In this article, we are going to completely automate the process of searching for a product on Google Shopping. Specifically, we are going to search for board games and scrape the Google Shopping results page for the product name and price. Below is a visual of what we are going to be targeting on the page.
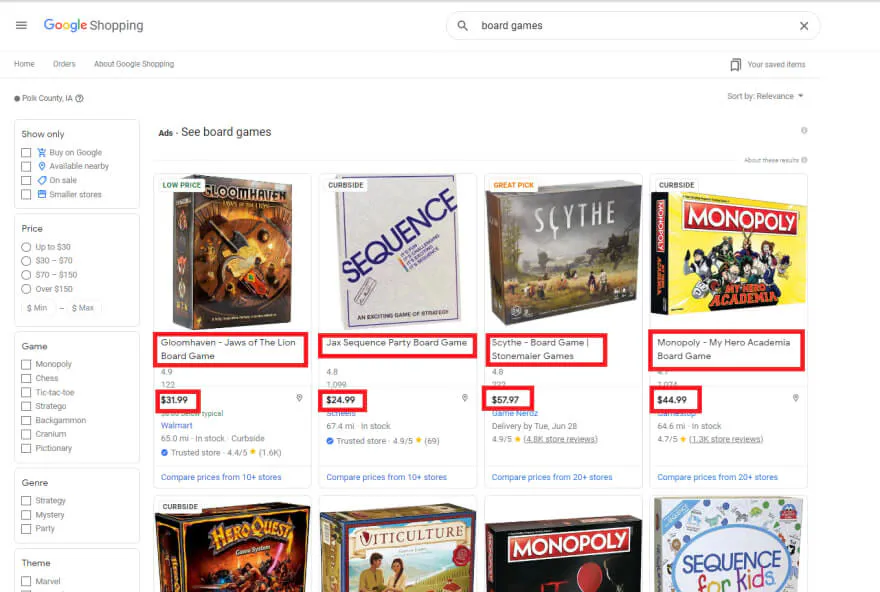
Here's the kicker, all we are going to use is one script and exactly 50 lines of code. How are we going to do this you may ask? The magic of JavaScript. Furthermore, a node library called Puppeteer and a web service called Browserless. If you don't know much about these tools I'd highly recommend you check them out further. They offer a lot of neat capabilities! We will go over some of them in this article.
For further info on Puppeteer, I'd encourage watching Eric Bidelman's talk at the Google I/O conference in 2018. Also, if you're hungry for more Browserless material after reading this article checkout the Browserless YouTube channel and the Browserless blog (for example, other web scraping tutorials: Glassdoor, YouTube & Twitter scraping guides). Both the channel and blog offer great tips and tricks to use in your Browserless and Puppeteer environments.
So let's dive deeper into Google Shopping scraper
Why Puppeteer?
Next, let's very quickly explain why we are using Puppeteer to accomplish our task of automating a Google Shopping search. First, Puppeteer provides a great high-level API to control Chrome (both headless and non-headless). Puppeteer is maintained by the Chrome DevTools team. These engineers know what they are doing. Lastly, most things you can do manually in the browser can be accomplished using Puppeteer. This will allow us to easily manipulate our script to perform the actions we want in the browser.
Initial setup
Alrighty, let's get to how to scrape Google Shopping results! We are going to start with the initial setup. Luckily for us, there aren't many dependencies we need to install. There's only one... Puppeteer.
Once you've run that command you are good to go! 👍
Browserless to scrape Google Shopping
Technically you are all set to start coding, but I want to use Browserless in tandem with Puppeteer. Why am I going to use this tool you're wondering? Let's get into that.
