TL;DR
- Federated GraphQL. A pattern where multiple GraphQL services (subgraphs) compose into one unified schema behind a single endpoint, so clients query one API while teams own their own domains.
- Orchestration layer. GraphQL's declarative requests let the server coordinate data and logic across boundaries, shifting complexity off the client and into a structured execution plan.
- In BrowserQL. A single GraphQL schema exposes browser actions (
goto,click,text,screenshot) plus higher-level capabilities like bot detection handling and CAPTCHA solving. - Where Browserless fits. Sending one BrowserQL mutation against
production-sfo.browserless.io/chromium/bql(or/stealth/bqlfor stealth-first scraping) replaces the sequence of REST calls a typical scraper or test would otherwise chain.
Introduction
If you've shipped a GraphQL service in the last few years, you've probably watched what started as one clean schema fracture as more teams hit it. As applications split into multiple services, a single shared schema becomes the bottleneck instead of the unifier. Federated GraphQL solves this by composing independent services into one unified graph, where you hit one endpoint while each team keeps ownership of its own domain. BrowserQL borrows the same single-graph pattern at a smaller scale: instead of multiple subgraphs, it exposes browser actions as fields on one GraphQL schema, so a single mutation replaces a chain of REST calls. The rest of this article walks through how federation works and why a GraphQL-native approach makes browser automation simpler.
What is federated GraphQL?
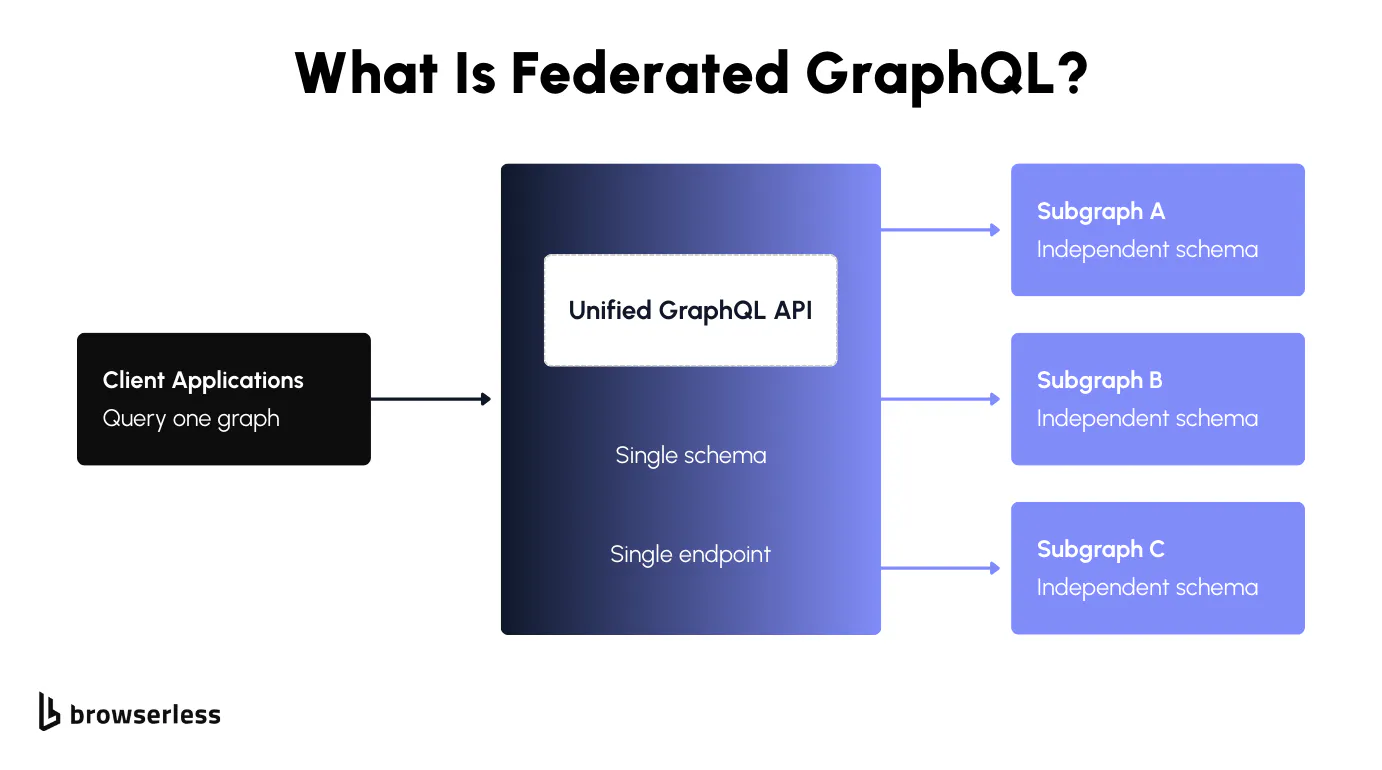
The problem federation solves in GraphQL architectures
Early on, most teams built a single GraphQL schema that covered the entire system. It worked fine at first, but as the codebase grew, that monolith became a bottleneck. Different teams owned different slices (customer data, billing, reviews, authentication), but they all lived within a single schema.
