TL;DR
- Data extraction. Pulling clean, structured data out of websites that weren't designed to hand it over, not the same as BI/ETL (databases to warehouse) or OCR (scanned documents).
- The 5-step ladder. Static HTML, the
/scrapeREST API, self-hosted Puppeteer, managed Browsers as a Service (BaaS v2), and BrowserQL stealth. Each step has a clear failure signal (empty result, login redirect, Cloudflare block) that tells you when to climb. - Where Browserless fits. Browserless handles steps 2–5: the
/scrapeREST API renders pages at step 2, BaaS connects your Puppeteer code over WebSocket at step 4, BrowserQL'ssolveclears Cloudflare and reCAPTCHA at step 5, and/smart-scraperuns the whole ladder in one call.
Introduction
Scrapers come back empty even when the data loads fine in Chrome, redirects bounce them to login pages, and Cloudflare quietly serves block screens where the article body should be. Data extraction on the modern web hides four different failure modes behind one URL bar (static pages, JS-rendered apps, infinite-scroll feeds, sites that block automated traffic), and the trick is recognizing which one broke before reaching for a heavier tool. In this guide you'll learn each step on the ladder, when to climb to the next, and where Browserless replaces parts of the build.
What is web data extraction?
Data extraction on the modern web means pulling structured, semi-structured, and unstructured data out of web pages, JS-rendered single-page apps (SPAs), and network responses, then transforming the raw data into a usable format for data storage and analysis. It's distinct from BI/ETL extraction (databases to a data warehouse) and document extraction (PDFs plus OCR). The rest of this piece covers only the web-scraping lane.

The three intents behind "data extraction"
"Data extraction" covers three different jobs, each with its own toolchain, and mixing them up sends you to the wrong stack before you've started.
BI/ETL extraction pulls rows from multiple sources (relational databases, SQL Server, SaaS APIs) into a data warehouse using tools like Fivetran, Airbyte, or dbt, where batch processing handles full extraction overnight and change data capture handles incremental extraction in near-real-time. That's business intelligence and data mining territory, and it's a different stack from the one covered here.
Document and AI extraction turns PDFs, scanned forms, and emails into structured fields via OCR plus natural language processing, and it's the right lane for customer data buried in invoices, sensitive data in scanned contracts, financial data trapped in legacy PDFs, or electronic health records pulled from imaging. The longer intelligent data extraction write-up covers that stack in detail.
Web data extraction is the messy one, pulling structured data out of HTML pages, JS-rendered apps, and JSON returned by network calls inside the browser, and it's the lane the 5-step ladder addresses.
Why data extraction methods form a ladder, not a flat menu
Every data extraction tool has a domain where it works and a sharp edge where it stops, and listicles hide that edge, which is why people keep getting blocked, rate-limited, fingerprinted, or outright banned with a tool that worked perfectly on a different page yesterday. Many data extraction challenges trace back to using the wrong tool for the step you're actually on.