The script that we are going to be coding is one of many things that can be done with Puppeteer and headless Chrome. Let's say you want to run this script in one of your production applications, but you don't want to have to add Puppeteer as an extra dependency. What can you do? This is one scenario where Browserless comes to the rescue. With Browserless there is no need to install extra packages or dependencies, and it's compatible with Puppeteer. All you need to do is plug and play (We'll get more into the details of setting up Browserless below). This takes a huge load off of your application. You can test and run Puppeteer scripts in your dev environments and meanwhile run Browserless in your prod environments without having to worry about the extra baggage. Talk about a performance boost!
Another area where Browserless shines is in remote development environments (i.e. repl.it, gitpod, codepen, codespaces, etc.). Since there is no need to install any software you can easily hook up to the Browserless API and run your Puppeteer scripts in all your remote environments.
Before we get to the actual script, let's look at how to set up Browserless real quick.
For starters, you'll need to set up an account. Once you get your account set up, you'll be directed to your Browserless dashboard.
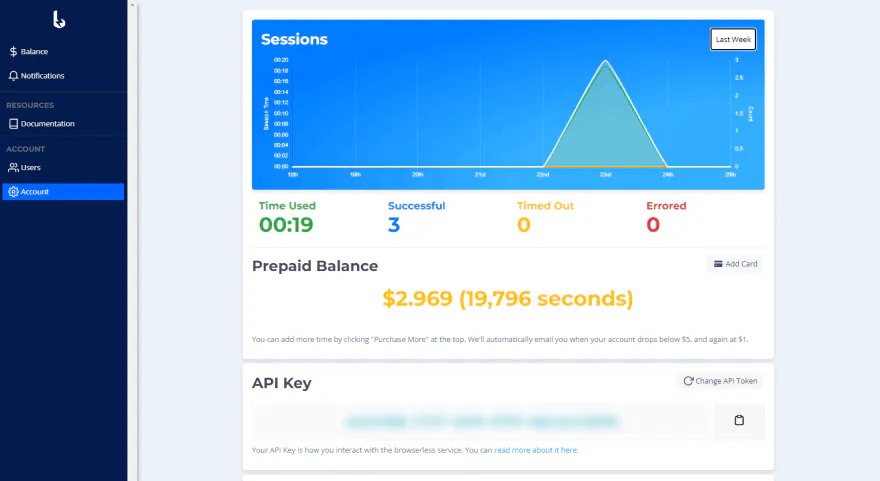
Here you can find your session usage chart, prepaid balance, API key, and all of the other account goodies.
Keep your API key handy as we'll use that once we start writing our script. Other than that we are ready to start coding!
Google Shopping scraper code
Ok now for the exciting part! I like to show the final product at the beginning and then dissect each piece from top to bottom. Here is our script:
const puppeteer = require("puppeteer");
const fs = require("fs");
const scrape = async () => {
try {
const browser = await puppeteer.launch({ headless: false });
// const browser = await puppeteer.connect({
// browserWSEndpoint:
// "wss://chrome.browserless.io?token=[ADD BROWSERLESS API TOKEN HERE]",
// });
const page = await browser.newPage();
await page.goto("https://shopping.google.com/");
await page.type("input[placeholder='What are you looking for?']", "board game");
await page.click("button[aria-label='Google Search']");
await page.waitForSelector("#pnnext");
// Go to next results page
await page.click("#pnnext");
await page.waitForSelector("#pnnext");
// Gather product title
const title = await page.$$eval("div.sh-dgr__grid-result h4", (nodes) =>
nodes.map((n) => n.innerText),
);
// Gather price
const price = await page.$$eval(
"div.sh-dgr__grid-result a.shntl div span span[aria-hidden='true'] span:nth-child(1)",
(nodes) => nodes.map((n) => n.innerText),
);
// Consolidate product search data
const googleShoppingSearchArray = title.slice(0, 10).map((value, index) => {
return {
title: title[index],
price: price[index],
};
});
const jsonData = JSON.stringify(googleShoppingSearchArray, null, 2);
fs.writeFileSync("googleShoppingSearchResults.json", jsonData);
// await browser.close();
} catch (err) {
console.error(err);
}
};
scrape();
Okie doke, let's dive into this. The first 2 lines are pulling in JavaScript modules. We'll want to pull in Puppeteer for obvious reasons. The second module is what we will use to export our scraped Google data to a JSON file.