Changing anything meant coordinating with everyone. Schema validation slowed to a crawl, and nobody was quite sure who owned what. Federated GraphQL changes that model. Instead of a single monolithic GraphQL API, teams define separate services, called subgraphs, that represent their respective domains.
Each subgraph schema is owned and maintained independently, yet together they form a federated graph. For example, a users service might define a User type, while a reviews service extends it:
# Users subgraph
type User @key(fields: "id") {
id: ID!
name: String
email: String
}
# Reviews subgraph (Apollo Federation v2 syntax)
type User @key(fields: "id") {
id: ID!
reviews: [Review]
}
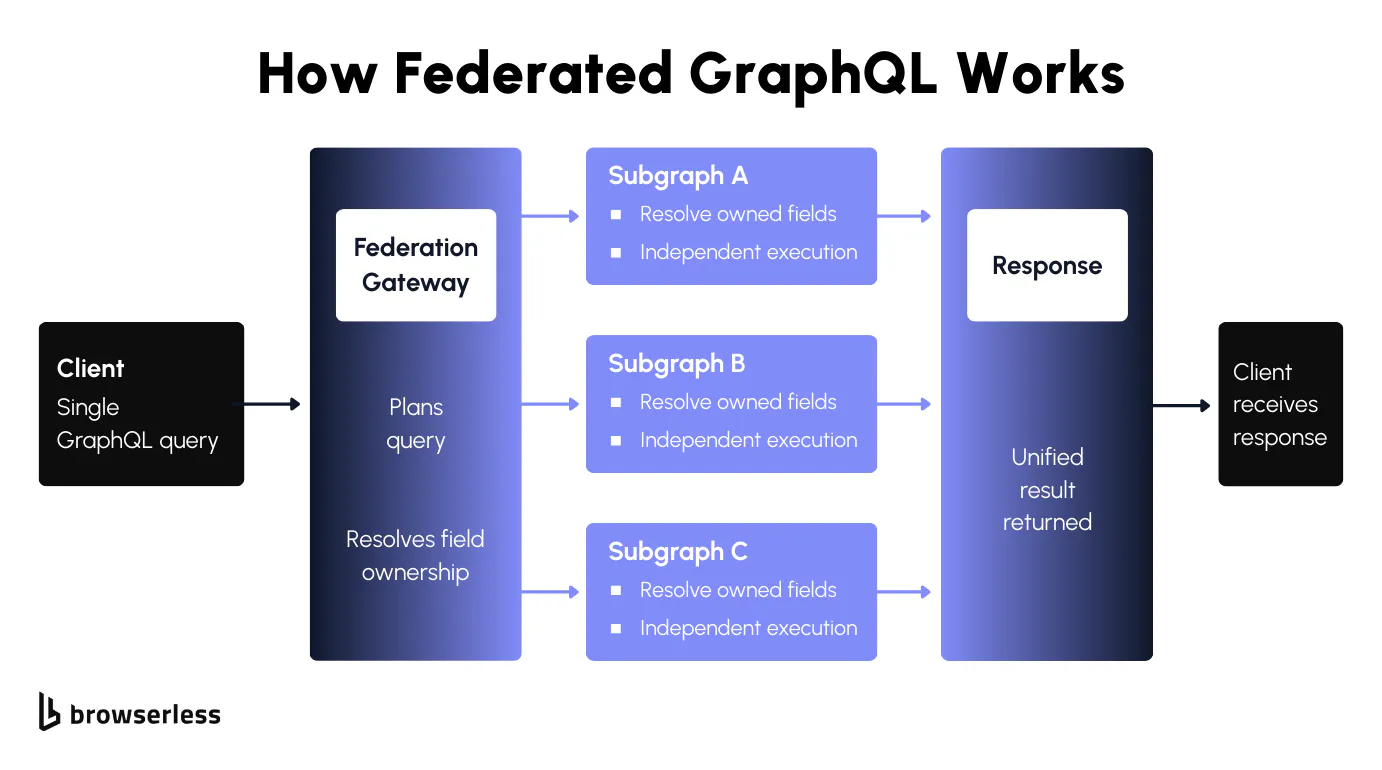
How federated GraphQL works at a high level
Federated GraphQL combines multiple subgraphs into a single schema. Each subgraph defines part of the data model, and a federation gateway handles composing them together and routing queries to the right place. The gateway doesn't duplicate anything. It links types across subgraphs while keeping ownership boundaries intact. Once subgraphs are registered, the gateway exposes one endpoint:
query GetUserWithReviews {
user(id: "1") {
name
reviews {
rating
comment
}
}
}
The client sends a single request. The federation gateway determines which subgraph is responsible for each field, plans the query, and distributes the request to the appropriate subgraphs.
It then merges the results into a single response. To the client, it's just one graph: independent services that still feel like one API.
Why GraphQL fits federated systems
Schema-driven composition
In GraphQL, the schema doubles as a contract. Every type, field, and relationship is explicitly defined, making ownership across services unambiguous.
Each team owns and maintains its own subgraph schema, and those schemas compose into a unified whole. Strong typing and explicit field definitions allow safe composition across multiple GraphQL services without ambiguity.
Federation directives extend this further:
