TL;DR
- Four detection layers. An anti-detect browser is a Chromium fork that patches JavaScript fingerprints and isolates profiles per persona. It covers the JavaScript layer cleanly but misses three more: the Transport Layer Security (TLS) handshake, HTTP/2 framing, and behavioral telemetry. TLS and HTTP/2 are scored before content is served; JavaScript fingerprints and behavioral telemetry are scored as the session runs.
- Coherence first. A Windows user agent paired with a Linux GPU is often more suspicious than no spoofing at all, and Cloudflare and other detectors weight impossible combinations heavily.
- Browserless covers the three gaps. The BrowserQL stealth route handles TLS and HTTP/2 framing by running real Chromium, residential proxies plus
proxyLocaleMatch=1align locale coherence, and the opt-inhumanlikeflag handles behavioral pacing.
Introduction
You can patch every JavaScript fingerprint surface an anti-detect browser covers (canvas, WebGL, navigator, user agent) and still get a 403 on the third request to a Cloudflare-protected target. The patches succeed at the only layer fingerprint checkers actually test, but they miss three layers Cloudflare scores in parallel. The TLS handshake completes before JavaScript runs, the HTTP/2 framing comes from the HTTP/2 client implementation, not from anything JavaScript can patch, and behavioral telemetry watches how the session unfolds. In this article, you'll see how Browserless closes each gap with its stealth route, residential proxies, and the opt-in humanlike flag.
What is an anti-detect browser?
Under the hood, an anti-detect browser (sometimes written "antidetect browser") is a Chromium fork with two things bolted on. It patches the fingerprintable browser parameters a website reads through JavaScript so each profile reports back different browser fingerprints, and it isolates cookies and storage per profile so multiple browser profiles can run side by side without giving away that they share a host.
Three things have to work together for that illusion to hold. Fingerprint spoofing patches the values JavaScript reads from navigator, screen, the canvas, WebGL, and the audio context, so each profile returns a different combination. Profile isolation gives each account its own separate browsing environment with cookies, storage, and history walled off. Proxy integration pairs each profile with a dedicated IP so the IP reputation lines up with the persona.
The category came out of multi-account management workflows on platforms that ban running multiple accounts from the same host. Common buyers run multi-account fleets on social media platforms and advertising platforms, mobile-fingerprint multi-accounting for app stores, web scraping jobs that need rotating personas, and cloud-phone fleets for short-form social.