const puppeteer = require("puppeteer");
const fs = require("fs");
The next section is the start of our actual scrape() function. At the very beginning of this arrow function, we hook up to the Browserless API using the API key you obtained from the Browserless dashboard.
const browser = await puppeteer.connect({
browserWSEndpoint:
"wss://chrome.browserless.io?token=[ADD BROWSERLESS API TOKEN HERE]",
});
Alternatively, you could replace this section of code with puppeteer.launch like so:
const browser = await puppeteer.launch({ headless: false });
This is good to do in your dev environment to test out the script. That will save your Browserless resources and help with debugging if there is any issue with your code. One thing I wanted to point out was the {headless: false} property that is being passed in. This tells Puppeteer to launch Chrome on the screen so you can visually see how the code is interacting with the webpage. Pretty cool to watch, and extra useful when building out scripts!
In the next section, we create a new browser page, navigate to Google Shopping's website, find the search bar, type in whatever we want to search for (in this case we are searching for a board game), click the search button, and finally waiting for the page to load. More specifically, waiting for the pagination at the bottom of the page to load. You'll see why in a minute.
const page = await browser.newPage();
await page.goto("https://shopping.google.com/");
await page.type("input[placeholder='What are you looking for?']", "board game");
await page.click("button[aria-label='Google Search']");
await page.waitForSelector("#pnnext");
This following section is kind of a bonus. What if you wanted to navigate a couple of pages deep into the search results? That is what we accomplish in the next code block.
Remember how we waited for the pagination to load in the last part of the code? In this section, we click on that "next page" button that we were waiting on. This will navigate our browser to the next page of board games.
await page.click("#pnnext");
await page.waitForSelector("#pnnext");
Alrighty, now to gather the data we want from the page! The following piece of code is what finds the product title and the price of the board game. I do want to add a little disclaimer here. When inspecting Google Shopping's search page, you'll notice their compiled code is a little convoluted. If these specific attributes aren't working for you, make sure to inspect the search results page yourself and find the HTML attributes that work for your scenario. This is where using that puppeteer.launch({ headless: false }) property can help.
// Gather product title
const title = await page.$$eval("div.sh-dgr__grid-result h4", (nodes) =>
nodes.map((n) => n.innerText),
);
// Gather price
const price = await page.$$eval(
"div.sh-dgr__grid-result a.shntl div span span[aria-hidden='true'] span:nth-child(1)",
(nodes) => nodes.map((n) => n.innerText),
);
Ok, so once we've gotten our product titles and prices it's time to consolidate our data. For this I'm only going to take the first 10 results I gathered.
// Consolidate product search data
const googleShoppingSearchArray = title.slice(0, 10).map((value, index) => {
return {
title: title[index],
price: price[index],
};
});
Lastly, we want to display or save our data. If you simply want to see what results get returned, you can console.log(googleShoppingSearchArray);. But let's say you want to export this data to a JSON file and maybe use that JSON to make a chart of the results. To save your data into a JSON file you'll use the code in our example.
const jsonData = JSON.stringify(googleShoppingSearchArray, null, 2);
fs.writeFileSync("googleShoppingSearchResults.json", jsonData);
I added extra parameters to the stringify method for formatting purposes. The last param is a space parameter.
And to finish off our script, we close the browser.
await browser.close();
Below is a visual display of what our script is doing in the browser.
As you can see, Puppeteer is a pretty cool API. Pair that with Browserless and you have a super scalable, web scraping, automation tool. Did this article spark an idea or thought? Let me know in the comments, or on Twitter at @tylerreicks. Happy coding ❤️!
P.S. If you like our this "Google Shopping scraper" tutorial, you can check out how our clients use Browserless for different use cases: