = await postBQL(reconnectUrl, followUp);
console.log(`Page title via reconnected session: ${result.data.title.title}`);
Two fields are easy to confuse. The ttl on POST /session is the session's lifetime in milliseconds (max varies by plan – 1 day on Free, up to 90 days on Scale), while the timeout on reconnect is a separate keep-alive window between disconnect and reconnect (10 seconds on Free, up to 5 minutes on Scale).
Conclusion
The same static and dynamic algorithms (round-robin, weighted, EWMA, power-of-two-choices) work for outbound scraping, just tuned for not getting banned instead of low latency. The algorithm matters less than coupling sessions to proxies and trusting body content over status codes when a soft block fires. The queue, rate limiter, and reputation tracker stay yours since they encode your business rules, while the session pool, proxy rotation, and bot detection are generic enough to outsource to Browserless on one account with high availability and fault tolerance included. Spin up a free Browserless account and skip the parts you don't want to own.
FAQs
What is the best load balancing algorithm for web scraping?
Power-of-two-choices is the practical default for outbound scraping. It gets near-optimal distribution from O(1) state per worker, without the shared counter that least-connections needs. Round-robin is only the right answer when your pool is genuinely homogeneous, which is rarer than it looks. Consistent hashing wins when sessions must stick to one IP for their lifetime, since it pins the pair without needing a central coordinator.
How do you load balance browser sessions?
Separate the session pool from the proxy pool, since their lifecycles differ. Sessions rotate on lifecycle events (login, cart, logout) or hard caps (50 requests, 10 minutes), while proxies rotate on reputation signals. Pick session-and-proxy pairs at scheduling time using power-of-two-choices with a reputation bias, not at request time. If you don't want to manage the pool yourself, BaaS handles session creation, rotation, and teardown for you.
What is the difference between round-robin and least-connections proxy rotation?
Round-robin is stateless and cycles through proxies in order. It's only fair when the proxies are genuinely interchangeable. Least-connections tracks the in-flight count per proxy and sends new work to the least-loaded one, which adapts to heterogeneous request latency but needs shared state across workers. The shared-state requirement is what makes least-connections harder to scale, which is why many modern systems (including Envoy and Linkerd) approximate it with power-of-two-choices instead.
Can you load balance scraping requests with NGINX?
NGINX load-balances inbound traffic to your worker pool, for example using least_conn in front of a Browserless cluster, but it cannot rotate outbound proxies since it sees one downstream backend per upstream definition. You need a separate in-process scheduler for proxy selection, sitting inside your worker process or as a sidecar. NGINX solves the inbound side of your system, not the outbound side, and the two problems don't overlap. Folding outbound proxy rotation into NGINX config means fighting the tool the whole way.
How do you handle sticky sessions when rotating proxies?
Bind the session to an exit IP at scheduling time, either via consistent hashing on (host, session_id) in your own scheduler or via proxySticky on Browserless BaaS (best-effort sticky, the proxy network keeps the IP when possible, not on every request). Don't rotate the IP mid-session by your own action, only at session boundaries, since mid-flow IP changes are one of the highest-signal bot tells a target can read. If you need a fresh IP for a new flow, also start a fresh browser session with a fresh fingerprint. The point is to keep the IP, the cookies, and the fingerprint moving together as a unit.