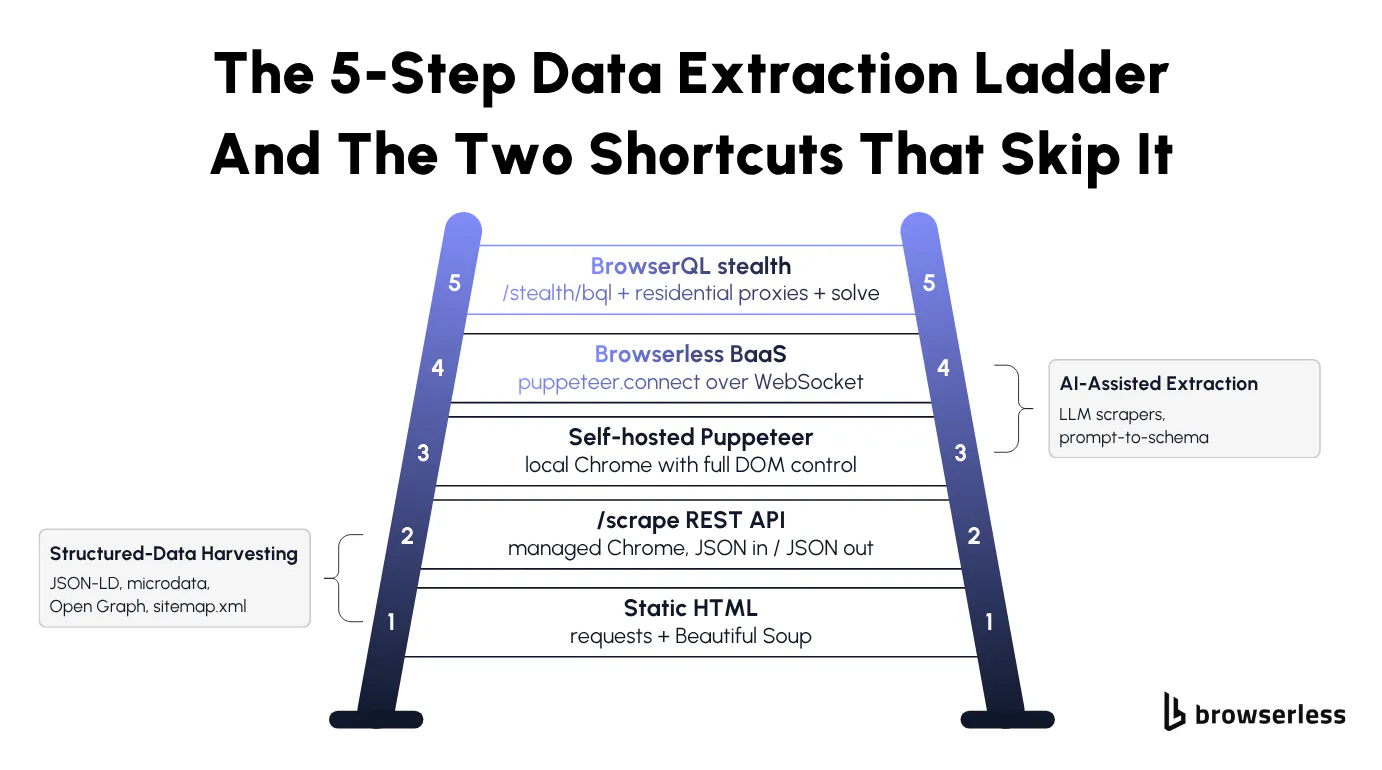
A ladder gives you a default order of attempts: try the cheapest tool first, escalate one step when it breaks, and don't skip two steps without a reason. Skipping costs you in proxy spend, code complexity, and detection surface area. The five steps are:
- Step 1.
requestsplus Beautiful Soup for static HTML. - Step 2. The Browserless
/scrapeREST API for rendered pages. - Step 3. Self-hosted Puppeteer or Playwright for full DOM control.
- Step 4. Browserless BaaS for parallel sessions and persisted state.
- Step 5. BrowserQL with stealth and residential proxies for protected sites.
Two shortcuts can short-circuit the ladder when the site cooperates: structured-data harvesting (JSON-LD, microdata, OpenGraph) for data the site already publishes for SEO, and AI-assisted extraction (LLM-driven prose-to-schema scrapers) for pages where selectors aren't worth the maintenance. If you don't want to pick a rung at all, the /smart-scrape endpoint runs the whole ladder in one call and tells you in the response which tier actually got the page. All three come later.
Static HTML data extraction with requests and the /scrape API
Data extraction from web pages starts with one GET request, an HTML parser, and a CSS selector. It works wherever "View Source" already shows the data. When client-side JS hides the fields, escalate to a managed render endpoint like /scrape.

Step 1: requests and Beautiful Soup for static pages
Static HTML extraction is the cheapest step on the ladder, requiring one GET request, an HTML parser, and a CSS selector. There's no headless Chrome to manage, no proxies to rotate, and the only cost is your own bandwidth, which makes it the cleanest starting point for data collection on server-rendered sites like blogs, documentation portals, public datasets, government data, and news archives.