@requires– Marks fields from another subgraph that this one depends on.@provides– Hints that a subgraph can resolve specific fields without an extra hop.@shareable– Marks a field that can resolve from more than one subgraph.
Together they let the gateway plan queries efficiently while preserving each team's ownership boundary.
Compared to a monolith or REST APIs with fixed endpoints, schema-driven composition gives each team a clear contract for what they own and what they expose.
Declarative queries across boundaries
GraphQL's declarative model means you describe what you want, not how to get it.
A client might request:
query GetUserData {
user(id: "1") {
name
orders {
total
}
}
}
From the client's perspective, this is a single request to one endpoint. The gateway figures out which subgraph owns each field, fetches them, merges everything, and hands back a single response, so the client code stays the same with two services or twenty.
How BrowserQL applies GraphQL principles to browser automation

The hidden complexity of endpoint-based automation
Most browser automation platforms work like this: every action is a separate endpoint or command. A typical workflow ends up looking like this:
- One request to navigate.
- Another request to click.
- Another request to extract data.
- Another request to capture a
screenshot. - Another request to verify page state.
Every step is another round-trip, another piece of state to track, another place where error handling lives. Workflows get more complex, and the orchestration logic piles up on the client side. That fragmentation is what GraphQL was designed to solve for data APIs, and BrowserQL solves it for browser automation.
Why browser automation maps naturally to GraphQL
Browserless exposes managed browsers through several integration shapes: REST APIs for one-off tasks, BaaS v2 for connecting existing Puppeteer or Playwright code over WebSocket, BrowserQL for GraphQL-native workflows, plus AI integrations layered on top. BrowserQL is the shape this article focuses on.