Desktop vs. API
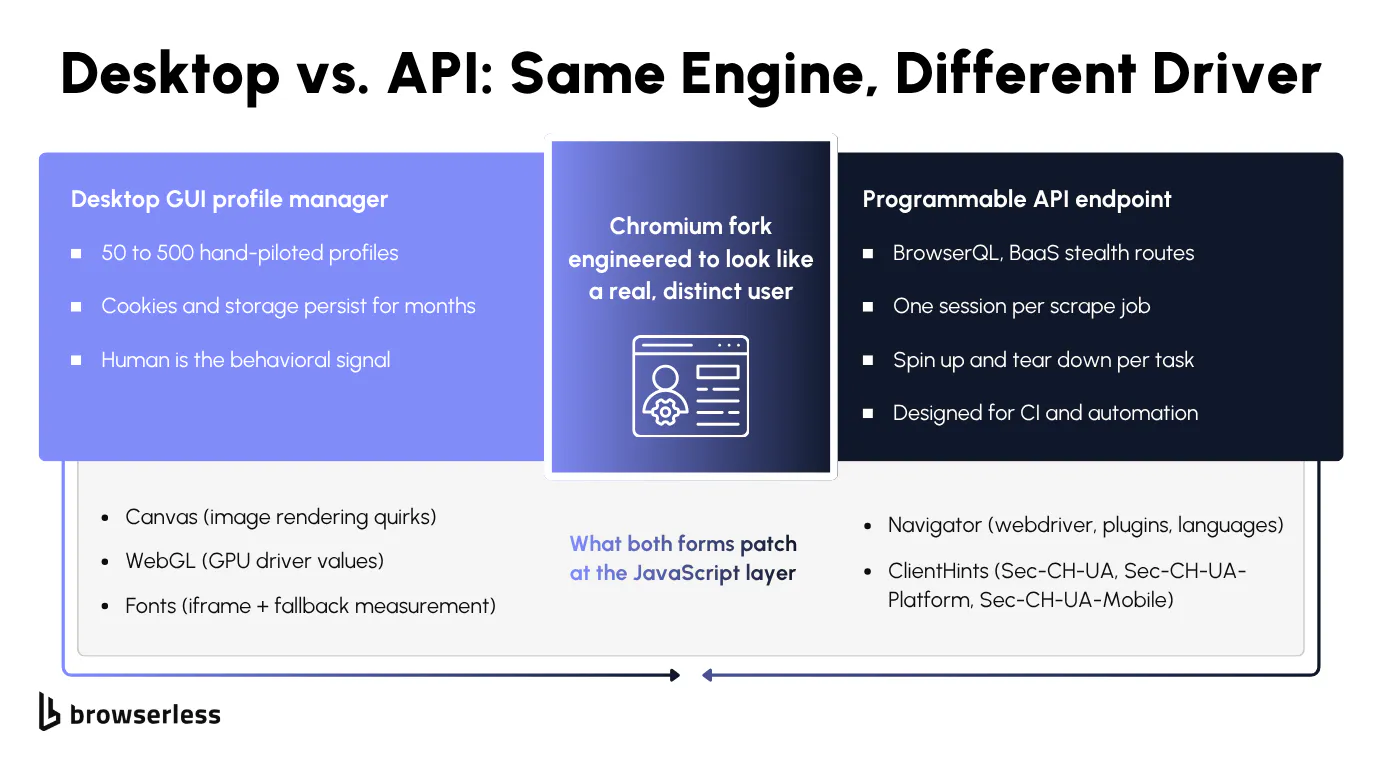
The same technology ships in two forms with different drivers. Desktop GUI products are profile managers with a user-friendly interface, where you launch the app, pick a saved persona, and a Chromium window opens with that fingerprint already swapped in. A human sits at the keyboard clicking around social media or advertising dashboards, with typical fleets running dozens to a few hundred profiles per operator and cloud sync so teammates can share account profiles across machines.
The API form drops the GUI entirely. You hit an endpoint over WebSocket or HTTP, the platform spins up a browser process tuned for stealth, your script drives the automation through Puppeteer or Playwright, and the session tears down when the job ends. No human in the loop, no saved persona between sessions. Browsers as a Service (BaaS v2) is Browserless's API form, with the /stealth route exposing a privacy-hardened browser variant tuned to strip the usual automation tells, accessed over a connection URL.
Affiliate marketers and agency operators reach for the GUI because they're working real accounts and want a window to drive. Developers running large-scale web scraping or end-to-end testing across thousands of URLs reach for the API. The rest of this article speaks to the developer.
The JavaScript layer every anti-detect browser patches
Every anti-detect browser patches the same JavaScript surfaces, and most of them do it well. That's the value the category brings, and it's also the trap most automation falls into. The patches matter because JavaScript fingerprinting is the most-tested layer (it's what every checker site reports on), and they're not enough because three other layers report on you before the page's JavaScript even runs.
Canvas, WebGL, and the rendering layer
Browser fingerprinting works on tiny rendering differences. The same image drawn on a MacBook comes out slightly different than on a Linux server, since the GPU and graphics drivers underneath aren't the same, and that difference is enough to give your machine a unique digital fingerprint that survives a cookie clear. The same trick works with audio (sites play a silent sound and measure how your OS processes it) and with fonts (sites measure text width to figure out which fonts you have installed).
A site that runs all three in parallel combines the result with the values JavaScript reports about your machine, and the resulting fingerprint is stable enough to recognize you across sessions, IPs, and even devices on the same hardware.