Step 1 is the one step where Browserless isn't your default tool, since raw HTTP plus a parser is hard to beat on cost. If you want a managed alternative that reaches sites blocking plain requests, the /smart-scrape endpoint (covered later) ships a browser-shaped fingerprint at the cheap tier.
The snippet below targets books.toscrape.com, the canonical server-rendered scraping playground, and shows the whole step 1 loop end to end.
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
URL = "https://books.toscrape.com/catalogue/page-1.html"
response = requests.get(URL, timeout=15)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
books = soup.select("article.product_pod")
print(f"Found {len(books)} books on {URL}\n")
for book in books:
title = book.select_one("h3 a")["title"].strip()
price = book.select_one(".price_color").get_text(strip=True)
stock = book.select_one(".availability").get_text(strip=True)
print(f"- {title} | {price} | {stock}")
Three signals tell you step 1 is over.
- The
soupyou get back is empty even though the response was a200, or the body is a near-empty SPA shell with a JS bundle below it. - The fields you want aren't in the raw HTML but appear in the rendered page when you load it in Chrome.
- The response redirects to an anti-bot interstitial, or the data sits behind a login that needs cookies you can't set from a single
requests.get.
When any of these fire, the page is rendered client-side or session-gated, and clever workarounds will only buy you a week before something else breaks, so climb to step 2 where the /scrape endpoint takes over the rendering.
Step 2: the /scrape REST API for rendered pages
When step 1 signals fire, you have two cheap escalations available: spin up a headless Chrome yourself (step 3) or hand the rendering off to a managed REST endpoint, and step 2 is nearly always the smaller leap.
The /scrape endpoint accepts a JSON body containing a url and an elements array of CSS selectors, then loads the page, runs JS, waits up to 30 seconds for the selectors, and returns each element with its text, html, attributes, and bounding-box info.
It's selector-targeted, meaning you specify which CSS paths to pull and you get those elements back as JSON, whereas /smart-scrape returns full page content and auto-escalates from HTTP up to a stealth browser if needed.
Authentication is a ?token=YOUR_API_KEY query parameter on https://production-sfo.browserless.io/scrape, so any HTTP client hits it the same way, and step 2 trades a per-request fee for zero ops overhead.
Pointing /scrape at the JS-rendered version of the same demo site at quotes.toscrape.com/js, where a plain requests.get would return only the SPA shell, demonstrates the differential.
curl --request POST \
--url "https://production-sfo.browserless.io/scrape?token=YOUR_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"url": "https://quotes.toscrape.com/js/",
"elements": [
{ "selector": ".quote .text" },
{ "selector": ".quote .author" },
{ "selector": ".quote .tags" }
]
}'
The response groups results by selector. You get a top-level data array where each entry has the selector you asked for plus a results array with text, html, attributes, and bounding box info per match, ready to feed into your downstream pipeline.
Step 2 is over when one of these signals shows up.
- You need multi-step interaction (clicking a tab, scrolling into view, filling a form) before the data becomes visible.
- The page renders a different DOM under different conditions, so your selectors stay brittle no matter how you write them.
- The
resultsarrays come back empty even though the page works fine in Chrome, which points to a fingerprinting block that a managed REST call won't beat.
The first two signals point to step 3 and full programmatic browser control, while the third usually means skipping straight to step 5 – BrowserQL stealth is faster than fighting fingerprints with a vanilla browser.
Headless browser data extraction at scale
Headless browser data extraction runs Chrome under script control, so you can click, scroll, fill forms, and wait for network responses before pulling the DOM. Use Puppeteer or Playwright self-hosted at low volume, a managed BaaS pool when parallel sessions outgrow one machine.
Step 3: self-hosting Puppeteer or Playwright
When the page wants clicks, scrolls, form fills, or waits on a network response before data appears, REST scraping isn't expressive enough. You need a real browser to drive, which is what Puppeteer and Playwright give you.