A typical browser automation flow involves navigation, clicking, extracting data, validating results, and sometimes branching based on what you find. With most REST automation patterns, each step in a workflow is a separate request and the client has to thread state between them. Browserless's own REST APIs collapse some of this with action-oriented endpoints like /scrape and the multi-step /function endpoint, but BrowserQL takes it further: a full multi-step flow lands in a single declarative mutation that the system coordinates internally.
mutation AutomateDashboard {
goto(url: "https://news.ycombinator.com", waitUntil: domContentLoaded) {
status
}
headline: text(selector: ".titleline > a") {
text
time
}
}
The BrowserQL execution engine resolves each field in order: navigate, then extract a scoped value from the page. One request handles what would otherwise be multiple separate API calls.
BrowserQL as a composable automation graph
BrowserQL models browser capabilities within a unified GraphQL schema. Navigation, interaction, extraction, and validation are fields defined in the schema, forming a single graph that represents automation behavior.
Traditional automation APIs expose low-level browser primitives and leave the orchestration to you. BrowserQL pulls bot detection handling, CAPTCHA solving, session management, and residential proxying into the graph as first-class operations. Workflows like bypassing Cloudflare protection, extracting authenticated data, and validating results become a single structured mutation instead of scattered endpoint calls.
Each capability is modular and focused. New capabilities slot into the existing schema without restructuring the API, and existing capabilities can evolve without breaking the others.
mutation ExtractProfileData {
goto(url: "https://www.browserless.io") {
status
}
heading: text(selector: "h1") {
text
}
subheading: text(selector: "h2") {
text
}
}
Mutations define intent rather than imperative steps. The system handles state transitions and error handling internally. Composition scales better than centralization, and BrowserQL applies that principle to automation.
Conclusion
Federated GraphQL solves the problem of scaling complexity across services without losing API clarity. BrowserQL applies the same principles to browser automation: define the entire workflow in a single structured mutation, and the system handles orchestration and state transitions internally. If you're building scraping pipelines, AI agents, monitoring systems, or data extraction workflows, sign up for a free Browserless account and try expressing your next automation flow as a single graph instead of a sequence of endpoints.
FAQs
Is federated GraphQL the same as schema stitching?
No. Schema stitching merges schemas at the gateway by manually mapping types from one to another, with the gateway holding all the cross-service logic. Federation pushes that responsibility into the subgraphs themselves through directives like @key, @requires, and @provides, so the gateway just composes what each subgraph already declares. Federation scales better because subgraph teams don't have to coordinate gateway changes when they evolve their schemas.
Does federated GraphQL require Apollo?
No. Apollo Federation is the most widely adopted spec and the term most people mean by "federated GraphQL", but the underlying concept (independent subgraphs composed by a gateway via shared directives) is also implemented by alternatives like Hot Chocolate's Fusion, GraphQL Mesh, and WunderGraph. They differ in directive support, schema-registry tooling, and runtime behavior, but the architectural shape is the same.
Why use federated GraphQL instead of REST APIs?
REST requires a separate call for each service, and the client has to merge the results. With federation, one request spans all services, and the gateway handles the merging. It also supports parallel fetches across subgraphs, so you get better performance without more client complexity.
What is the role of a schema registry in federation?
A schema registry manages the set of subgraph schemas and validates compatibility before any change is published to the gateway. With Apollo Federation, this protects the federated schema from breaking updates and lets teams evolve their subgraphs independently without coordinating gateway deployments.
What's the difference between Apollo Router and Apollo Gateway?
Apollo Gateway is the original Node.js federation gateway that Apollo built around Federation v1 and v2. Apollo Router is its current product: a Rust-based replacement that handles the same composition role but with better performance and a wider feature set (caching, traffic shaping, distributed query planning). New federated deployments default to Router; Gateway is in maintenance mode.