Beyond rendering, the browser hands over basic info through JavaScript, including the user agent string, the screen resolution, the installed plugins, the language and timezone, and the operating system. The newer Client Hints headers expose more (OS version, chip architecture) before any JavaScript runs.
A good anti-detect browser patches all of this so the site sees a consistent fake persona instead of your real machine. Coherence matters more than randomization. A profile with an impossible combination, like a mobile user agent paired with a desktop GPU or a US English locale paired with a Tokyo timezone, gets flagged faster than no spoofing at all.
Why PixelScan doesn't mean Cloudflare
A green check on PixelScan or CreepJS tells you your fake persona is internally consistent at the JavaScript layer, and that's all it tells you. Fingerprint checkers don't simulate the tracking systems Cloudflare and other anti-detection vendors actually run, so they say nothing about the TLS handshake your client made before JavaScript started, nothing about the shape of your HTTP/2 traffic, and nothing about whether your IP looks like a real human or a scraper hitting many pages a second.
The gap is obvious when you run a real test. A well-configured anti-detect browser passes bot.sannysoft.com cleanly, then the same configuration hits a challenge page or a 403 against nowsecure.nl before the script finishes loading. The fingerprint passed but the session still failed.
Three layers an anti-detect browser can't reach
Three detector layers live outside the browser process a desktop GUI controls. The TLS handshake happens in C++ before any JavaScript runs. HTTP/2 framing comes from the HTTP/2 client implementation, not from anything JavaScript can patch, and behavioral telemetry depends on whether a human is actually at the keyboard. Fixing any of them takes infrastructure rather than another fingerprint patch, which is what the next three sections walk through.
TLS fingerprinting (JA3, JA4)

Before any HTML moves, your client and the server do an HTTPS handshake, and that handshake is surprisingly chatty. Your client announces which encryption methods it supports, in a specific order, and that order alone is enough to identify which library opened the socket. Real Chrome opens the conversation one way; Python's requests, Go, curl, and every proxy library in between open it differently. Detection vendors hash those differences into a JA3 or JA4 fingerprint at the network edge, so by the time your request line is parsed, the bot score is already partly set.
A desktop GUI anti-detect browser can't fix this. The vendor doesn't run the network between your laptop and the destination, so whatever TLS library you opened the socket with is what shows up at the edge. JavaScript-layer stealth plugins can't touch it either, since the handshake completes in C++ before any JavaScript runs. The fix is to run the browser somewhere the handshake originates from real Chromium, which is what the BrowserQL stealth route does, a GraphQL endpoint at /stealth/bql you drive with mutations.
The cleanest way to see the gap is a side-by-side test against a TLS reflector (a server that tells you exactly what your handshake looked like). The curl below reads the fingerprint your local shell sends out, with no browser involved.
curl -sS "https://tls.peet.ws/api/all" \
| jq '{ja3: .tls.ja3_hash, ja4: .tls.ja4, ua: .user_agent}'
Now run the same request through Browserless. The mutation below tells managed Chromium to navigate to the reflector and read its JSON response back through text, so the JA3 hash and User-Agent are whatever a real Chrome browser would emit. The two outputs come back with distinct JA3 and JA4 fingerprints from the same target, visible at the reflector before either client has parsed a byte of HTML.
curl -sS -X POST \
"https://production-sfo.browserless.io/stealth/bql?token=${BROWSERLESS_API_KEY}" \
-H 'Content-Type: application/json' \
-d '{"query":"mutation { goto(url: \"https://tls.peet.ws/api/all\", waitUntil: networkIdle) { status } body: text(selector: \"body\") { text } }"}' \
| jq -r '.data.body.text' \
| jq '{ja3: .tls.ja3_hash, ja4: .tls.ja4, ua: .user_agent}'
HTTP/2 and proxy coherence
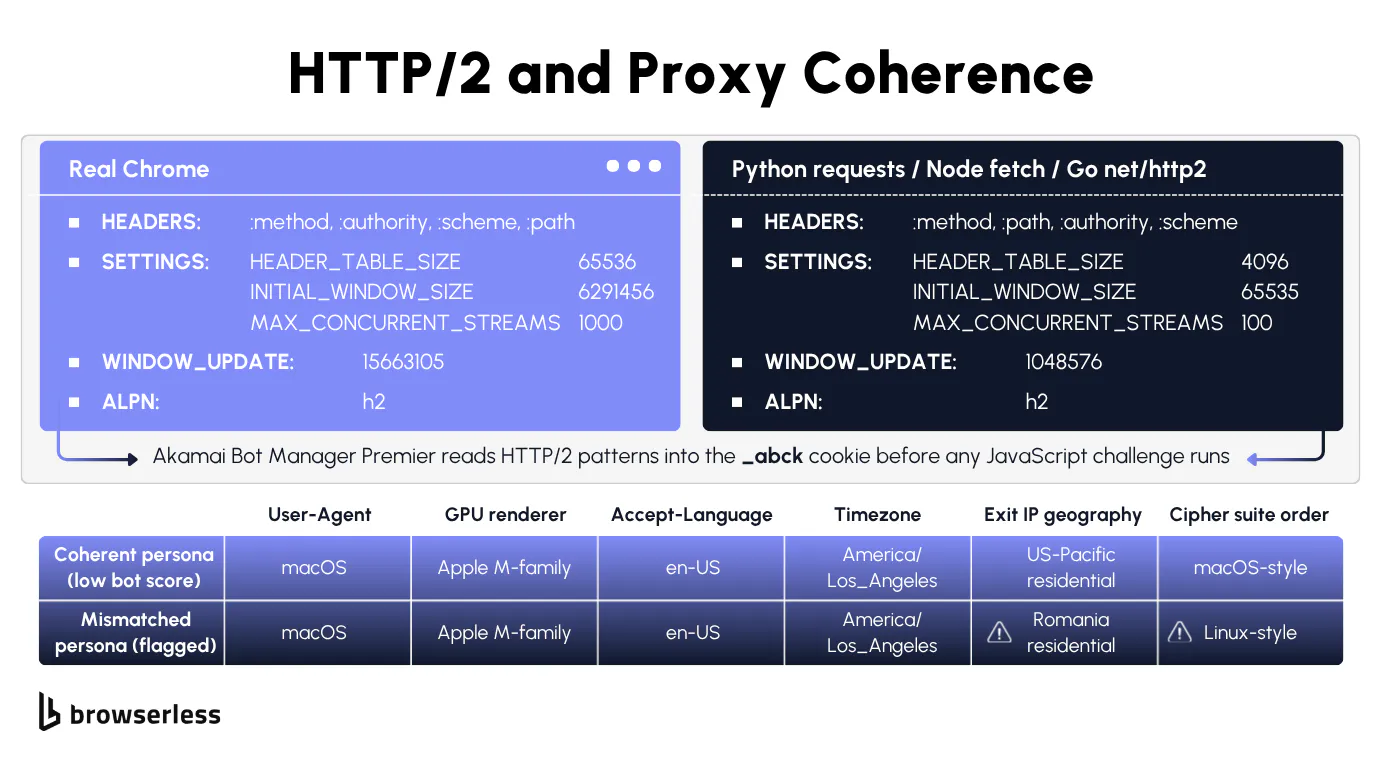
HTTP/2 fingerprinting picks up where TLS leaves off. Real Chrome sends pseudo-headers in :method :authority :scheme :path order, specific SETTINGS frame values, a WINDOW_UPDATE right after the handshake, and PRIORITY frames before the first request. Python's httpx and Go's net/http reorder those headers and skip priority frames entirely, and bot-management platforms hash the difference into your score before the server parses your request line. Browserless avoids this by running real Chromium under the /stealth/bql route, so the HTTP/2 frame profile is whatever real Chrome would emit.
Proxy coherence is the other piece a desktop GUI can't fix, and most desktop products leave proxy management as a separate concern entirely. A German residential IP paired with an English-US browser language and a New York timezone is impossible to defend, since no real device combines the three. Browserless collapses the alignment into connection-URL parameters. proxyLocaleMatch=1 auto-aligns the browser's language to whichever country the proxy is exiting from, proxy=residential&proxyCountry=de picks the exit IP, and proxySticky=true asks the network to keep that IP across the session when possible (best-effort, not guaranteed). Switching proxies mid-session breaks coherence even faster than getting it wrong on the first request.
The script below verifies the alignment by connecting through the residential proxy, hitting an IP reflector, and reading back the exit country, browser language, and timezone. When proxyLocaleMatch=1 is doing its job, a DE exit IP comes back with de-DE for navigator.language and the Accept-Language header, without you setting either in code.
const { chromium } = require("playwright-core");
(async () => {
const TOKEN = process.env.BROWSERLESS_API_KEY;
const wsEndpoint =
"wss://production-sfo.browserless.io/stealth" +
`?token=${TOKEN}` +
"&proxy=residential" +
"&proxyCountry=de" +
"&proxySticky=true" +
"&proxyLocaleMatch=1";
const browser = await chromium.connectOverCDP(wsEndpoint);
const context = browser.contexts()[0] ?? (await browser.newContext());
const page = context.pages()[0] ?? (await context.newPage());
await page.goto("https://ipinfo.io/json", { waitUntil: "domcontentloaded" });
const ipJson = JSON.parse(await page.locator("body").innerText());
const locale = await page.evaluate(() => navigator.language);
console.log("Exit IP: ", ipJson.ip);
console.log("Exit country: ", ipJson.country);
console.log("navigator.lang: ", locale);
await browser.close();
})();
Synthesizing behavior with the humanlike flag

Once you're past TLS and HTTP/2, detection starts watching how you actually behave. Bot-management platforms track the path your mouse traces before clicking, how your scroll wheel decelerates, which form field you focused first and for how long, and the rhythm of your keystrokes. A hand-piloted desktop GUI passes this layer naturally because a real human moves the mouse and types the password, but a script-driven session has no mouse or keyboard events at all (or events arriving at suspiciously even intervals), and calling page.type in Puppeteer fires keystrokes with no delay between them by default.
Underneath all of those signals, the way the script talks to the browser through the Chrome DevTools Protocol (CDP) leaves its own signature that JavaScript patches can't hide. BrowserQL closes both gaps with an opt-in humanlike flag. It's off in the default settings since most automation doesn't need it and the realistic timings slow sessions down. Turn it on (set humanlike: true in the launch payload, or toggle Human-like Behavior in the BQL IDE) and goto waits like a person reading, scroll slows down naturally, type spaces out keystrokes, and click approaches the target before pressing.
With humanlike on, the mutation below logs into a test form. The HTML response looks the same as a default run, but the .time field on each step now reports realistic per-character dwell times instead of the near-zero intervals a default CDP dispatch produces. That timing profile is what detectors actually hash.
mutation HumanlikeLogin {
goto(url: "https://the-internet.herokuapp.com/login", waitUntil: networkIdle) {
status
}
typeUsername: type(selector: "#username", text: "tomsmith") {
time
}
typePassword: type(selector: "#password", text: "SuperSecretPassword!") {
time
}
click(selector: "button[type='submit']", visible: true) {
time
}
flash: text(selector: "#flash", timeout: 10000) {
text
}
}
One mutation, end-to-end Cloudflare bypass
Three of the four detection layers come down to flags on the same Browserless connection URL. The TLS handshake closes with the /stealth/bql route. HTTP/2 framing is handled by routing traffic through real Chromium on Browserless infrastructure. Locale coherence is handled with residential proxies plus proxyLocaleMatch=1. Behavioral pacing closes with the opt-in humanlike flag in the launch payload.
CAPTCHA challenges that show up mid-session close with the solve mutation in BQL, or with solveCaptchas=true on the connection URL in a Puppeteer or Playwright session. Both cover Cloudflare Turnstile, reCAPTCHA, hCaptcha, and other challenge types.
Here's the full four-layer pass as one mutation. The proxy settings (TLS, HTTP/2, locale) ride on the connection URL. The mutation body navigates the page, runs solve to clear any Turnstile that pops up, and reads the body text back. To also cover the behavioral layer, set humanlike: true in the launch payload alongside the mutation.
mutation BypassCloudflare {
goto(url: "https://nowsecure.nl", waitUntil: networkIdle) {
status
}
solve(type: cloudflare) {
found
solved
time
}
bodyText: text(selector: "body", timeout: 10000) {
text
}
}
A successful run returns goto.status: 200, solve.found: true, solve.solved: true, and bodyText.text containing the protected content from behind the Turnstile gate. With humanlike: true set in the launch payload, the same call addresses all four detector layers, though humanlike is opt-in and slows the session, so leave it off when the behavioral score isn't the blocker.
Conclusion
Anti-detect browsers solve one layer of bot detection, but production targets read three more before serving content. Browserless closes the gap with the /stealth/bql route for the TLS handshake, residential proxies plus proxyLocaleMatch=1 for HTTP/2 and locale coherence, and an opt-in humanlike flag for behavioral pacing, all on the same connection URL. Sign up for a free trial and run a stealth session against the target that's blocking you today.
FAQs
How is an anti-detect browser different from running multiple Chrome profiles?
Chrome's built-in profiles separate cookies and history, but they share the same fingerprint (canvas hash, WebGL renderer, audio context, user agent), the same TLS handshake, and the same exit IP. A site that fingerprints visitors will treat all your Chrome profiles as the same machine. An anti-detect browser patches each profile to look like a different machine at the JavaScript layer, and pairs each profile with its own residential or mobile IP so the network layer matches too.
Are anti-detect browsers legal?
The software itself is legal in most jurisdictions. What you do with it determines the legal exposure. Buying limited-edition sneakers across ten accounts on a retailer that explicitly bans multi-accounting is a terms-of-service violation that may or may not have legal weight depending on the platform and your local law. Treat the browser as a tool, check the terms of service of the platforms you're targeting, and stay away from anything that requires impersonating identified crawlers or accessing data you aren't authorized to see.
How long does an anti-detect browser profile stay viable?
A profile's useful life depends more on the account behavior than the fingerprint patches. A profile that logs in from the same residential IP, runs a few sessions a day, and behaves like a human can stay viable for months. A profile that gets used for aggressive scraping, account-takeover attempts, or impossible-pattern activity (logging in from Berlin and Tokyo within an hour) burns within days. Rotate proxies thoughtfully, keep the fingerprint coherent across sessions, and avoid behavior that no real user produces.
What is the difference between an anti-detect browser and a VPN?
A VPN swaps your network identity and leaves your browser identity untouched. A site that fingerprints visitors still recognizes your machine across IP rotations because the canvas hash, the WebGL renderer, and the user agent all stay the same. An anti-detect browser does the opposite, swapping the browser identity but leaving the network alone. Most multi-account workflows need both, with the browser layer to fake who you are and the network layer to hide where you are.
Do free anti-detect browsers work?
A free version exists for most products in the category, and they patch the basic JavaScript surfaces well enough to pass fingerprint-checker sites. The free plan usually caps how many profiles you can save, restricts proxy integration, and skips the newer client-hint headers and WebGPU surfaces that 2026-aware detectors hash. Paid plans add advanced features like cloud sync across multiple devices, a larger proxy bundle, and a support team for account recovery.
How is BrowserQL different from a desktop anti-detect browser?
BrowserQL targets script-driven automation and scraping rather than human-driven multi-account workflows, which is what desktop anti-detect browsers are built for. The two cover different use cases, and BrowserQL covers three additional detection layers a desktop product can't reach. You drive sessions through GraphQL mutations against the /stealth/bql route on Browserless infrastructure, with TLS handled by the stealth route, HTTP/2 and locale coherence by proxyLocaleMatch=1 on the connection URL, and behavioral pacing by the opt-in humanlike flag in the launch payload.