Step 3 is the standard self-hosted setup, and the step Browserless was built to make optional. You install Puppeteer or Playwright locally, download a Chromium build, and run it on your laptop or in a container, which is free as far as the library goes but expensive everywhere around it (container size, RAM, continuous integration (CI) minutes, the engineer-hours spent debugging why Chromium won't start on Alpine).
Step 3 is where most teams hit pain before reaching for a managed service, since the API surface is identical to step 4 Browsers as a Service (BaaS v2).
Step 3 beats SPAs that hydrate after navigation, infinite-scroll pages, dashboards behind a login, and anything needing a sequence of actions before data appears. The demo target is quotes.toscrape.com/scroll, an infinite-scroll page that loads more quotes via AJAX every time you reach the bottom, so a static fetch returns only the first batch.
The step 3 script below boots Chromium locally, opens the scroll page, and scrolls until the quote count stops growing.
// npm install puppeteer
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://quotes.toscrape.com/scroll");
await page.waitForSelector(".quote");
// Scroll until the quote count stops growing, since the page lazy-loads via AJAX.
let previousCount = 0;
while (true) {
const currentCount = await page.$$eval(".quote", (nodes) => nodes.length);
if (currentCount === previousCount) break;
previousCount = currentCount;
await page.evaluate(() => window.scrollTo(0, document.body.scrollHeight));
await new Promise((resolve) => setTimeout(resolve, 1000));
}
const quotes = await page.$$eval(".quote", (nodes) =>
nodes.map((node) => ({
text: node.querySelector(".text")?.textContent?.trim() ?? "",
author: node.querySelector(".author")?.textContent?.trim() ?? "",
})),
);
console.log(`Scraped ${quotes.length} quotes`);
for (const quote of quotes) {
console.log(`- ${quote.author}: ${quote.text}`);
}
await browser.close();
})();
Self-hosting Chrome stops being fun the moment you try to scale it, and you'll know step 3 is over when you start hitting any of the following.
- Each Chrome session eats hundreds of MB to a gigabyte under load, and your laptop or container falls over the moment you try to run several in parallel.
- CI containers and AWS Lambda need Chromium plus a stack of system libraries (
libnss3,libatk-bridge,libgbm, and the rest), so your install diff balloons into a forty-line Dockerfile. - Cookies and login state evaporate between runs because there's nowhere durable to persist a session.
- Cold-start latency adds seconds to every job, which adds up fast on cron.
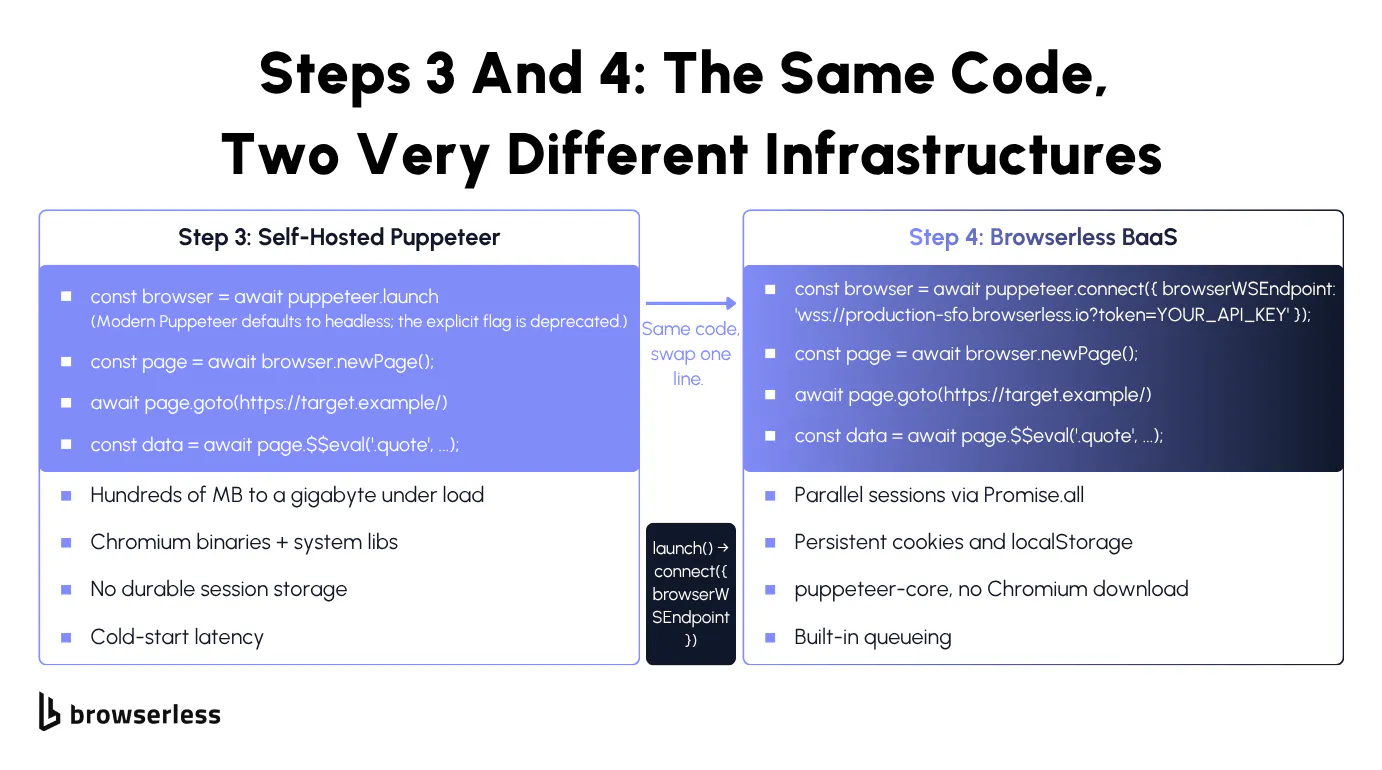
Once the bottleneck shifts from "what does my code do" to "how do I run a hundred Chrome processes reliably," it's time to stop running Chrome yourself and let step 4 take over, which is the same code with puppeteer.launch() swapped for puppeteer.connect().
Step 4: Browserless BaaS for automated extraction at scale
Step 4 keeps your Puppeteer or Playwright code intact and offloads the Chrome process to a managed pool, with a single-line diff from step 3. You swap puppeteer.launch() for puppeteer.connect({ browserWSEndpoint }) against wss://production-sfo.browserless.io?token=YOUR_API_KEY, or use chromium.connectOverCDP() on Playwright against the same WebSocket URL.
Install puppeteer-core instead of the full puppeteer so you don't pull a second Chromium you'll never launch, and always close pages and connections so the slot frees for the next job.
Parallel sessions now cost a Promise.all instead of a container fleet, and persistent state works by creating the session with POST /session (which accepts ttl for lifetime in ms and processKeepAlive for how long the browser stays warm between disconnects), so cookies and localStorage survive reconnects. Keeping the live process warm between disconnects is Puppeteer-only, since it relies on browser.disconnect(), which Playwright doesn't expose.
As cloud-based tools go, BaaS is the workhorse for production scraping, handling cron jobs, monitoring scripts, and internal data pipelines, with cost flipping from step 3's fixed infrastructure to per-session usage that stays predictable as data volumes grow.
The step 4 swap demonstrates parallelism via Promise.all against three paginated quote pages, with Browserless owning the Chrome processes. The same launch() → connect() line change carries over to step 3's scroll logic if you needed it here too.
// npm install puppeteer-core
const puppeteer = require("puppeteer-core");
// The only library change from step 3 is launch() to connect().
const BROWSER_WS_ENDPOINT = `wss://production-sfo.browserless.io?token=YOUR_API_KEY`;
const TARGETS = [
"https://quotes.toscrape.com/js/page/1/",
"https://quotes.toscrape.com/js/page/2/",
"https://quotes.toscrape.com/js/page/3/",
];
async function scrapePage(url) {
// Each task gets its own connection so they truly run in parallel.
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS_ENDPOINT,
});
const page = await browser.newPage();
await page.goto(url, { waitUntil: "networkidle2" });
await page.waitForSelector(".quote");
const quotes = await page.$$eval(".quote", (nodes) =>
nodes.map((node) => ({
text: node.querySelector(".text")?.textContent?.trim() ?? "",
author: node.querySelector(".author")?.textContent?.trim() ?? "",
})),
);
// Free the slot for the next job in the BaaS pool.
await browser.close();
return { url, quotes };
}
(async () => {
const results = await Promise.all(TARGETS.map(scrapePage));
for (const { url, quotes } of results) {
console.log(`\n${url} | ${quotes.length} quotes`);
for (const quote of quotes) {
console.log(` - ${quote.author}: ${quote.text}`);
}
}
})();
Step 4 is over when the site starts fighting back, with Cloudflare interstitials, Datadome challenges, JA3 fingerprint blocks, and Turnstile widgets that appear only when the request looks automated.
Before climbing to step 5, check whether CAPTCHA is the only blocker. If your fingerprint is fine and only a challenge widget gates the page, you can stay on the BaaS connection and add solveCaptchas=true to the WebSocket URL so Browserless solves CAPTCHA inline in the same Puppeteer or Playwright session without changing routes. The full step 5 climb is reserved for sites that detect the headless browser itself, not just the CAPTCHA.
Cloudflare-grade data extraction with BrowserQL stealth
Cloudflare-grade data extraction needs a hardened fingerprint, residential IPs, and an automatic challenge solver. BrowserQL on /stealth/bql applies fingerprint mitigations and entropy injection at the route level, paired with a solve mutation that clears Cloudflare Turnstile, reCAPTCHA, and hCaptcha.
Step 5: stealth routes and residential proxies
Step 5 is the route for sites that bounce a clean puppeteer.connect() request before your code even runs, which covers Cloudflare-protected portals, Datadome-guarded checkouts, ticketing platforms, and sneaker drops.
BrowserQL (BQL) exposes three routes for these cases: /chromium/bql (open-source Chromium with a minimal fingerprint surface, the recommended starting point), /chrome/bql (a genuine Chrome build for sites that detect Chromium specifically), and /stealth/bql (a privacy-hardened browser with fingerprint mitigations and entropy injection applied at the route level). The anti-detection techniques guide walks through what each layer does under the hood.
Residential proxies layer in via URL parameters, so a full endpoint looks like ?token=YOUR_API_KEY&proxy=residential&proxyCountry=us. Two gotchas: proxyCountry only applies when proxy=residential is set, and country codes are lowercase in URL params even though the BQL CountryType enum is uppercase inside mutations.
The proxySticky=true parameter asks the residential pool to hold the same IP across the session on a best-effort basis, so design any login-bound flow to re-auth if the IP shifts mid-session.
Step 5 continued: clearing CAPTCHA with the solve mutation
To clear an active challenge, use the solve mutation, which auto-detects reCAPTCHA, hCaptcha, or Cloudflare Turnstile without a type argument. Browserless flags solve as experimental in the docs but it's production-ready in practice.
A typical flow chains goto to load the page, then solve to clear whatever challenge appeared, then mapSelector or html to pull the data once the page settles.
Step 5 is the most expensive step on the ladder per request, but per engineer-month it's the cheapest at scale, since the stealth route absorbs exactly the failure modes (JA3 spoofing, CAPTCHA queues, residential IP rotation, fingerprint maintenance) that otherwise consume an engineer full-time.
The full step 5 stack fits into a single mutation that hits the stealth route through a US residential IP, calls solve to clear any challenge, and returns cleaned HTML.
# Stealth route + residential proxy (us).
# proxyCountry only applies when proxy=residential is set.
ENDPOINT="https://production-sfo.browserless.io/stealth/bql?token=YOUR_API_KEY&proxy=residential&proxyCountry=us"
read -r -d '' QUERY <<'GRAPHQL'
mutation ScrapeProtected {
goto(url: "https://nowsecure.nl", waitUntil: networkIdle) {
status
}
solve {
found
solved
time
}
html(
selector: "main, article, #content, body"
clean: { removeAttributes: true, removeNonTextNodes: true }
) {
html
}
}
GRAPHQL
# jq -n safely escapes the multi-line query as a JSON string body.
curl --request POST \
--url "$ENDPOINT" \
--header 'Content-Type: application/json' \
--data "$(jq -n --arg q "$QUERY" '{query: $q, operationName: "ScrapeProtected"}')"
If solve.found comes back false, that just means the page didn't show a challenge on that run. The cleaned HTML still gets returned from html, so your downstream parsing keeps working either way.
Data extraction shortcuts and the /smart-scrape elevator
Two shortcuts can skip the data extraction ladder entirely when the site cooperates. Structured-data harvesting (JSON-LD, microdata, OpenGraph) pulls data the site already publishes for SEO, and LLM-driven data extraction software extracts a schema from prose when selectors aren't worth maintaining. When neither shortcut fits, /smart-scrape is the cheap first call that handles most sites in one round-trip.
Shortcut 1: structured-data harvesting
Before climbing a single step, check whether the site already hands you the data. A surprising number do. Modern pages embed JSON-LD blocks (<script type="application/ld+json">) for SEO, microdata attributes (itemprop="..."), Open Graph tags, and sitemap.xml files, and the shortcut fits whenever the site wants search engines to find the data, which covers Schema.org Product markup on e-commerce pages, NewsArticle or BlogPosting on publishers, recipe sites, events, and job boards.
Always inspect the page source first. If JSON-LD already has the fields you need, you've cut the ladder to one HTTP call plus a JSON parse, and when it's sparse you fall back to the step that matches the page.
Shortcut 2: AI-assisted extraction
When the page structure changes weekly and the real cost is rewriting selectors every other Tuesday, LLM-driven scrapers extract a target schema from prose instead of CSS paths. You hand the model cleaned HTML or a screenshot, describe the schema you want, and get JSON back. Pairing the model with a real browser at the hard steps lets the LLM see a fully rendered DOM rather than an SPA shell, which beats brittle selectors when structure drift is your real problem. It's overkill on stable sites with clean selectors.
The elevator: /smart-scrape is the smart first call
/smart-scrape is a single REST endpoint that starts with a browser-fingerprinted HTTP fetch and falls back to a stealth browser when needed, so the cheap tier handles more sites than naive requests could.
Internally it walks four tiers in order:
- Fast HTTP fetch with a browser-shaped fingerprint.
- Proxied HTTP fetch via residential IPs if tier 1 is blocked.
- Headless stealth browser if the cheap tiers can't get a response.
- Stealth browser plus CAPTCHA solving for reCAPTCHA, hCaptcha, and Cloudflare Turnstile when a challenge is detected.
The response includes a strategy field naming which tier resolved the page (http-fetch, http-proxy, browser, or browser-captcha) and an attempted array listing every tier tried. If strategy comes back as http-fetch but content looks thin (an SPA shell, a few KB instead of the hundred-plus you'd expect), the site is JS-rendered or session-gated, so escalate to step 4 manually with the same token.
The formats array controls what comes back in one call. Asking for ["html", "markdown", "screenshot", "pdf", "links"] returns all of them, with markdown ready for LLM chunking, HTML for parsing, screenshots for vision models, PDFs for archival, and a deduplicated link array for crawl discovery.
A profile query parameter loads a persisted browser profile (cookies, localStorage, and IndexedDB) before navigating.
Running /smart-scrape against the static step 1 target returns strategy: "http-fetch" and the full rendered HTML.
curl --request POST \
--url "https://production-sfo.browserless.io/smart-scrape?token=YOUR_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"url": "https://books.toscrape.com/catalogue/page-1.html",
"formats": ["html", "markdown", "links"]
}'
The response comes back with ok: true, a content string holding the cleaned HTML, a markdown string ready to feed an LLM, an array of absolute links, and the strategy field showing which tier resolved the page.
Server-rendered sites resolve as http-fetch with payloads in the tens of KB. JS-rendered SPAs often still report http-fetch but with content that comes back as a near-empty shell, which is the signal to escalate to step 4 with puppeteer.connect() against the same token rather than treating it as a /smart-scrape failure.
Conclusion
Production data extraction is less about the latest tool and more about matching the step to the failure mode in front of you. Steps 2, 4, 5, and /smart-scrape all live on one Browserless account, so climbing the ladder doesn't mean wiring up a new vendor at each step. Find your current step, push it until it breaks, then sign up for free and try the next one.
Data extraction FAQs
Is data extraction the same as ETL?
ETL is one specific shape of data extraction, with a structured source system, strict schema, data warehouse destination, and contracts that don't shift mid-pipeline. Web data extraction is the messy sibling that pulls data out of HTML and network responses, where the schema is whatever you can scrape today and might change tomorrow. ETL teams reach for Fivetran, Airbyte, or dbt, while web teams reach for Puppeteer, Playwright, or Browserless.
How do I extract data from a website that uses JavaScript?
Raw HTTP doesn't run JavaScript, so the moment your requests call returns an SPA shell instead of rendered data, you've outgrown step 1. Use the /scrape endpoint at step 2 when you only need rendering plus selectors, or drive a real browser with Puppeteer or Playwright at step 3 (self-hosted) or step 4 (BaaS) when you need clicks, scrolls, or form fills before the data appears. The failure signal is always the same, with empty results despite a 200 response and the data clearly visible when you load the page in Chrome.
How do I extract data from a site behind Cloudflare?
Vanilla Puppeteer or Playwright leaks headless markers in the navigator object, telltale JA3 TLS fingerprints, and WebDriver flags that Cloudflare reads on the first request, and patching those leaks one by one becomes a treadmill that eats engineer-hours. Climbing to step 5 is the cleaner option, since BrowserQL on /stealth/bql with proxy=residential and the solve mutation handles Cloudflare, Datadome, and Turnstile without bespoke fingerprint code.
Which programming language is best for data extraction?
It depends on the step you're on rather than your personal preference. Python is cleanest at step 1, where requests plus Beautiful Soup pairs naturally with pandas downstream, while Node is cleanest at steps 3 and 4, where Puppeteer is first-class JavaScript. Steps 2 and 5 are HTTP and GraphQL endpoints, so they behave the same in any language and Python shops can stay in Python without switching to Node.
What's the simplest way to do automated data extraction at scale?
Skip the operations layer entirely and use a managed Chrome service you connect to with the library you already use, which means BaaS over WebSocket via puppeteer.connect or chromium.connectOverCDP for library users, or the Browserless REST APIs (/scrape for targeted selectors and /smart-scrape for full-page content with auto-escalation) for HTTP-only stacks. That's step 4 territory, and it's where most automated extraction at scale should live unless the target site forces you up to step 5.
How do you handle different types of data and protect data quality?
Three types of data show up in web extraction. Structured data lives in JSON-LD blocks and REST endpoints exposed inside the page, semi-structured data lives in HTML with consistent selectors, and unstructured data lives in free-form prose and screenshots where the schema changes every visit. Step 1 and the structured-data shortcut handle the first two on static pages, steps 3 to 5 handle semi-structured on JS-rendered pages, and AI-assisted extraction handles the unstructured tail. Data quality and data integrity sit downstream of the scrape, so reliable data extraction processes ship with error handling and access controls baked in, monitor schema and volume rather than just exit codes, and encrypt sensitive data at rest in the downstream store.